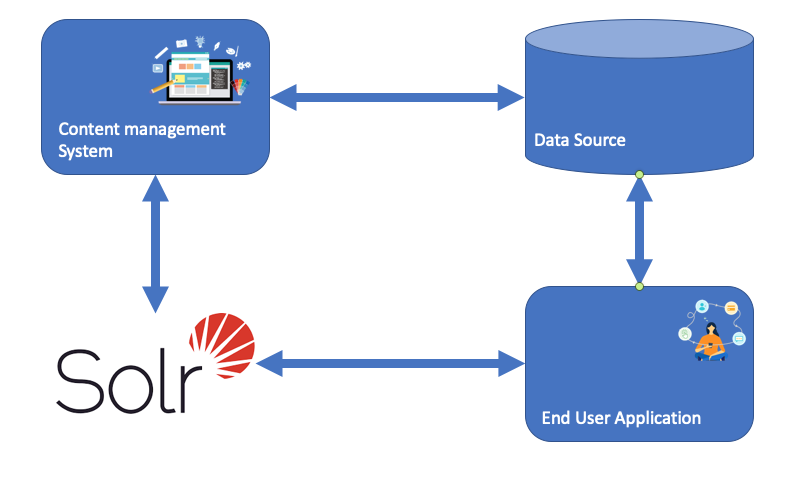
Introduction: A Decade of Big Data Blogging When I began writing about Big Data in 2013, it was an exciting new frontier in data management and analytics. My first blog, What’s So BIG About Big Data, introduced the core pillars of Big Data—the “4 Vs”: Volume, Velocity, Variety, and Veracity. As the years passed, I expanded into related topics with posts like Introduction to Hadoop, Hive, and HBase, Data Fabric and Data Mesh, and Introduction to Data Science with R & Python. Each blog marked the evolution of Big Data and reflected the shifting focus in the field as data…