
In machine learning, the term epoch comes up constantly. At its core, it’s beautifully simple: an epoch is one full pass of your entire training dataset through the learning algorithm.
Think of it like a student cramming for a test. Their textbook is the training data, and one full read-through, from the first page to the last, is a single epoch. This process of repetition is how a model truly learns.
Understanding the Core Language of Model Training

To really get what epochs in machine learning are all about, let’s stick with our student analogy. The student's goal isn't just to memorize facts but to understand the material well enough to answer questions they've never seen before.
In this scenario, the entire textbook is the training dataset. It contains everything the student needs to learn.
The Student's Study Plan
Here’s how the key training terms map to our study session:
- Epoch: This is the student reading the entire textbook from start to finish, just one time. As any student knows, one pass is rarely enough to master a complex subject.
- Batch: A textbook might have thousands of pages. Trying to absorb it all in one sitting is a recipe for disaster. So, the student breaks it down into chapters. A batch is like one of those chapters—a smaller, more digestible piece of the whole.
- Iteration: An iteration is the moment the student finishes a chapter and moves on to the next. If the textbook has 10 chapters, it will take the student 10 iterations to finish one complete read-through (a single epoch).
Actionable Insight: If you have a dataset with 10,000 images and you set a batch size of 100, it will take 100 iterations (10,000 / 100) to complete one epoch. This simple calculation helps you estimate training time and resource usage.
A machine learning model, much like our student, needs to see the data more than once. The first epoch might help it grasp the big, obvious patterns. With each subsequent epoch, it refines its understanding, corrects its mistakes, and starts picking up on the more subtle details hidden in the data. Every pass builds on the last, gradually making the model smarter.
The Big Idea: Repetition is key to learning. A single epoch is almost never enough for a model to uncover the complex relationships in a dataset. Multiple epochs allow the model to iteratively tweak its internal logic to get better and better at making accurate predictions.
Why Not Just Run One Giant Epoch?
This begs the question: why not just set the number of epochs to something massive and let the model run? The answer is a critical concept in machine learning called overfitting.
Let's go back to our student. If they read the same textbook 50 times, they might start memorizing the exact wording of sentences and the specific order of examples. They become an expert on the textbook itself, but when faced with a slightly different problem that requires applying the concepts, they falter.
This is exactly what happens to a model that trains for too many epochs. It starts to "memorize" the training data, including all its noise and random quirks, instead of learning the general principles. When this happens, the model looks brilliant on the data it has already seen but fails miserably when it encounters new, real-world data.
The goal is to find that sweet spot—enough repetition to learn properly, but not so much that it just memorizes. This balance is a central theme in our discussion of the bias-variance tradeoff, where we explore the tension between simple models that underfit and complex models that overfit.
The Evolution of Epochs in AI Development
To really get why epochs in machine learning are so critical today, you have to look at how they grew up alongside AI itself. The idea didn't just appear out of thin air; it was born from necessity as our models got smarter and our datasets got bigger.
In the early days of AI, models like the perceptron were pretty simple. They trained on small, clean datasets, so the concept of making multiple passes over the data wasn't a big deal. A handful of epochs was usually all it took because the problems we were solving were far less complex than today's challenges.
From Backpropagation to Big Data
Things really started to shift in the 1980s when backpropagation entered the scene. This technique gave neural networks a much more effective way to learn from their mistakes, but it also created a new problem. All of a sudden, the number of training passes—the number of epochs—became a make-or-break dial you had to get just right. Too few epochs, and the model learned nothing. Too many, and it just memorized the training data.
This was a major turning point. The concept of an epoch is deeply tied to the history of neural networks and deep learning. An epoch is simply one full pass of the training data through the model, and with backpropagation in the picture, researchers had to figure out the sweet spot empirically. Breakthroughs in the 2000s, like those from Geoffrey Hinton, hinged on effective training over many epochs to hit new accuracy benchmarks. For a full rundown of these moments, you can check out this machine learning’s timeline.
The number of epochs transformed from a simple counter into a key hyperparameter that engineers had to carefully tune. Getting it right meant the difference between a breakthrough model and a failed experiment.
The Modern Era of Massive Models
Then came the 2000s and the data explosion. Thanks to the internet, the amount of available data grew at an unbelievable rate. This set the stage for the deep learning revolution of the 2010s, where massive neural networks with millions of parameters became the standard.
These gigantic models needed equally gigantic datasets to learn from, which made managing epochs an even bigger challenge.
- Computational Cost: Training a large model like a transformer on a huge dataset for even a single epoch can take a ton of time and money.
- Data Complexity: Today's datasets aren't just big; they're messy, diverse, and full of noise. A model needs just enough epochs to find the real patterns without getting sidetracked by irrelevant details.
- Infrastructure Demands: The sheer scale of modern training requires serious hardware. This is why understanding cloud computing for machine learning has become essential for anyone working in the field today.
What worked for a simple model in the 1990s is completely out of the question now. We no longer just pick a number of epochs and cross our fingers. Instead, we use sophisticated techniques like early stopping and learning rate scheduling to find the right training duration on the fly. The epoch is still a core unit of training, but how we approach it has been totally redefined by decades of progress in AI.
How to Find the Optimal Number of Epochs
Figuring out the right number of epochs in machine learning isn’t about landing on a magic number. It's really about striking a critical balance.
Train your model for too short a time (too few epochs), and it won't have a chance to learn the important patterns in your data. This is called underfitting. But if you let it train for too long (too many epochs), it starts memorizing the training data—noise, quirks, and all—which leads to overfitting.
The real goal is to find that "sweet spot" where the model performs well on new, unseen data. Instead of just guessing, we can use a couple of smart, data-driven strategies to pinpoint this optimal moment during the training itself.
Monitor Your Training and Validation Loss
The single most effective way to see what your model is doing is to track its performance on two separate datasets as it trains: the training set and a validation set. By plotting the loss (which is just a measure of error) for both sets after each epoch, you can literally watch for signs of trouble.
Actionable Insight: In a healthy training run, you'll see both the training loss and validation loss curves heading downward together. But the second you see the validation loss start to creep back up while the training loss continues to drop, you've found it. That's the classic sign of overfitting. The model has stopped learning general rules and has started cheating by memorizing the answers.
This graph gives you a clear picture of what this looks like.
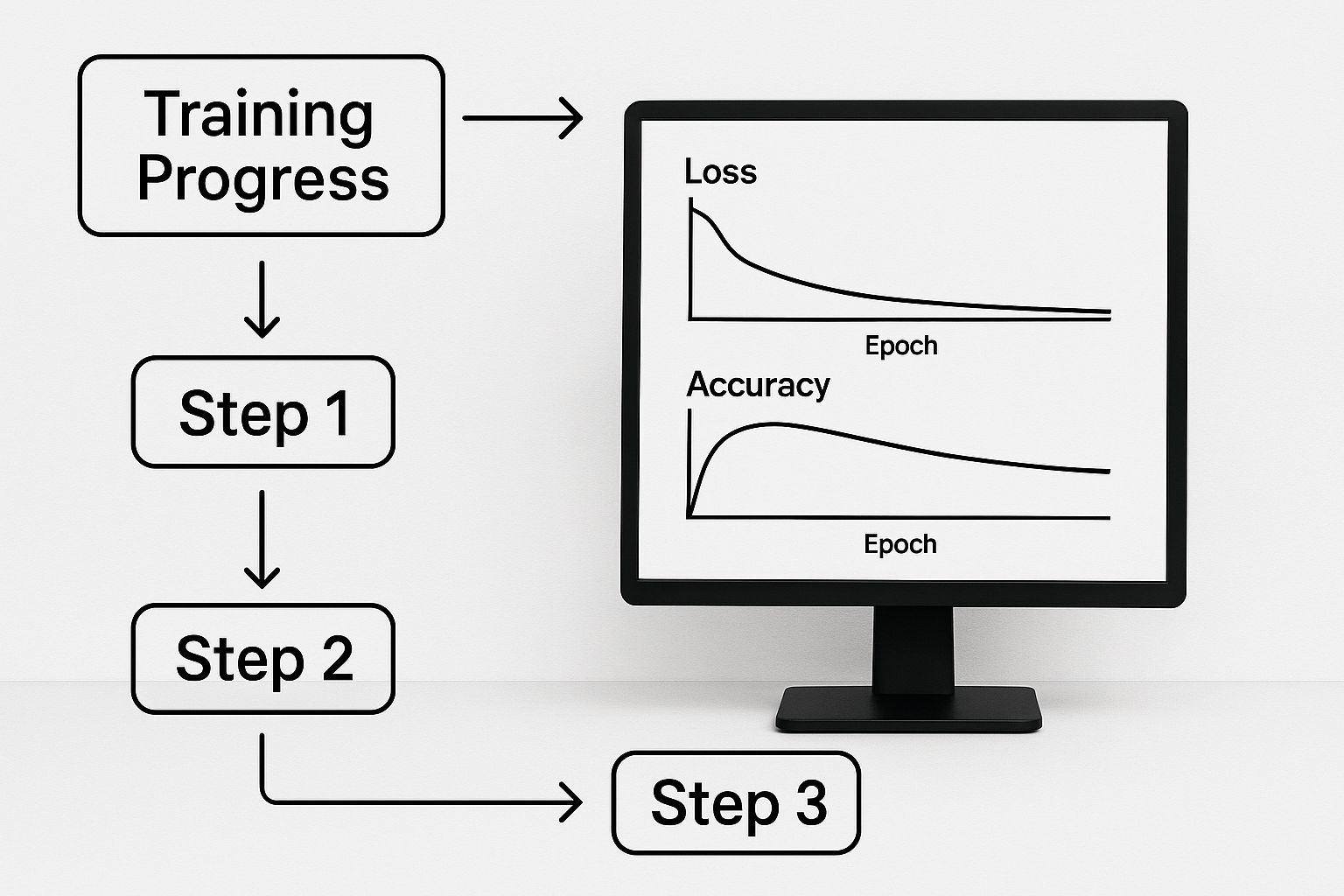
You can see the perfect moment to stop is right at the bottom of that validation loss curve, just before it starts to climb. Watching these plots manually is a great way to build intuition, but thankfully, there's a much more efficient and automated way to handle this.
Underfitting vs Overfitting Training Characteristics
To help you diagnose your model's behavior, this table breaks down the common symptoms of underfitting and overfitting. By observing your training and validation metrics, you can quickly identify which problem you're facing.
| Characteristic | Underfitting (Too Few Epochs) | Optimal Fit | Overfitting (Too Many Epochs) |
|---|---|---|---|
| Training Loss | High and decreasing slowly, or flat. | Decreasing steadily and converging. | Very low and continuing to decrease. |
| Validation Loss | High and decreasing slowly, or flat. | Decreasing steadily and converging with training loss. | Starts to increase after reaching a minimum point. |
| Training Accuracy | Low and not improving much. | High and close to validation accuracy. | Very high, approaching 100%. |
| Validation Accuracy | Low, similar to training accuracy. | High and close to training accuracy. | Stagnates or starts to decrease. |
| Model Performance | Poor on both training and new data. | Good generalization to new, unseen data. | Excellent on training data, but poor on new data. |
Monitoring these characteristics is the key to stopping your training at just the right time, ensuring you end up with a model that actually works in the real world.
Implement Early Stopping for Automated Control
Early Stopping is a clever technique that automates the whole process of watching the validation loss. You simply set a rule that tells the training process to stop on its own once the model’s performance on the validation set hasn't improved for a certain number of epochs. This automatically prevents the model from wandering into the overfitting danger zone.
Think of it like an automated circuit breaker. It lets the model train as long as it's making real progress and cuts the power the moment it stalls. This saves you from running countless unnecessary epochs and, more importantly, protects you from ending up with an overfitted model.
Of course, this all hinges on having a good quality validation set, which really underscores the importance of proper data preparation. Our guide on mastering data cleaning in Python with Pandas walks through practical steps to get your datasets ready for training.
Here's a quick look at how you'd implement an Early Stopping callback in Python using the popular Keras library. It's surprisingly simple.
import tensorflow as tf
from tensorflow.keras.callbacks import EarlyStopping
# First, define the Early Stopping callback
# 'monitor' tells it what metric to watch (validation loss is a great choice)
# 'patience' is how many epochs to wait for improvement before stopping
early_stopper = EarlyStopping(monitor='val_loss', patience=5)
# Now, just include this callback when you train your model
model.fit(
X_train,
y_train,
epochs=100, # Set a high number; Early Stopping will find the true best one
validation_data=(X_val, y_val),
callbacks=[early_stopper]
)
In this practical example, we've told the model to run for 100 epochs, but it will almost certainly stop much sooner. The patience=5 parameter gives the model a bit of breathing room—it'll wait five full epochs for the val_loss to improve before it calls it quits. This one simple callback gives you the power to train models far more efficiently and build solutions that are genuinely more robust.
A Practical Example: Training an Image Classifier
Theory is great, but to really get a feel for epochs in machine learning, let's roll up our sleeves and train a simple model. We'll build an image classifier to tell the difference between clothing items—t-shirts, pants, sneakers, and so on—using the well-known Fashion MNIST dataset. This quick, hands-on demo will show you exactly how epochs affect a model's performance and why stopping at the right moment is everything.
Here’s the game plan: we'll build a basic convolutional neural network (CNN) and train it for way too long on purpose. This will let us see the exact moment overfitting kicks in. After that, we'll do it all over again, but this time we'll use the Early Stopping technique to let the model find its own perfect stopping point.
Setting Up the Experiment
Our playground is the Fashion MNIST dataset, a collection of 70,000 grayscale images of clothes, each one a tiny 28×28 pixels. We'll use TensorFlow and Keras, the go-to libraries for this kind of work.
The setup is pretty standard stuff:
- Load and Prep the Data: We'll split the images into training and testing sets and scale the pixel values down to a range between 0 and 1. This helps the model learn faster.
- Build the CNN Model: Our network will have a couple of convolutional layers to spot features like edges and textures, followed by dense layers that make the final call on what kind of clothing it is.
- Compile the Model: We need to give the model its instructions—an optimizer (we'll use Adam), a loss function to measure error, and a metric to track our progress (accuracy).
With everything in place, we're ready for the first run.
Training Run 1: Watching Overfitting Happen Live
For our first go, we're going to set the number of epochs to 50. For this simple dataset, that's definitely overkill. The goal here isn't to build a great model; it's to push it past its prime and see what happens when it starts to overfit.
As the model trains, we’ll keep an eye on two key numbers: its accuracy on the training data and its accuracy on the validation data (a slice of data it hasn't seen before). At first, both should climb nicely together. But after a while, you'll see a gap start to open up. The training accuracy will keep inching toward 100%, but the validation accuracy will hit a wall and then start to slide backward.
This divergence is the classic signature of overfitting. The model has stopped learning general patterns and has started memorizing the training examples, noise and all. That peak right before the validation accuracy drops? That’s the sweet spot—the true optimal number of epochs.
Keeping an eye on these metrics is fundamental to building reliable models. As systems get more complex, this kind of continuous observation evolves into robust machine learning model monitoring to make sure they keep performing correctly out in the real world.
Training Run 2: Smart Stopping with Early Stopping
Okay, let's reset and run the exact same experiment with one small but powerful change. This time, we'll add an Early Stopping callback. We'll tell it to watch the validation loss and pull the plug if things don't get better for three straight epochs (patience=3).
We'll still tell the model it can run for up to 50 epochs, but this callback is our automated supervisor. The second it sees that the model's performance on new data has peaked, it will gracefully halt the training process.
The result? The model stops right at its peak performance, probably somewhere around epoch 10-15 for this setup. We end up with a model that's not just more accurate on unseen data, but was also trained far more efficiently. That saves time and computational costs. This little comparison makes it crystal clear: choosing the right number of epochs in machine learning isn't about picking a big number and hoping for the best. It's about using smart, automated techniques to find the ideal balance.
While we're focused on a classification task here, AI's power extends into creative fields, too. For instance, similar principles of iterative training are used when you generate images with AI, where each training step refines the model's ability to create coherent visuals.
Advanced Strategies for Optimizing Training
Finding the right number of epochs is a great start, but it's really just one piece of a much larger puzzle. To truly optimize your model, you have to understand how all the different training components work together. Advanced strategies go beyond simply counting passes over the data; they focus on dynamically guiding the model to its best performance, often faster and more reliably.

This means thinking about the number of epochs in machine learning not as a fixed target, but as part of a journey. To make that journey as smooth and efficient as possible, you need to master techniques like learning rate scheduling and pick the right optimizer for the job.
The Power of Learning Rate Scheduling
Imagine you're searching for treasure buried somewhere in a vast, hilly landscape. The learning rate is how big of a step you take. When you start, you want to take huge, confident strides to cover ground quickly. But once you get close to the treasure, you need to slow down, taking smaller, more precise steps to pinpoint its exact location.
A fixed learning rate is like taking the exact same size step the whole time—you risk walking right past the treasure. This is where learning rate scheduling comes in. It solves the problem by automatically adjusting your step size as you train.
Actionable Insight: By starting with a larger learning rate and gradually shrinking it over subsequent epochs, a scheduler helps the model make quick progress at the beginning and then carefully fine-tune its parameters for maximum precision later on.
Two popular scheduling methods you'll run into are:
- Step Decay: This is a straightforward approach. You just drop the learning rate by a set amount after a certain number of epochs. For instance, you could cut the learning rate in half every 10 epochs.
- Cosine Annealing: This method is much smoother. It gradually lowers the learning rate following a cosine curve, starting high, dipping low, and sometimes cycling back up to help the model escape tricky spots in the loss landscape.
Using a scheduler often means a model can converge in fewer epochs, which saves you a ton of time and computational resources while usually getting you better results.
Choosing the Right Optimizer
Your optimizer is the engine that drives the learning process, and your choice here directly impacts how many epochs you'll need. It's the algorithm that decides exactly how the model updates its internal parameters based on the errors it sees.
Let's look at two of the most common optimizers.
SGD with Momentum:
Think of Stochastic Gradient Descent (SGD) with momentum as a reliable workhorse. It helps the model build up speed in the right direction, allowing it to cruise past small bumps in the loss landscape. It's often very stable but might take more epochs and careful learning rate tuning to find the best solution.
Adam Optimizer:
Adam, which stands for Adaptive Moment Estimation, is a more modern, adaptive optimizer. It's smart enough to calculate an individual learning rate for every single parameter in the model, changing its "step size" on the fly. This often allows it to converge much faster than SGD, meaning you can get great performance in fewer epochs. The trade-off? Its adaptivity can sometimes cause it to settle into a solution that doesn't generalize quite as well as one found by the slower, more methodical SGD.
Ultimately, the number of epochs your model needs is not some isolated figure. It’s deeply tied to your learning rate strategy and your choice of optimizer. Finding the right balance is key, just like understanding the fundamental tension between a model that's too simple and one that's too complex. We explore this very concept in our article on the bias-variance tradeoff. Experimenting with these advanced settings is how you go from just training a model to engineering a truly high-performing one.
Common Questions About Epochs In Machine Learning
Training a model can feel like juggling a dozen moving parts—epochs, batches, iterations, and more. Over time, you’ll notice the same handful of questions cropping up. Think of this as your quick-reference cheat sheet to clear up any confusion and keep your training on track.
What Is The Difference Between An Epoch, An Iteration And A Batch
Imagine you’re training on a dataset of 10,000 images. Here’s a practical breakdown:
- An epoch is one complete pass through all 10,000 images.
- A batch is a smaller, manageable chunk of that data. If your batch size is 100, you'll process the data in groups of 100 images.
- An iteration is one update of the model's weights. In this scenario, completing one batch is one iteration.
Actionable Insight: With 10,000 images and a batch size of 100, you will have 100 iterations per epoch (10,000 images / 100 images per batch). This shows how the terms are directly connected.
Is It Bad To Set The Number Of Epochs Too Low
Yes—if you cut training too short, your model never really learns. It’s the equivalent of skimming half a textbook before test day.
When both training loss and validation loss stay high and refuse to flatten, you’re staring at underfitting. More epochs give your model the extra practice it needs to capture key patterns.
How Do Epochs And Learning Rate Interact
Epochs and learning rate go hand in hand. Think of the learning rate as your stride length:
- A high learning rate means big, bold steps—fast progress early on, but you risk jumping past the sweet spot.
- A low learning rate is more cautious, taking small corrective steps that often require more epochs to converge.
That’s why seasoned practitioners often rely on learning rate schedules—kick off with a higher rate for rapid gains, then taper off to fine-tune.
Is There A Perfect Number Of Epochs To Always Use
Spoiler: there isn’t one magic number. The best count depends on several factors:
- Model Complexity: Deeper, more intricate architectures usually demand extra epochs.
- Dataset Size And Complexity: Larger or noisier datasets need more passes to reveal their structure.
- Batch Size: Smaller batches update your model more frequently within each epoch, sometimes speeding up convergence.
Actionable Insight: In real-world projects, you’ll monitor validation loss and always employ Early Stopping. This data-driven approach ensures you stop training at just the right moment—no guesswork required.
At DATA-NIZANT, we break down complex AI and machine learning topics into clear, actionable insights. Keep exploring our in-depth guides and sharpen your expertise. Visit us at Data-Nizant.

