
Data architecture principles are the foundational guidelines that make sure your company’s data is usable, secure, and ultimately, valuable. Think of them less as rigid, technical rules and more as a constitution for your entire data ecosystem. They provide actionable insights that transform raw data into a strategic business asset.
What Are Data Architecture Principles?
Imagine you're designing a new city from the ground up. You wouldn't just start dropping houses and roads wherever they fit. Instead, you'd work from a master blueprint—a set of principles that dictates where to build residential zones (your data marts), industrial areas (data warehouses), and the highways connecting them all (data pipelines). This blueprint ensures the city is functional, scalable, and a good place to live.
Data architecture principles serve the exact same purpose for your organization's data. They are the high-level agreements and strategic decisions that guide how you acquire, store, manage, and use information. Following these principles ensures every new data project, application, or system fits into a cohesive and strategic whole, preventing the chaos and waste that plague so many data initiatives.
The Foundation For Business Strategy
Without these guiding principles, organizations often end up with a messy, disconnected patchwork of data silos. Different departments use different tools and standards, which inevitably leads to inconsistent and untrustworthy information. This makes it nearly impossible to get a clear, enterprise-wide view of business performance, a recipe for flawed decisions and missed opportunities.
A principled approach turns data management from a reactive, technical chore into a proactive business strategy. It’s about aligning technology decisions with core business objectives from the start.
Actionable Insight: Start by creating a "Data Principles Charter"—a simple, one-page document outlining 3-5 core principles agreed upon by both business and IT leaders. This charter becomes your north star for all future data-related decisions and investments.
Core Pillars Of Data Architecture
When you look at any effective data architecture, three fundamental ideas consistently show up: scalability, quality, and security.
- Scalability and Performance: Your architecture has to handle growing data volumes and increasing query complexity without buckling under the pressure. It’s about building for the future, not just for today's needs.
- Data Quality and Governance: The data must be accurate, consistent, and trustworthy. Governance establishes the rules of the road and the responsibilities needed to maintain this quality over time.
- Security and Compliance: Data must be protected at every stage of its lifecycle. This means clear rules for who can access what information, ensuring you meet all your regulatory requirements.
The infographic below illustrates how these core concepts form the top-level pillars of any robust data architecture.
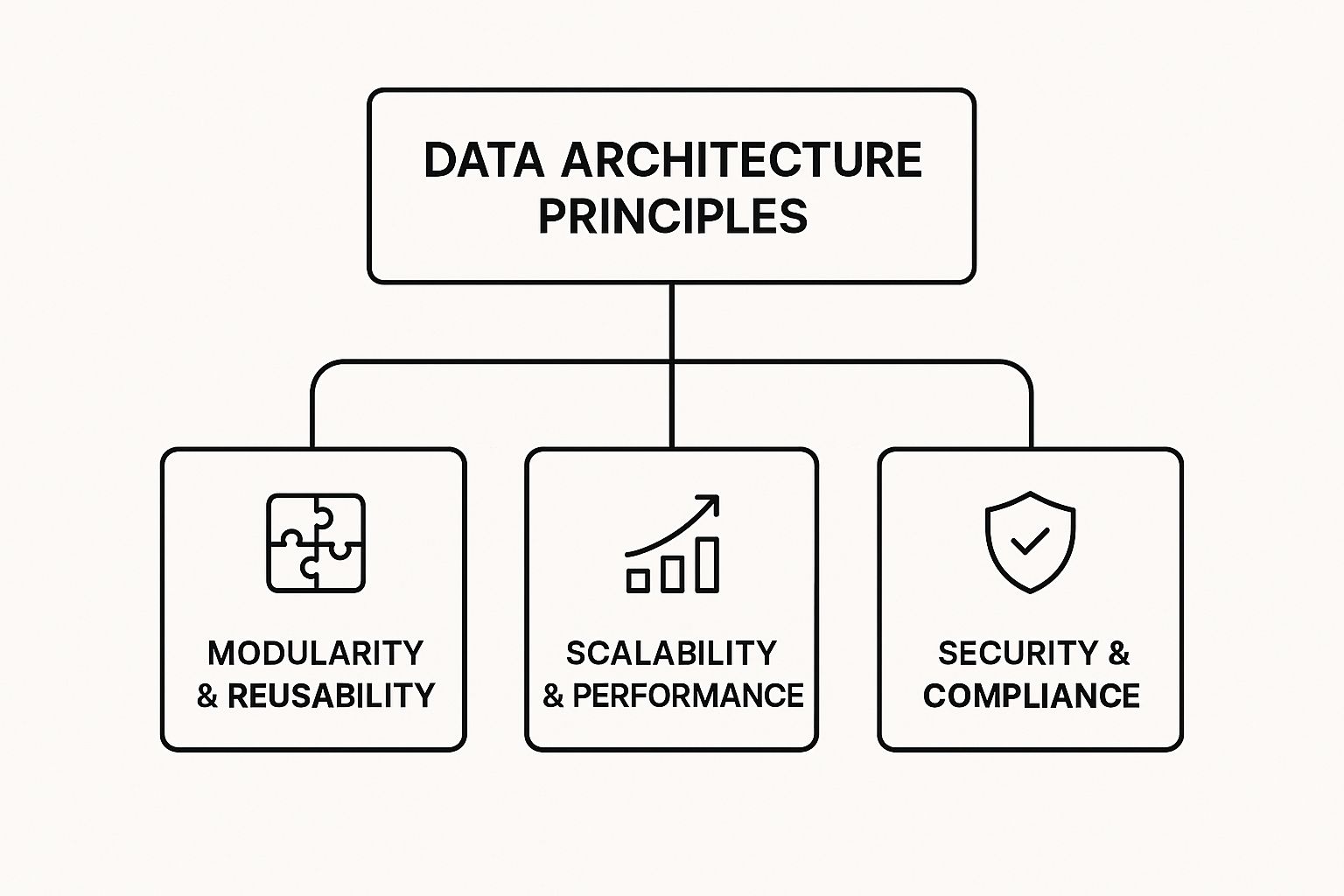
This hierarchy shows that major strategic goals like modularity, performance, and security are all direct outcomes of applying a principled approach.
To better understand how these pillars translate into practice, let's break down the core tenets that modern data teams live by. The table below summarizes these fundamental principles and their direct impact on the business.
Core Tenets of Modern Data Architecture
| Principle | Core Focus | Business Impact |
|---|---|---|
| Data as a Shared Asset | Treating data as a centrally managed, enterprise-wide resource rather than a departmental possession. | Breaks down silos, fosters cross-functional collaboration, and creates a single source of truth for decision-making. |
| Security by Design | Integrating security and privacy controls into the architecture from the very beginning, not as an afterthought. | Reduces risk of data breaches, ensures regulatory compliance (like GDPR & CCPA), and builds customer trust. |
| Common Vocabulary | Establishing standardized definitions, business glossaries, and data models across the organization. | Eliminates ambiguity, improves communication between teams, and ensures everyone is speaking the same data language. |
| Future-Proof Scalability | Designing systems that can elastically scale to accommodate future growth in data volume, velocity, and user demand. | Prevents performance bottlenecks, reduces the need for costly redesigns, and supports long-term business growth. |
| Separation of Concerns | Decoupling data storage from data processing to allow for independent scaling and technology choices. | Increases architectural flexibility, allows for using the best tool for each job, and avoids vendor lock-in. |
Ultimately, establishing these tenets is not just an IT exercise—it is a critical business function that directly impacts your ability to compete and innovate. As we'll explore in the next section, many of these core ideas have deep roots, evolving from foundational concepts in data management.
The Evolution of Modern Data Architectures

To really get a handle on today's data architecture principles, you first have to appreciate where they came from. The ideas driving modern data systems weren't born overnight. Instead, they’re the result of decades of problem-solving, with each breakthrough building on the last.
This journey shows us that core concepts like data integrity and minimizing redundancy aren't new at all—they’ve just been scaled up and adapted for bigger, more complex challenges.
Our story kicks off in the 1970s, a pivotal decade for data theory. Back then, data was a prisoner of the hardware and applications that created it. It was incredibly difficult to manage and almost impossible to share across different systems, which created massive inefficiencies. Getting a single, consistent view of business information was a constant struggle.
The Relational Revolution
Everything changed with the arrival of the relational model. It was a direct answer to the rigid, hierarchical systems that came before it, offering a much more flexible and logical way to organize information, completely separate from its physical storage.
The big moment came in 1970 when Edgar F. Codd published his work on a model based on set theory. His idea was simple but profound: organize data into tables (or "relations"). This masterstroke separated the logical data structure (the schema) from the physical storage, giving developers a huge boost in flexibility. A few years later, in 1976, Peter Chen introduced the Entity-Relationship (ER) model, which provided an intuitive way for designers to map out data structures from an application's point of view.
Practical Example: Let’s picture a mail-order business back in the 1970s. Without relational principles, its ordering system might have stored a customer's name and address with every single order they placed. If that customer moved, an employee would have to hunt down and manually update every individual order record. It was a recipe for mistakes and inconsistent data. The relational model fixed this mess by introducing separate tables for
CustomersandOrders, linking them with a unique ID. Now, if a customer’s address changed, you only had to update it in one place.
The Foundation of Modern Systems
This shift was monumental. For the first time, developers could think about what the data represented—like customers, orders, and products—instead of worrying about how the computer would physically store it on a disk. This principle of normalization—reducing redundancy to ensure data integrity—is a cornerstone of every modern database today.
These foundational concepts didn't just stay in the past; they evolved. The discipline required for relational models paved the way for the sophisticated data warehouses and pipelines that define a modern data architecture. Understanding this history helps you appreciate why principles like data consistency and integrity remain so critical.
Build for Scalability and Flexibility

One of the most important lessons in data architecture is to build for a future you can't fully predict. Scalability isn't just about handling more data volume. It's about designing a system that can gracefully adapt to new data types, unexpected sources, and evolving business questions without forcing you into a corner.
A rigid, monolithic system might seem efficient today, but it’s a time bomb. As your business grows and data pours in, that inflexible architecture becomes a major bottleneck. Innovation grinds to a halt because any small change requires a massive, costly overhaul. That's why building for change is non-negotiable from day one.
Design for Independent Growth
So, how do you build for both scale and flexibility? The answer lies in modular design. Instead of one giant, interconnected system, you build a collection of smaller, independent components that communicate with each other. This is the core philosophy behind a microservices-based approach to data processing.
With this model, each component—whether for data ingestion, transformation, or analytics—can be scaled, updated, or even replaced on its own. If your data ingestion needs suddenly triple, you can scale that specific service without disrupting your analytics engine. It’s like upgrading the engine in a car without having to replace the entire vehicle.
Actionable Insight: Avoid creating architectural dead-ends with proprietary technologies or rigid schemas that lead to vendor lock-in. Instead, prioritize standardized formats like Parquet or Avro and build with modular components. This ensures your architecture can evolve as your business does.
This modularity also maps beautifully to your organizational structure. Decentralized models like a Data Mesh empower individual teams to own their data as a product. This moves ownership closer to the experts who understand the data best, fostering accountability and agility across the organization.
A Practical Example of Scalability in Action
Let's imagine an e-commerce company. Their initial architecture is built to process structured sales data from their website—simple and effective. But then, the marketing team wants to analyze unstructured social media comments and semi-structured clickstream data to get a handle on customer sentiment.
-
A Rigid Architecture's Failure: A system designed only for neat, structured data would choke. The team would face a massive, slow, and expensive redesign project, losing out on timely insights in the process.
-
A Flexible Architecture's Success: An architecture with decoupled components could add a new microservice designed specifically to process unstructured text. This new module plugs right into the existing pipeline without disrupting the sales analytics workflows that are already running smoothly.
This adaptability is a hallmark of strong data architecture principles. You can find more strategies for achieving this kind of agility by exploring the relationship between cloud computing and data analytics, as cloud platforms provide the elastic resources needed to scale components up or down on demand.
Ultimately, designing for change ensures your data infrastructure remains a strategic asset, not a technical liability.
Prioritize Data Quality and Governance

You can build the most elegant, powerful, and scalable architecture imaginable, but it’s all for nothing if the data flowing through it is flawed. This leads us to one of the oldest and most enduring truths in the data world: garbage in, garbage out. Without a deep-seated commitment to data quality and governance, even the most sophisticated systems will churn out untrustworthy insights, eroding business confidence and leading to poor decisions.
It’s tempting to see data quality and governance as bureaucratic busywork, but that’s a dangerous misconception. Think of them as the essential guardrails that protect the integrity of your data. They are what transform raw information from a potential liability into a trusted, strategic asset.
Key Dimensions of Data Quality
At its heart, data quality is simple: is the data fit for its intended purpose? To answer that, we need to look at a few key dimensions. While there are many, three are absolutely critical for any organization.
- Accuracy: Does the data actually reflect the real-world thing or event it's supposed to describe?
- Completeness: Are there critical gaps or missing values that could skew our understanding?
- Consistency: Is the same piece of information represented uniformly across all our different systems and datasets?
Ignoring these dimensions isn't just a technical problem; it has real, tangible consequences that hit the bottom line.
Practical Example: The Cost of Inconsistent Data
Imagine a retail company with customer data spread across three systems: its e-commerce platform, a marketing automation tool, and the customer service database. In one system, a customer's address lists the state as "California," in another it's "CA," and in a third, it's "Cali." This simple inconsistency makes it impossible to get an accurate count of customers by state. The result? Skewed analytics, misguided regional marketing campaigns, and wasted ad spend.
Building Governance from the Start
To avoid these headaches, data governance can't be an afterthought—it has to be woven into the fabric of your architecture from day one. This proactive approach establishes clear ownership and sets firm standards, making quality a core practice instead of a clean-up job. The end goal is to create an environment where everyone, from the analyst to the CEO, can trust the data they’re using.
Actionable Insight: A great first step is establishing data stewardship roles. Assign individuals or teams to be owners of specific data domains (like customer or product data). They become the go-to experts responsible for defining quality rules and ensuring their data domain stays clean and reliable.
Another crucial move is creating a business glossary. This isn't just a dictionary; it's a shared language for the entire organization. It provides standardized definitions for key business terms and metrics, so when someone talks about "active users," everyone knows exactly what that means.
If you’re wondering where to begin, looking over a sample data governance policy can give you a solid framework for developing your own rules and procedures. By putting these governance measures in place early, you’re not just cleaning up data—you’re laying the foundation for a truly data-driven culture built on a bedrock of trust.
Embed Security by Design
In a strong data architecture, security isn't an afterthought—something you bolt on at the end like a new coat of paint. It needs to be woven into the very fabric of the design, right from the initial blueprint. Thinking about security as a foundational piece of your data architecture principles is always more effective, and far less costly, than trying to patch it onto a system that's already running.
This "security by design" approach means every single component, data pipeline, and storage layer is built with protection in mind. It completely reframes security from a reactive, threat-based chore into a proactive strategy for building a resilient and trustworthy data ecosystem. For any organization handling sensitive information, this mindset shift is absolutely critical.
Core Pillars of Data Security
To really nail security, you need to focus on a few core ideas that control who can access what and ensure data stays protected. These aren't just technical toggles in a system; they are the fundamental rules governing your entire data environment.
A few key security measures are non-negotiable:
- Role-Based Access Control (RBAC): This is a straightforward concept: people should only get access to the data they need to do their jobs. An analyst, for instance, will have very different permissions than a database administrator.
- Data Encryption: This is your data's armor. It protects information both when it's just sitting in storage (at rest) and when it's being moved between systems (in transit). Encryption scrambles the data, making it completely unreadable to anyone who isn't authorized to see it.
- Data Masking: This technique is perfect for development or testing. It hides sensitive information by replacing it with realistic but totally fake data. This way, your developers can work without ever being exposed to real, private customer details.
Actionable Insight: Always implement the principle of least privilege. It's a simple but incredibly powerful rule: every user, application, and system component should only be granted the absolute minimum level of access needed to perform its specific function. Nothing more, nothing less.
Practical Example: Security Zones in a Data Lake
Let's make this real. Imagine you're building a data lake for a healthcare provider. Instead of creating one giant, open pool of data, you would create distinct security zones, each with its own rules.
- Raw Zone: This is the most restricted area. It contains raw, unfiltered, and highly sensitive patient data. Access is locked down to only a handful of automated ingestion processes and a few authorized data engineers. All data here is encrypted at rest, no exceptions.
- Staging Zone: Here, the data gets cleaned and anonymized. Personally Identifiable Information (PII) is either masked or tokenized. Access is a bit broader but still limited to data science teams who need to prep the data for modeling.
- Analytics Zone: This final zone holds fully aggregated and anonymized data. It's much more accessible, allowing business analysts and researchers to run queries and gather insights without ever coming close to sensitive raw information.
This tiered structure embeds security directly into the data's lifecycle. It’s a perfect example of how sound data architecture principles can be applied to protect information at every single stage. In the same vein, strong security is a cornerstone of responsibly adopting new technologies, a topic we explore further in our guide to AI governance best practices.
Establish a Single Source of Truth
One of the most timeless data architecture principles is the mission to create a single, unified view of the business. When data is scattered across disconnected, siloed systems, you get a fractured picture of reality. This is where a single source of truth (SSoT) comes in—it’s the strategic answer to this chaos, ensuring everyone from the C-suite to the analyst team makes decisions based on the same consistent and reliable information.
This isn't some new, trendy concept. The idea really took hold with the rise of the data warehouse. It was a direct response to the crippling inefficiencies large companies faced when every department had its own way of extracting, cleaning, and reporting on data. The result was a mess of redundant work and conflicting reports. Data warehousing, first conceived by IBM researchers in the late 1980s, was designed to solve this exact problem by centralizing everything.
The Power of a Central Repository
Historically, the go-to tool for building an SSoT has been the data warehouse. Think of it as a central library for your most critical business data. Information from all over the company is gathered, cleaned up, standardized, and stored in a way that’s optimized for reporting and analysis. This entire process is typically managed by well-defined, automated data pipelines that keep the data flowing reliably into the warehouse.
The diagram below gives you a good visual of how this works. You can see various data sources feeding into one central warehouse, which then becomes the trusted source for all business intelligence and reporting tools.
This model shows data from different operational systems being pulled and integrated into one place. From there, users can access it for analysis, creating that coveted single source of truth.
A Practical Retail Example
Let’s make this real. Imagine a retail company selling products through three channels: its e-commerce website, physical stores, and a mobile app. Without an SSoT, answering a seemingly simple question like, "Who are our top 100 customers?" becomes a huge headache.
- The e-commerce team only sees online purchase history.
- The store operations team only sees in-store transactions.
- The mobile team only sees app-based activity.
Each team has a different, incomplete piece of the puzzle. But by creating a data warehouse, the company can stitch together sales data from all three channels into one complete view.
Actionable Insight: Even with the rise of modern architectures like data lakes and lakehouses, this core principle is as vital as ever. A cleansed, centralized, and governed repository for core business reporting is the bedrock of any solid data strategy. It provides the reliable foundation you need for analytics you can actually trust.
Now, analysts can finally get a true 360-degree view of their customers. They can identify who shops across multiple channels and understand their total value to the business—powerful insights that were completely invisible when the data was locked away in silos.
Got Questions? We've Got Answers
When you're digging into data architecture, a few common questions always seem to pop up. Let's tackle some of the most frequent ones to clear up the strategic and hands-on challenges you might face when applying solid data architecture principles.
What Is the Difference Between Data Architecture and Data Modeling?
This is a classic. The easiest way to think about it is scale. Imagine you're planning a city.
-
Data Architecture is the high-level city plan. It's the blueprint for the entire metropolis, defining the overall strategy for how data flows—how it's brought in, stored, kept safe, and managed across the whole organization. It’s all about the big picture: the technologies, the pipelines, and the governance that holds it all together.
-
Data Modeling is like the detailed architectural drawing for a single building in that city. It’s a much more focused process that maps out the specific structure and relationships for one dataset, like a customer database, designed to support a particular app or function.
A great data architecture provides the guiding principles for how individual data models are built, ensuring every "building" fits perfectly into the city plan.
How Do I Choose Between a Data Lake, Warehouse, and Mesh?
There’s no magic bullet here; the best choice really hinges on your specific needs, the kind of data you're working with, and how your organization is structured. It's less of a technical decision and more of a strategic one.
Practical Example: A retail bank needs standard daily reports on loan performance (perfect for a Data Warehouse). Its quantitative research team needs to analyze years of raw, unstructured market news feeds for algorithmic trading models (a great use case for a Data Lake). If the bank is massive and wants its retail, investment, and wealth management divisions to independently manage their own data analytics, it might explore a Data Mesh.
A Data Warehouse is your go-to for structured, cleansed data that feeds predictable business reports. If you're doing data science experiments with massive volumes of raw, messy data (both structured and unstructured), a Data Lake is a much better fit.
A Data Mesh, on the other hand, is a whole different beast. It's an organizational and technical approach built for large companies that want to decentralize data ownership, giving specific business domains control over their own data products. In reality, many modern strategies blend these concepts together.
Where Should a Small Business Start With Data Architecture?
The key is to start simple but always have an eye on growth. Don't over-engineer things from day one.
First, just focus on your most critical business data—think customer lists and sales figures. Second, pick a scalable, cloud-based database or warehouse that can easily expand as your business grows. Third, put some basic data quality rules in place right at the source to stop the classic "garbage in, garbage out" problem before it starts.
Actionable Insight: A really practical first step is to implement basic access controls from day one. Even when you're small, defining who can see and touch what data is a fundamental move. This builds a solid foundation for security and aligns with core principles found in guides on AI governance best practices, ensuring you're prepared for future growth.
At DATA-NIZANT, our goal is to demystify complex topics in data, AI, and digital infrastructure. We create in-depth articles to give you the actionable intelligence needed to make smart technology decisions. You can explore all of our insights at https://www.datanizant.com.

