
In machine learning, an epoch is one complete pass through your entire training dataset. Think of it like this: if you're a student trying to learn from a textbook, one epoch is finished the moment you've read the book from cover to cover exactly once.
But just like a student, a model rarely learns everything it needs from a single read-through. That’s why we train models for multiple epochs, giving them repeated chances to see the data and refine their understanding.
Demystifying the Core of Model Training
Let's stick with a practical example to really get this down. Imagine you're building a spam detector for an email service. Your training dataset has 10,000 emails, each labeled as 'spam' or 'not spam'. When your model has analyzed all 10,000 of those emails one time, it has completed one epoch.
During this pass, the model isn't just passively looking at the emails. It's actively trying to learn. It takes a small group of emails, makes a guess ("Is this spam?"), checks how wrong it was, and then slightly adjusts its internal logic to make a better guess next time. This cycle of guessing and adjusting happens over and over. An epoch is just the high-level counter telling us how many times the model has had an opportunity to learn from every single piece of data we've given it.
This iterative process is fundamental to how algorithms get smarter, whether in basic machine learning or more complex neural networks. For a closer look at how these ideas are applied in more advanced models, our guide on the differences between deep learning vs machine learning offers some great context.
Breaking Down the Terminology
It's really easy to get epochs mixed up with two other key terms: batches and iterations. They all work together, but they mean different things. Let's clear it up.
- Epoch: One full cycle through the entire training dataset.
- Batch: A smaller, more manageable chunk of the dataset. Instead of trying to process 10,000 emails all at once (which would eat up a ton of memory), you might break them into batches of 100 emails each.
- Iteration: A single update to the model's parameters. An iteration happens every time the model processes one batch of data.
So, if our spam detector dataset has 10,000 emails and we set a batch size of 100, then a single epoch will be made up of 100 iterations (because 10,000 total emails / 100 emails per batch = 100 iterations).
To make this crystal clear, here’s a quick comparison table.
Epochs vs Batches vs Iterations At a Glance
| Term | Definition | Practical Example (Spam Detector) |
|---|---|---|
| Epoch | One full pass through the entire dataset. | The model analyzes all 10,000 emails once. |
| Batch | A small subset of the dataset processed together. | The model analyzes a single group of 100 emails. |
| Iteration | A single update to the model's parameters. | The model updates its logic after analyzing one batch of 100 emails. |
This shows how each term represents a different level of granularity in the training process, from the smallest update (iteration) to the full sweep (epoch).
This concept map helps visualize how an epoch is really just a container for the entire training process, made up of many smaller steps.
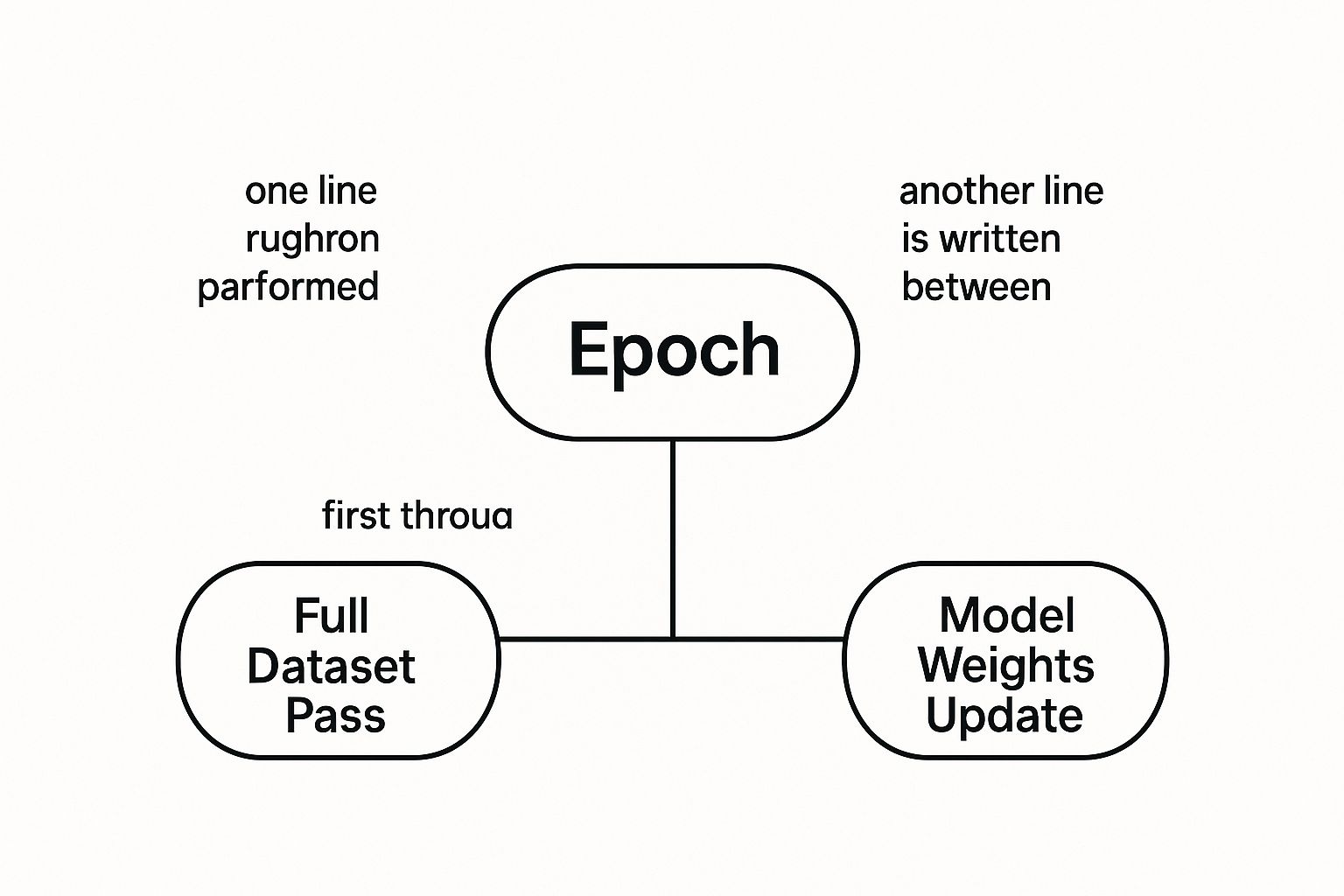
As you can see, the epoch is the big picture—a complete review of all the data. The model’s actual learning happens in smaller, incremental updates after each batch is processed.
How Epochs Power the Learning Process

It's tempting to think a machine learning model could learn everything it needs in one go, but a single pass over a dataset is almost never enough. Think about it: could a sculptor create a masterpiece with just one strike of the chisel? Of course not. A model can't grasp the complex, hidden relationships in data that quickly either.
Each epoch gives the model another chance to refine its understanding. It makes small, deliberate adjustments, inching closer and closer to an accurate representation of the data.
This learning happens through two key mechanisms working together: gradient descent and backpropagation. Gradient descent is like the model's roadmap to getting better. After looking at a batch of data and making a guess, it calculates how wrong it was—its error. Gradient descent then shows it which direction to adjust its internal parameters (the weights and biases) to shrink that error.
Backpropagation is the actual process of making those adjustments. It works backward from the error signal, tweaking each parameter just a little bit. This cycle happens for every single batch, and completing an epoch guarantees the model gets this corrective feedback from the entire dataset.
From Raw Marble to Refined Sculpture
The sculptor analogy is a perfect way to visualize this. Imagine the model starts as a raw block of marble, full of potential but completely undefined.
- Epoch 1: This is the first pass, where the sculptor makes big, rough cuts. The model learns the most obvious patterns, carving out a very basic shape. The error is still high, but the progress is huge.
- Intermediate Epochs: With each new pass, the sculptor switches to finer tools. The model starts making smaller, more precise adjustments, chipping away at imperfections and adding detail. It's learning the more subtle patterns it missed the first time around.
- Final Epochs: The last few passes are all about polishing. The model is making tiny, almost imperceptible tweaks to its parameters, smoothing out the last of the errors until the final, trained model emerges.
This iterative refinement is what makes epochs in machine learning so fundamental. Each pass lets the model build on what it learned before, systematically minimizing its error and uncovering deeper patterns that were invisible on the first try. This concept was really formalized back in the 1980s with the rise of neural networks, where an epoch came to represent one full cycle of this powerful learning loop.
Why More Passes Lead to Deeper Insights
Complex datasets are packed with non-linear relationships and subtle correlations that are impossible to capture instantly. For instance, high-quality data that has gone through robust feature engineering contains intricate signals that demand repeated exposure for the model to learn. You can see just how much well-structured data impacts training in our guide on feature engineering for machine learning.
Actionable Insight: Without multiple epochs, a model’s learning would be shallow and incomplete. The repetition is what allows the algorithm to converge on a solution, systematically reducing its loss and improving its predictive accuracy until it reaches its optimal state.
Finding the Sweet Spot Between Learning and Memorizing

Choosing the number of epochs in machine learning is where the rubber meets the road. It's a critical decision that can make or break your model's real-world performance. The whole point is to train a model that learns the general patterns in your data, not one that just memorizes every little detail.
Getting this balance right is everything. You're constantly walking a tightrope between two classic machine learning problems: underfitting and overfitting. Think of them as two extremes, and the number of epochs you choose is the main dial you turn to stay centered.
The Problem of Underfitting
Underfitting is what happens when your model doesn't train for long enough. It's like a student who only skims a textbook chapter once before a big exam. They might get the gist of it, but they’ll be stumped by any detailed questions because their understanding is just too shallow.
An underfit model is the same. It hasn't seen the data enough times to pick up on the important underlying patterns. The result? Poor performance on both the training data and any new data you show it. It was pulled out of class too early to get smart.
The tell-tale signs of underfitting are pretty clear:
- High Training Loss: The model is still making a lot of mistakes on the data it's supposed to be learning from.
- High Validation Loss: Unsurprisingly, its performance on new data is just as bad.
- Poor Generalization: The model just can't make accurate predictions in any useful scenario.
The Danger of Overfitting
Overfitting is the complete opposite problem, and it's a sneaky one. This happens when you let the model train for far too many epochs.
Imagine that same student, but this time they memorize every single question and answer from a practice exam. They can ace that specific test with a perfect score, but they'll completely fall apart when faced with a new problem that tests the actual concepts. They learned nothing, they only memorized.
An overfit model has done the same thing. It has effectively memorized the training data, including all its noise and random quirks. Its performance on the training set might look incredible—close to 100% accuracy! But the moment you introduce it to new data, it fails spectacularly.
This is a cornerstone concept in machine learning, deeply connected to the classic bias-variance tradeoff.
Actionable Insight: An overfit model is like a specialist with tunnel vision. It knows its specific training data inside and out but lacks the flexibility to adapt to anything new, rendering it ineffective for real-world applications.
To help visualize these two extremes, let's break down how the number of epochs influences your model's state.
Underfitting vs Overfitting An Epoch Perspective
This table compares underfitting and overfitting from the perspective of how many epochs you've trained your model for.
| Aspect | Underfitting (Too Few Epochs) | Optimal Fitting (Just Right) | Overfitting (Too Many Epochs) |
|---|---|---|---|
| Model State | The model is too simple and hasn't learned the underlying patterns. | The model has learned the general patterns without memorizing noise. | The model is too complex and has memorized the training data, including noise. |
| Training Performance | Poor. High loss and low accuracy on the training set. | Good. Low loss and high accuracy on the training set. | Excellent. Very low loss and near-perfect accuracy on the training set. |
| Validation Performance | Poor. High loss and low accuracy on unseen data. | Good. Low loss and high accuracy on unseen data. This is the goal. | Poor. Validation loss starts to increase after hitting a minimum point. |
| Actionable Insight | Increase the number of epochs. Let the model learn more. | Stop training at the point of lowest validation loss. This is your goal. | Decrease the number of epochs. Use techniques like early stopping to prevent this. |
Understanding this relationship is key to diagnosing and fixing your model during the training process.
Using Loss Curves as Your Guide
So how do you find that "Goldilocks zone"? You don't have to guess. The secret is to watch your model's training loss and validation loss curves like a hawk.
- Training Loss: This tells you how well the model is doing on the data it's seeing during training.
- Validation Loss: This measures the model's performance on a separate dataset it has never seen before.
As training begins, you should see both loss values go down. This is good; your model is learning.
But then comes the critical moment. If you see the training loss continuing to drop while the validation loss flattens out or, even worse, starts to creep back up—that's your red flag. That's overfitting in action. The point where the validation loss curve starts to turn upward is your signal to stop. The ideal number of epochs is right around that minimum point, ensuring your model is as good at generalizing as it can possibly be.
Actionable Strategies for Choosing Your Epoch Count

There’s no magic number for the perfect count of epochs in machine learning. It’s a common misconception for beginners to look for a universal answer. Instead, the real skill is developing a strategic approach that fits your specific model, data, and goals.
This entire process is a core part of hyperparameter tuning—an experimental, yet guided, search for the settings that squeeze the best performance out of your model.
Instead of just guessing, you can use intelligent techniques to zero in on that sweet spot for training duration. The most powerful tool in your arsenal is a method called early stopping. It completely automates the process of watching the validation loss curve we looked at earlier.
You just set a high initial epoch count and let the model train. The early stopping mechanism keeps an eye on the validation loss and automatically cuts the training short the moment performance on unseen data stops getting better. This not only prevents overfitting but also saves a ton of time and computational resources.
Factors That Influence Your Epoch Count
The right number of epochs isn't a static value; it changes depending on several connected factors. A model trained on a small, clean dataset might find its groove in just a few epochs. On the other hand, a complex deep learning model tackling a massive dataset could require hundreds or even thousands of passes.
Here are the main variables you need to think about:
- Model Complexity: A deep neural network with millions of parameters needs way more epochs to tune its weights than a simple linear regression model. More complexity simply means more repetition is needed to learn those intricate patterns.
- Dataset Size: Bigger datasets often need fewer epochs. Because each pass exposes the model to so much data, it gets a more stable and representative look at the patterns each time. Smaller datasets might need more epochs to avoid underfitting, but they also run the risk of overfitting much sooner.
- Dataset Diversity: If your dataset is packed with a wide variety of examples and tricky edge cases, the model will need more passes to learn how to generalize well across all those different scenarios.
Actionable Insight: Setting your epoch count is less about finding a perfect number from the start and more about establishing a framework for experimentation. The true skill lies in interpreting the feedback your model gives you and adjusting your strategy accordingly.
A Practical Approach to Setting Epochs
Since there's no one-size-fits-all answer, your best bet is to follow a structured, iterative process. Start with a reasonable baseline and then fine-tune it based on the evidence from your training runs. For certain models, like those used in time-series analysis, understanding data patterns is especially critical. You can see how different data structures affect training in our guide to implementing ARIMA in Python.
Here’s a practical, step-by-step method to guide your experiments:
- Start with a Large Number: Begin by setting a relatively high number of epochs, something like 100 or 500. This isn't your final number; it’s just a ceiling to make sure the model has plenty of runway to learn if it needs it.
- Implement Early Stopping: This is your most important tool. Configure it to monitor the validation loss and stop training after a set number of epochs with no improvement (this buffer is often called 'patience').
- Analyze the Results: Check where the training actually stopped. If it halted at epoch 25, you now have a solid clue that the optimal range is somewhere around there.
- Iterate and Refine: Use that insight for your next run. You might set your max epochs closer to 30-40 and start tweaking other hyperparameters, like the learning rate, to see if you can get even better results within that optimal window.
Implementing and Monitoring Epochs in Python
Okay, let's move from theory to practice. This is where the real learning happens, and thankfully, the most popular machine learning frameworks make it pretty easy to define and manage training epochs.
We'll walk through some practical, well-commented code for both TensorFlow/Keras and PyTorch. The goal isn't just to show you what to type, but to explain why you're typing it. This way, you can confidently take these ideas and apply them to your own projects.
Setting Epochs in TensorFlow and Keras
TensorFlow's high-level API, Keras, makes setting the epoch count almost trivial. It’s a single argument in the model.fit() method. Simple.
But the real magic comes from using callbacks—specifically, EarlyStopping. This nifty tool watches your model's performance on a validation set and automatically stops the training when things stop improving. It’s the best way to prevent overfitting without having to guess the perfect number of epochs.
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import EarlyStopping
# Assume X_train, y_train, X_val, y_val are pre-defined datasets
model = Sequential([
Dense(64, activation='relu', input_shape=(X_train.shape[1],)),
Dense(32, activation='relu'),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# Actionable Insight: Define the EarlyStopping callback
# 'monitor' tells it which metric to watch (validation loss)
# 'patience' is the number of epochs to wait with no improvement before stopping
early_stopping_monitor = EarlyStopping(monitor='val_loss', patience=10)
# Train the model with a high epoch ceiling, letting EarlyStopping find the optimum
history = model.fit(X_train, y_train,
epochs=100, # Set a high upper limit
validation_data=(X_val, y_val),
callbacks=[early_stopping_monitor]) # Add the callback here
In this snippet, we set a generous upper limit of 100 epochs. But we aren't just hoping for the best; we're letting the EarlyStopping callback do the heavy lifting. It will stop the training if the validation loss (val_loss) doesn't get better for 10 straight epochs.
Monitoring Epochs in PyTorch
PyTorch gives you a more hands-on, flexible experience. You build the training loop yourself with a standard Python for loop, which means you have total control over every single step of the process.
Implementing early stopping here requires a bit more custom code, but the logic is identical. You'll need to keep track of the best validation loss seen so far and use a counter to manage the "patience" part.
As you start writing more complex training loops, keeping your code clean becomes critical. Following good Python documentation best practices will make your life much easier, especially when you come back to a project weeks later.
Actionable Insight: By actively monitoring performance metrics during training, you shift from guessing the right number of epochs to making a data-driven decision. This is a fundamental step toward building robust and reliable models.
This hands-on approach is a core part of the broader discipline of model evaluation. For a much deeper look into this, check out our guide on machine learning model monitoring, which covers how to keep an eye on your model's health long after training is finished.
Ultimately, whether you choose the convenience of Keras or the flexibility of PyTorch, both give you the tools you need to manage epochs intelligently and build truly high-performing models.
Frequently Asked Questions About Epochs
As you start working more with epochs in machine learning, a few common questions always seem to pop up. Let's tackle them head-on to clear up any confusion and help you build better models.
Can a Model Be Trained in Just One Epoch?
Technically, yes, you can train a model for a single epoch, but it's almost never a good idea. One pass over the data is rarely enough for a model to learn the complex, underlying patterns, which usually results in underfitting.
Think of it like trying to learn a new language by reading through a dictionary just once. You might pick up a few words, but you won't grasp the grammar, nuances, or how to actually form sentences. Models need that repeated exposure to truly learn.
Is There a Perfect Number of Epochs to Use?
Nope, there's no magic number here. The ideal count is completely dependent on your specific project, from your model's complexity to the size and nature of your dataset.
A small, simple dataset might converge nicely in just 10-20 epochs. On the other hand, a massive, complex model training on millions of images could easily need hundreds of passes. The best strategy is always to monitor your validation loss and use techniques like early stopping to find that sweet spot for your unique situation.
Do More Epochs Always Lead to a Better Model?
Definitely not. While more training time can help a model learn, you'll eventually hit a point of diminishing returns. After a certain number of epochs, the model might start to overfit—it begins memorizing the training data instead of learning the general patterns you want it to.
This is a critical concept to internalize: training for too long can actively harm your model's ability to perform on new, unseen data. The whole goal is generalization, not memorization. Your validation loss curve is your best friend for spotting when performance stops improving and overfitting is about to kick in.
How Does Batch Size Affect the Number of Epochs?
Batch size and epochs are deeply connected. If you use a smaller batch size, the model's weights get updated more frequently within a single epoch. This can sometimes lead to faster convergence, meaning you might need fewer total epochs to get where you need to go.
Conversely, a larger batch size gives you a more stable gradient estimate but with far fewer updates per epoch. As a result, you might need to run more epochs to achieve the same level of performance. This relationship is a classic balancing act, much like the one we explore in our article on the bias-variance tradeoff.
At DATA-NIZANT, we break down complex topics into clear, actionable insights. Explore our in-depth articles on AI, data science, and machine learning to stay ahead. https://www.datanizant.com

