
If you're trying to get your head around the world of AI, you’ve likely heard the terms Machine Learning and Deep Learning thrown around, sometimes interchangeably. While they're related, they aren't the same thing, and knowing the difference is key to understanding what's really happening under the hood.
The simplest way to think about it is this: Machine Learning is the broader field where models need a human expert to guide them, helping them find patterns in data. Deep Learning, on the other hand, is a specialized subfield where the models can figure out those patterns all on their own.
Actionable Insight: If you have structured data (like a spreadsheet of customer sales) and need a quick, explainable prediction, start with traditional Machine Learning. If you have unstructured data (like thousands of product images) and accuracy is your top priority, Deep Learning is likely the better tool.
Understanding The Core Concepts
To really grasp the deep learning vs machine learning distinction, it helps to see their relationship visually. Artificial Intelligence (AI) is the big umbrella—the whole science of making machines smart. Machine Learning (ML) is a major branch of AI that uses algorithms to learn from data and make predictions. And nestled inside ML is Deep Learning (DL), a specific and powerful technique that relies on complex structures called neural networks.
This diagram perfectly illustrates the hierarchy:
So, all deep learning is machine learning, but not all machine learning is deep learning. The fundamental split between them really comes down to how they handle data features.
The Role of Feature Engineering
The biggest practical difference you'll encounter is feature engineering. With traditional machine learning, a data scientist has to roll up their sleeves and manually select, clean, and transform the most important variables—the "features"—from raw data. This is a painstaking process that demands serious domain expertise. You have to know what you're looking for before you even start.
Practical Example: To predict customer churn with a traditional ML model, you'd manually create features like 'average monthly spend,' 'number of support tickets,' and 'days since last purchase.' You are telling the model exactly what to look for. A deep learning model, given raw customer activity logs, would learn to identify these predictive patterns on its own.
Deep learning models completely automate this step. Their layered neural networks can independently identify and extract features directly from the raw input, like pixels in an image or words in a document. This ability to learn in a hierarchical way is what makes them so powerful.
Of course, this self-sufficiency comes at a cost. Traditional ML models can work quite well with moderately sized datasets—think 50 to 100 data points per feature. Deep learning, because it has to learn everything from scratch, is data-hungry. It often needs thousands, if not millions, of data points and requires significantly more computational power (hello, GPUs!) to train effectively.
Core Differences at a Glance
For a quick side-by-side, here’s how the two approaches stack up.
| Feature | Machine Learning (ML) | Deep Learning (DL) |
|---|---|---|
| Human Role | Requires manual feature engineering and model tuning. | Minimal human intervention after the initial setup. |
| Data Requirement | Works well with small to medium datasets. | Needs massive datasets to perform effectively. |
| Core Architecture | Uses algorithms like decision trees, SVM, & regression. | Uses multi-layered Artificial Neural Networks (ANNs). |
| Training Time | Relatively fast on standard CPUs. | Can take days or weeks, often requires GPUs/TPUs. |
Getting these distinctions down is the first real step toward achieving machine learning mastery and knowing which tool to pull out of your toolkit for the right job.
Comparing Model Architecture and Training Requirements
To really get to the bottom of the deep learning vs machine learning debate, you have to look under the hood at their core mechanics. The way these models are built and trained is what determines everything that follows—the kind of data they need, the hardware they run on, and just how much hands-on human effort is required. This is where the practical differences really start to pop.

Machine Learning Algorithms and Their Structure
Traditional machine learning works with algorithms that are relatively straightforward and easy to interpret. Think of models like Decision Trees or Support Vector Machines (SVMs). A Decision Tree, for example, makes its predictions by running through a series of if-then-else questions, almost like a flowchart. You can literally trace its logic, which makes it easy to visualize and explain.
An SVM operates a bit differently, finding an optimal hyperplane—which is just a fancy term for a dividing line or plane—that best separates data points into different categories. These models are certainly powerful, but their success is almost entirely dependent on the quality of the input data. They demand structured, labeled data that has been meticulously prepared through a process called feature engineering.
Deep Learning and Artificial Neural Networks
Deep learning flips the script with its Artificial Neural Networks (ANNs). Drawing inspiration from the human brain, an ANN is built from interconnected layers of "neurons" or nodes. Each layer in the network learns to spot specific features, and these layers are stacked together to create a "deep" network.
This layered architecture is the secret sauce behind deep learning's power. It gives the model the ability to perform automatic feature extraction directly from raw, unstructured data.
- Convolutional Neural Networks (CNNs) are the undisputed masters of visual data. In its first layer, a CNN might learn to recognize simple edges and colors. The next layer might combine those to identify shapes, and layers after that could start recognizing complex objects like faces or cars.
- Recurrent Neural Networks (RNNs) are built for sequential data, like text or time-series information. They have a kind of memory that lets them use past information to influence the current output, making them perfect for tasks like language translation or predicting stock prices.
Actionable Insight: With machine learning models, you're the architect, hand-crafting the features yourself. With deep learning models, you're more of a project manager, defining the architecture and letting the model build the feature hierarchies from raw data. Your role shifts from feature engineering to architecture design and hyperparameter tuning.
The Great Divide in Training Requirements
This split in architecture naturally leads to huge differences in training needs, and this is often the most critical factor when you're planning a project. The decision between using a CPU or a GPU, working with small data versus big data, or having a model that trains fast versus slow—it all starts here.
To paint a clearer picture, let's look at the key technical differences side-by-side.
Here’s a breakdown of the core technical characteristics that separate traditional Machine Learning from Deep Learning. This table highlights how their fundamental differences in architecture drive everything from data and hardware needs to training time and interpretability.
Machine Learning vs Deep Learning Key Technical Differences
| Attribute | Machine Learning (ML) | Deep Learning (DL) |
|---|---|---|
| Model Architecture | Simpler algorithms like Decision Trees, SVMs, Linear Regression. Structure is often transparent. | Complex, multi-layered Artificial Neural Networks (ANNs) such as CNNs and RNNs. |
| Data Requirements | Performs well on small to medium-sized structured datasets (e.g., spreadsheets, databases). | Requires massive datasets, often millions of examples, to train effectively. Excels with unstructured data (images, text, audio). |
| Hardware Needs | Can be trained efficiently on a standard CPU (Central Processing Unit). | Demands high-performance hardware, almost always requiring a GPU (Graphics Processing Unit) or TPU to handle parallel computations. |
| Feature Engineering | Manual process. Requires a data scientist to manually select, extract, and transform relevant features from the data. | Automatic process. The neural network learns the feature hierarchy on its own, directly from the raw data. |
| Training Time | Relatively fast. Models can often be trained in minutes or hours. | Extremely time-intensive. Training can take days, weeks, or even months depending on model complexity and dataset size. |
| Interpretability | Generally considered a 'white box'. The decision-making process is transparent and easy to understand and explain. | Often called a 'black box'. The internal decision-making logic is highly complex and difficult to interpret directly. |
This table lays bare the trade-offs involved. While deep learning offers incredible power, it comes at the cost of higher requirements for data, hardware, and time, along with a significant challenge in interpretability.
As we often discuss in our posts on machine learning in marketing, the interpretability of a classic ML model can be a massive win in business environments. In those settings, explaining why a prediction was made is often just as important as the prediction itself. This constant tug-of-war between raw performance and clear explainability is a central theme in the deep learning vs machine learning comparison.
When to Choose Machine Learning for Better Results
Deep learning gets a lot of the spotlight, but in the real world, it’s not always the right tool. Knowing when to stick with a more traditional machine learning approach is a critical skill, and the decision in the deep learning vs. machine learning debate often boils down to your project's specific needs and constraints.
Traditional machine learning truly shines when you need speed, clarity, and efficiency, particularly when resources are limited. If you're working with a structured, smaller dataset, classic algorithms like Decision Trees or gradient boosting models often deliver fantastic performance without the massive overhead of a deep neural network.
The Power of Interpretability and Speed
In many business or scientific settings, understanding why a model made a particular prediction is just as important as the prediction itself. This is where traditional machine learning holds a major advantage.
- Explainable Results: ML models are often called "white box" models because their inner workings are transparent. You can trace the decision path of a tree-based model or look at the coefficients of a linear regression to see exactly which features are driving an outcome.
- Regulatory Compliance: In highly regulated industries like finance and healthcare, model explainability isn't just a bonus; it's a legal requirement. You have to be able to justify automated decisions to auditors, regulators, and customers.
- Rapid Prototyping: When you need to get a model up and running fast to test a hypothesis or build a proof-of-concept, machine learning is the way to go. Training times are often measured in minutes or hours, not days or weeks.
Actionable Insight: Choose Machine Learning when you need fast, explainable results with limited data. For problems like credit scoring or employee attrition prediction, its transparency is a non-negotiable business requirement, making it the pragmatic choice.
This focus on clarity and efficiency is a recurring theme in applied data science. For instance, in our discussions on machine learning in marketing, the ability to explain which campaign features are influencing customer behavior is invaluable for strategy and budget allocation.
A Practical Case Study: XGBoost vs. RNN-LSTM
A real-world example from our own work at DataNizant drives this point home. We were tackling a time-series forecasting problem to predict traffic. The intuitive first thought might be to reach for a sophisticated RNN-LSTM, a deep learning architecture built specifically for sequential data. However, a well-tuned XGBoost model—a classic machine learning algorithm—actually delivered better results.
This visualization shows the comparative performance of the XGBoost model.

The key insight here is that more complexity doesn't automatically mean better performance. The XGBoost model was not only more accurate for this specific dataset but was also much quicker to train and far simpler to interpret and deploy.
This wasn't just a one-off. A 2024 study on vehicle traffic forecasting from Italian tollbooths compared several machine learning methods against an RNN-LSTM deep learning model on a dataset of 8,766 hourly records. The results showed that the XGBoost algorithm achieved higher prediction accuracy, measured by both mean absolute error (MAE) and mean squared error (MSE). You can read the full research about these traffic prediction findings for a deeper dive.
Where Deep Learning Delivers Unmatched Performance
While traditional machine learning is fantastic for problems demanding speed and interpretability, deep learning truly shines when faced with immense complexity and scale. In the deep learning vs machine learning debate, some domains exist where deep learning isn't just a better option—it's the only practical way forward. This is especially true when you're dealing with massive, unstructured datasets where the patterns are far too subtle for a human to find and label.
Deep learning models are built to consume big data. Their performance gets better and better as you feed them more information, making them the go-to for large-scale tasks like image recognition in self-driving cars, language understanding in advanced chatbots, or speech recognition in virtual assistants like Alexa and Siri.
The Power of Hierarchical Feature Learning
The real magic behind deep learning is its ability to learn features in layers, or hierarchies. With a traditional machine learning model, a data scientist would have to painstakingly define what features make up an "eye" or a "wheel" in a picture. A deep learning model, particularly a Convolutional Neural Network (CNN), figures this out on its own.
- The first layer of a CNN might learn to spot simple things like edges and pixels.
- The next layer combines those edges to recognize basic shapes and textures.
- Deeper layers then assemble those shapes into complex objects, like a car's headlight or a person's face.
This layered approach lets the model build a rich, multi-level understanding of the data that would be almost impossible to program by hand. It's this automatic feature extraction that unlocks such high performance on incredibly complex tasks.
This diagram shows how a typical CNN breaks down an image, layer by layer, to make a final classification.

The image is processed through a series of filters and layers, with each step creating more abstract, higher-level features until the network can make an accurate prediction.
Practical Example: Advanced Chatbots and NLP
Think about the difference between a simple, rule-based chatbot and a sophisticated conversational AI like ChatGPT. The first one relies on predefined scripts and keyword matching—a classic machine learning technique. It breaks down the moment a user asks something in a way it wasn't programmed to expect.
In contrast, modern AI assistants use deep learning models like transformers to grasp the context, nuance, and intent behind our language. These models are trained on trillions of words, which allows them to understand grammar, idioms, and even sarcasm. This is a perfect example where the deep learning vs machine learning comparison clearly favors deep learning for creating complex, human-like interactions.
Actionable Insight: When your goal is to interpret unstructured, high-dimensional data—like understanding the semantic meaning of a sentence or identifying objects in a live video feed—deep learning's self-learning architecture provides an unmatched performance edge. Don't try to manually engineer features for this; let the neural network do the heavy lifting.
For anyone curious about how these advanced models are put to work, we've covered many real-world examples of deep learning in NLP that showcase its power.
When Deep Learning is the Decisive Choice
So, when should you reach for deep learning? It becomes the obvious choice when your project has a few key characteristics. You're likely in deep learning territory if your problem involves:
- Extreme Complexity: The patterns in your data are too subtle or abstract for a human to define. Think of challenges like drug discovery or genomic sequencing.
- Massive Unstructured Datasets: You have access to enormous amounts of raw data—images, audio files, or plain text—and you need a model that can make sense of it directly.
- High-Stakes Accuracy: The cost of getting it wrong is high. In fields like medical diagnostics or autonomous navigation, even a tiny improvement in accuracy can have a massive impact.
Evaluating Performance and Resource Trade-Offs
Picking between deep learning and traditional machine learning is rarely a simple accuracy contest. A more grounded evaluation means looking at performance versus cost—where "cost" is everything from hardware expenses and training time to the business risk of a model you can't explain.
The real question in the deep learning vs. machine learning debate isn't just, "Which model is more accurate?" It's, "Which model gives me the best return on investment for my specific project?"
This trade-off is especially stark in high-stakes fields like clinical predictive modeling. While deep learning often has an edge, it's not a guaranteed win, and those gains come with serious costs.

A Clinical Prediction Case Study
Medical research really brings this complex relationship to life. One study compared seven deep learning models against two traditional machine learning algorithms for predicting mental illness. The top deep learning model hit an F1-measure of 0.62, while the best ML model scored around 0.54. It's a measurable improvement, but not a world-changing one.
What's really interesting is that the deep learning models were much better at reducing Type II errors (false negatives). In healthcare, missing a diagnosis can have devastating consequences, so this is a huge deal. Their higher F2 scores, which went up to 0.71, reflected this strength.
But this performance boost came at a steep price. The deep learning models took about 122 minutes to train, a massive jump compared to the traditional methods. And when you look at a wider range of medical prediction tasks, traditional ML still came out on top in 11% of cases. You can dig into the specifics in the full clinical prediction study.
This example perfectly captures the real-world dilemma. The "best" model isn't just about the highest accuracy. It’s the one that actually fits your budget, timeline, and compliance needs.
Balancing Accuracy Gains And Resource Costs
The choice between ML and DL forces you to carefully weigh what you're willing to spend to get a certain level of performance. This balance comes down to a few key factors:
- Hardware Costs: Deep learning almost always demands expensive GPUs or TPUs to train efficiently. If you're working with standard CPUs, a traditional machine learning model is the far more practical route.
- Training Time: Just like in the clinical example, DL models can take orders of magnitude longer to train. This "time-to-insight" can be a deal-breaker on projects with tight deadlines.
- Data Investment: Deep learning’s appetite for huge datasets means a bigger investment in data collection, storage, and cleaning.
This is the constant balancing act at the heart of the data science workflow. It’s not just about building a model; it's about keeping it running. That’s why a solid strategy for machine learning model monitoring is non-negotiable for any system in production, no matter what kind of model you're using.
The Overlooked Cost Of The Black Box
Beyond the tangible costs like hardware and time, there’s the critical—and often ignored—factor of model explainability. Traditional ML models are generally transparent. You can see why they made a certain decision, which is absolutely vital in regulated industries or for earning user trust.
The actionable insight is this: The 'best' model is not simply the most accurate one. It is the one that delivers an optimal balance of performance, cost, and interpretability that aligns directly with your project's specific business, budget, and compliance requirements.
Deep learning models, on the other hand, are famous for being opaque "black boxes." Their predictions might be a little better, but not being able to explain the how or why can be a major liability. This lack of transparency can create business risks, make debugging a nightmare, and render the model unusable in situations where regulators demand full explainability.
So, you have to carefully weigh any performance gains from a DL model against the very real cost and risk of its opacity.
A Practical Framework for Making Your Decision
Choosing between deep learning and traditional machine learning isn't just a technical debate. It's a practical, project-level decision. To get it right, you need to ask a few fundamental questions before you write a single line of code.
This isn't about finding one perfect answer, but about understanding the trade-offs. Think of this as a guide to help you land on the most effective and efficient solution for your unique problem.
Key Decision Factors to Consider
The deep learning vs. machine learning choice really boils down to three things: your data, your resources, and how much you need to explain your model's decisions. A quick, honest assessment of these factors will almost always point you in the right direction.
-
What is the scale and nature of your dataset? If you're working with a small, structured dataset—think fewer than 100,000 samples—traditional ML is almost always the more practical route. Deep learning really only starts to shine when you feed it massive, often unstructured, datasets.
-
How critical is model explainability? If you're in a regulated industry or need to justify a model's output to stakeholders, the "white box" nature of traditional ML is a huge win. Before you even consider a "black box" deep learning model, you have to understand your obligations under any relevant AI governance framework.
-
What are your computational and time constraints? Deep learning is hungry. It demands powerful GPUs and can take a long, long time to train. If you're limited to standard CPUs or facing tight project deadlines, machine learning offers a much faster, more budget-friendly path to a working solution.
This simple decision tree helps visualize the path. It shows how the choice often comes down to your dataset size and the hardware you have available.
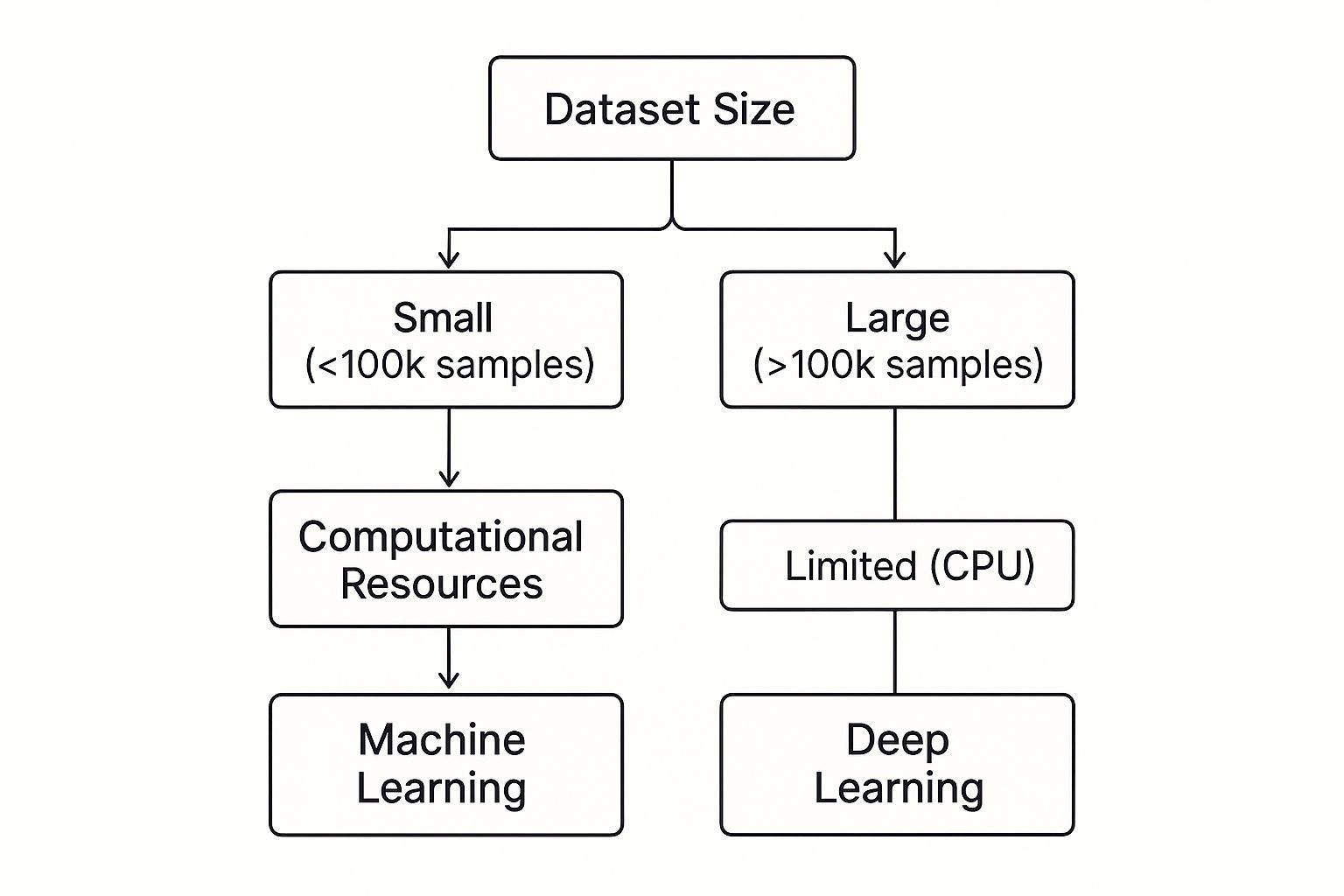
As the graphic shows, without big data and the high-end hardware to crunch it, the promises of deep learning often remain just out of reach. In those cases, traditional machine learning isn't just a backup plan; it's the smart, practical choice.
Actionable Insight for Your Project
The choice between machine learning and deep learning is ultimately a strategic business decision disguised as a technical one. It’s about matching the tool to the reality of your project's data, budget, timeline, and compliance needs.
Practical Example: Imagine a bank building a model to predict loan defaults. Their dataset is structured, relatively small (e.g., 50,000 past loan applications), and financial regulators require a clear, auditable reason for every denied application. In this situation, an explainable machine learning model like logistic regression or a decision tree is the only viable option. The need for transparency and the limitations of the dataset make deep learning a non-starter, regardless of its potential accuracy.
Frequently Asked Questions
Even with a solid understanding of the differences, some practical questions always pop up when you're on the ground, trying to decide between traditional ML and deep learning. Let's tackle a few common ones I hear all the time.
Can I Combine Machine Learning and Deep Learning?
Absolutely, and you often should. This hybrid approach is a powerful way to get the best of both worlds. You can use deep learning for what it's best at—automated feature extraction—and then hand off the results to a more efficient traditional model.
Practical Example: A classic use case is in computer vision. You might use a Convolutional Neural Network (CNN) to process raw images and pull out a rich set of features. Instead of having the CNN do the final classification, you can feed those extracted features into a lighter, faster model like XGBoost to make the final call. This gets you the benefit of automated feature engineering without the full computational cost of an end-to-end DL model.
Which Should a Beginner Learn First?
If you're just starting out, my advice is clear: begin with traditional Machine Learning. It's non-negotiable for building a proper foundation.
Starting with ML gives you a firm grip on the core concepts—data preprocessing, feature engineering, model training, and performance evaluation—using algorithms that are far simpler and easier to interpret. As we've covered in our machine learning mastery series on DataNizant, once you master these fundamentals, you'll have the context to understand why and when the heavy machinery of deep learning is actually necessary.
How Much Data Is Enough for Deep Learning?
There's no single magic number, but a good rule of thumb is that you'll want at least thousands of examples per class for a deep learning model to even start showing its strengths. The real test, though, is always performance.
Actionable Insight: To determine if you have enough data, start with a simple ML model as a baseline. Then, train a DL model and plot its performance as you incrementally add more data. If the DL model's accuracy flatlines or fails to significantly outperform the simpler model, that's a strong signal that you don't have enough data to justify the complexity.
At DATA-NIZANT, we cut through the noise to deliver expert-authored analysis on AI, data science, and digital infrastructure. Explore our in-depth articles to gain actionable intelligence on everything from model governance to cloud-scale computing at https://www.datanizant.com.

