
In the age of data-driven decision-making, the quality of your insights is directly tied to the quality of your data. Poor data, riddled with inaccuracies, inconsistencies, and missing values, can lead to flawed models, misguided business strategies, and a fundamental lack of trust in your analytical outcomes. This isn't just a technical hurdle; it's a critical business risk. Establishing robust data cleaning best practices is no longer optional, it is the foundational step toward unlocking the true potential of your data assets and ensuring the reliability of your AI and analytics initiatives.
This article moves beyond generic advice to provide a comprehensive roundup of seven actionable, expert-backed practices that will transform your raw data into a reliable resource. We will explore a complete framework for maintaining data integrity, equipping you with the strategies needed to build scalable and trustworthy systems.
You will learn how to:
- Develop a strategic approach to data profiling.
- Implement standardized validation rules across your organization.
- Handle missing data with sophisticated, context-aware techniques.
- Create automated monitoring and iterative cleaning workflows.
We'll break down everything from foundational data documentation to building automated, iterative cleaning workflows, complete with practical examples and tools you can implement today. By mastering these techniques, you'll ensure your data is not just clean, but ready to power the next generation of AI and business intelligence. Get ready to dive into the essential protocols that separate high-impact analytics from unreliable noise.
1. Develop a Data Profiling Strategy
Attempting to clean data without first understanding its condition is like navigating a maze blindfolded. This is where data profiling comes in, serving as a critical first step in any effective data cleaning process. Data profiling is the systematic analysis of a dataset to understand its structure, content, quality, and relationships. It’s a diagnostic phase that provides a comprehensive overview of the data's current state, revealing the specific issues that need to be addressed.

This foundational practice, championed by data quality experts like Thomas Redman, involves generating summary statistics and analytical reports on your data. These reports help you identify patterns, detect anomalies, assess completeness, and validate whether the data conforms to established standards. By creating a detailed "map" of your data, you can move from reactive, ad-hoc cleaning to a proactive, strategic approach. This is one of the most crucial data cleaning best practices because it ensures your efforts are targeted, efficient, and effective.
How Data Profiling Works
Data profiling techniques can range from simple column analysis to complex cross-table relationship discovery. The core process typically involves:
- Column/Attribute Analysis: Examining individual columns to understand their data types, value ranges, and frequency distributions. This helps identify outliers, inconsistent data types (e.g., text in a numeric field), and unexpected values.
- Structure Discovery: Analyzing the data for patterns, such as identifying a column as a potential primary key or discovering functional dependencies between columns (e.g., a "City" column is always determined by a "ZIP Code" column).
- Relationship Analysis: Identifying connections between different data tables or sources. This is vital for ensuring referential integrity before merging or joining datasets.
For instance, a bank profiles transaction data to spot patterns indicative of fraud before initiating any cleansing operations. Similarly, healthcare organizations profile patient records to flag potential HIPAA compliance issues, like personal identifiers in incorrect fields, before data is used for analysis.
Actionable Tips for Implementation
- Start with a Sample: For massive datasets, profiling the entire collection can be time-consuming. Begin by profiling a statistically significant, representative sample to get initial insights quickly.
- Use Automated Tools: Leverage powerful libraries and tools to accelerate the process. Pandas Profiling in Python, for example, can generate a detailed HTML report with just a single line of code. For more robust, enterprise-level governance, tools like Great Expectations allow you to create automated data validation tests based on your profiling findings.
- Document and Standardize: Maintain a data dictionary or a standardized profiling report. This document should record metadata, data types, null value counts, and identified quality issues for each attribute. This creates a valuable, shareable resource for the entire team. A well-defined data profiling approach is a key component of a larger data strategy. You can learn more about developing a comprehensive data strategy framework to see how profiling fits into the bigger picture.
2. Implement Standardized Data Validation Rules
If data profiling is the diagnostic phase, then implementing standardized validation rules is the treatment plan. This practice involves establishing a consistent set of rules and constraints that data must meet to be considered valid and usable. It moves beyond simply finding errors to actively preventing them and systematically handling data that fails to conform to expected formats, ranges, or business logic.

The principles of data validation are foundational, with roots in the relational database theory pioneered by Edgar F. Codd and formalized by organizations like the Data Management Association (DAMA). This approach creates a "quality gate" that data must pass through, ensuring that any information entering your systems meets predefined standards. By creating a unified rulebook for data quality, you enforce consistency across the entire dataset, which is a cornerstone of effective data cleaning best practices. This prevents the classic "garbage in, garbage out" problem at its source.
How Standardized Validation Works
Standardized validation applies a predefined logic to each data point or record to check its correctness and conformity. This process can be simple or highly complex, depending on the business requirements. Key validation types include:
- Format Validation: Ensuring data adheres to a specific pattern. For example, verifying that a phone number follows the
(###) ###-####format or that an email address contains an "@" symbol and a domain. - Range and Constraint Validation: Checking if numeric or date values fall within an acceptable range. This could mean ensuring an order date isn't in the future or a customer's age is between 18 and 120.
- Consistency and Completeness Checks: Verifying that required fields are not empty and that related data is logical. For instance, if a "Country" field is "USA," the "State" field cannot be "Ontario."
- Uniqueness Validation: Ensuring that values in a key column, like a customer ID or order number, are unique and not duplicated across the dataset.
For example, Amazon enforces strict validation rules for its product catalog data, ensuring that prices are within a logical range and inventory numbers are positive integers. Similarly, financial institutions use complex validation rules during customer onboarding to check for missing identity documents or invalid tax identification numbers, ensuring compliance with KYC (Know Your Customer) regulations.
Actionable Tips for Implementation
- Start Simple, Then Scale: Begin by defining basic validation rules for critical fields, such as checking for null values or correct data types. Gradually introduce more complex logic, like cross-field consistency checks, as your understanding of the data deepens.
- Leverage Regular Expressions (Regex): For complex format validation, such as for email addresses, postal codes, or custom IDs, regular expressions are an incredibly powerful tool. They provide a flexible and concise way to define and enforce intricate patterns.
- Implement Tiered Validation: Not all errors are equal. Create a tiered system with "warnings" for minor issues that might be acceptable and "errors" for critical failures that must be corrected or rejected. This prevents workflows from halting unnecessarily while still flagging important quality concerns.
- Create a Reusable Rule Library: Don't reinvent the wheel for every project. Develop a centralized, version-controlled library of validation rules. Tools like Great Expectations excel at this, allowing you to define "Expectations" that can be reused across different datasets, pipelines, and teams, promoting consistency and saving significant development time.
3. Create Comprehensive Documentation and Audit Trails
Attempting to manage a data pipeline without a record of transformations is like trying to retrace your steps in a forest without leaving any trail markers. This is where documentation and audit trails become indispensable, serving as the official record of your data's journey. This practice involves meticulously logging every cleaning action: what was changed, why it was changed, who made the change, and when it occurred. It establishes a foundation of transparency, reproducibility, and accountability.
This principle, heavily influenced by regulatory standards like Good Manufacturing Practice (GMP) and data governance frameworks from organizations like DAMA, elevates data cleaning from a series of isolated tasks to a controlled, auditable process. By creating a detailed logbook, you empower your team to understand the lineage of the data, justify cleaning decisions, and roll back changes if necessary. This commitment to documentation is one of the most critical data cleaning best practices because it builds trust in the data and safeguards against errors and compliance risks.
How Documentation and Audit Trails Work
Effective documentation captures both the "how" and the "why" of data cleaning, ensuring anyone can understand the logic behind the final dataset. The core components of this practice include:
- Change Logging: Systematically recording every modification made to the data. This log should detail the specific transformation applied (e.g., removing duplicates, imputing missing values with the mean), the scope of the change (e.g., "Column: 'Age', Rows: 50-75"), and a timestamp.
- Version Control: Treating data cleaning scripts and datasets like software code. Using systems like Git allows you to track changes over time, compare versions, and revert to a previous state if a cleaning step introduces an error.
- Business Justification: Annotating logs with the business context or rule that prompted the change. For example, documenting that outliers were removed based on a specific business rule agreed upon with the sales department.
In practice, a pharmaceutical company maintains meticulous audit trails for clinical trial data to meet strict FDA requirements, proving that no data was tampered with improperly. Likewise, financial institutions document every data transformation in their risk models to pass regulatory audits and demonstrate compliance.
Actionable Tips for Implementation
- Automate Your Logging: Manually documenting every step is prone to human error and tedious. Use logging libraries within your programming environment (e.g., Python's
loggingmodule) or features within data transformation tools like dbt to automatically create detailed audit trails as your scripts run. - Standardize Documentation Formats: Create a consistent template for all data cleaning documentation. This should include sections for the data source, the cleaning script version, a summary of changes, the author, and the date. Standardization makes the information easier to find, read, and compare across projects.
- Store in a Central, Version-Controlled Repository: Keep all your cleaning scripts, documentation, and data dictionaries in a shared repository like GitHub or GitLab. This ensures everyone is working from the same information and provides a complete, historical record of all data-related activities. This practice aligns with the ALCOA+ principles for data integrity, ensuring data is Attributable, Legible, Contemporaneous, Original, and Accurate.
4. Handle Missing Data Strategically
Missing data is an unavoidable reality in virtually every dataset, but how it's handled can make or break the validity of your analysis. A common mistake is to simply delete rows with missing values (listwise deletion) or fill them with a simple mean, which can introduce significant bias and discard valuable information. Strategic missing data handling moves beyond these naive approaches by first understanding why the data is missing and then applying a method that best preserves the dataset's integrity.
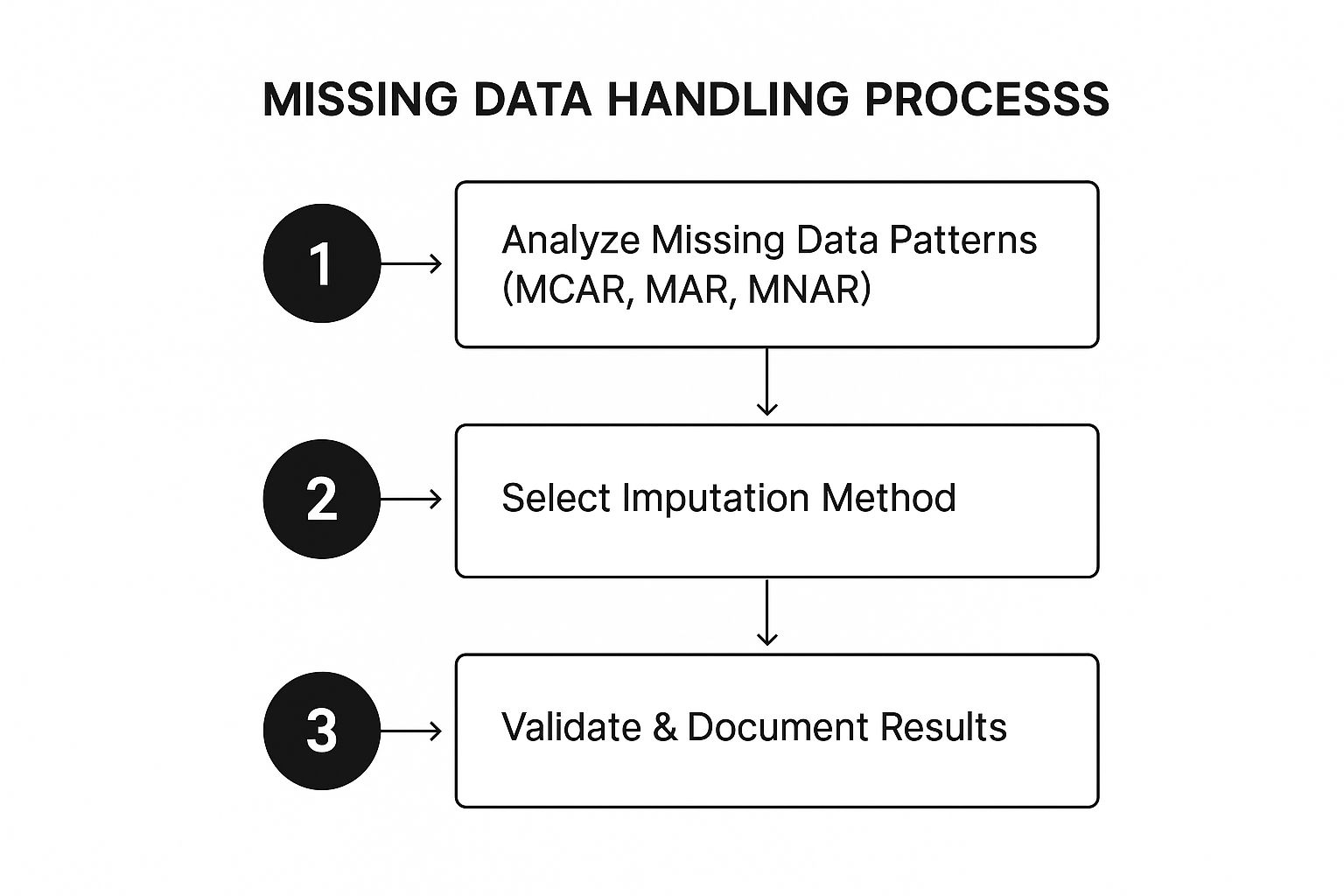
This methodical approach, heavily influenced by the work of pioneers like Donald B. Rubin and Roderick J.A. Little, recognizes that the mechanism behind missing data dictates the solution. By classifying the missingness pattern, you can choose a technique, from simple imputation to more advanced statistical methods, that minimizes distortion. A key element of any robust set of data cleaning best practices is treating missing data not as a nuisance to be eliminated, but as a puzzle to be solved thoughtfully.
How Strategic Missing Data Handling Works
The core of this practice is to diagnose the type of missingness before prescribing a treatment. Data is typically classified into one of three categories:
- Missing Completely at Random (MCAR): The probability of a value being missing is unrelated to both the observed data and the missing data itself. For example, a survey respondent accidentally skips a question.
- Missing at Random (MAR): The probability of a value being missing is related to the observed data, but not the missing data itself. For example, men might be less likely to answer a survey question about depression than women.
- Missing Not at Random (MNAR): The probability of a value being missing is related to the missing value itself. For example, individuals with very high incomes are less likely to disclose their income.
Medical research provides a classic example. When patient data is missing from a clinical trial, simply deleting those records could bias the study's outcome. Instead, researchers use methods like multiple imputation to create several plausible completed datasets, analyze them individually, and then pool the results to account for the uncertainty caused by the missing values.
Actionable Tips for Implementation
- Analyze Patterns First: Before any imputation, use visualization tools and statistical tests to understand the extent and nature of your missing data. This diagnostic step is crucial for selecting an appropriate method.
- Use Multiple Imputation for Key Variables: For critical analytical variables where the data is likely MAR, use multiple imputation. Libraries like
micein R orIterativeImputerin Python's Scikit-learn provide powerful, accessible implementations of this technique. - Document All Assumptions: Clearly document which method you used to handle missing data for each variable and state the assumptions you made (e.g., "Assumed income data was Missing at Random and imputed using MICE"). This ensures reproducibility and transparency.
- Validate Your Imputation: After imputing values, compare the distribution of the imputed data against the original, observed data. If the imputed values drastically alter the variable's distribution, your chosen method may be inappropriate.
5. Implement Automated Data Quality Monitoring
Data cleaning is not a one-time event; it's a continuous process. Implementing automated data quality monitoring shifts the paradigm from reactive cleanups to proactive governance. This approach involves setting up systems that perpetually check data quality metrics, detect anomalies, and alert teams to potential issues in real-time or near-real-time. It’s about building a vigilant, automated guard for your data pipelines.

This practice, largely popularized by Site Reliability Engineering (SRE) principles from Google and modern open-source frameworks, treats data quality as a critical operational metric, similar to application uptime or latency. By catching data decay or corruption at the source, you prevent flawed information from propagating through downstream systems, analytics, and machine learning models. Embracing automation is one of the most impactful data cleaning best practices because it scales quality assurance and minimizes the risk of making critical decisions based on bad data.
How Automated Monitoring Works
Automated data quality monitoring integrates directly into your data pipelines and workflows. The process typically involves defining expectations about your data and then programmatically validating against them.
- Defining Data Assertions: You create a set of rules or "expectations" that your data must meet. These can be simple (e.g., a column must not contain nulls) or complex (e.g., the average value of a column should be within two standard deviations of its historical mean).
- Continuous Validation: As new data flows into your system, these rules are automatically executed. The system checks for conformity and logs the results, tracking metrics like pass/fail rates over time.
- Alerting and Reporting: When a validation fails or a significant anomaly is detected, the system automatically triggers alerts to the responsible teams via Slack, email, or incident management platforms. It also generates dashboards and reports for a high-level view of data health.
For example, e-commerce platforms use automated monitoring to instantly detect illogical product prices or negative inventory levels, preventing costly operational errors. Likewise, Uber monitors its ride-sharing data streams in real-time to flag GPS anomalies, ensuring trip calculations remain accurate and fair.
Actionable Tips for Implementation
- Start with Critical Data: Don't try to monitor everything at once. Begin by defining quality checks for your most critical data assets, those that directly impact revenue or key business operations, and expand your coverage gradually.
- Use Machine Learning for Anomaly Detection: For complex datasets, manually defining every rule is impractical. Leverage machine learning algorithms to learn the normal patterns in your data and automatically flag significant deviations, adapting to seasonality and trends.
- Integrate with Your MLOps/DevOps Toolchain: Embed data quality checks directly into your CI/CD pipelines. Tools like Great Expectations can be run as a step in your data ingestion or transformation jobs, failing a pipeline build if data quality drops below a set threshold. This prevents bad data from ever reaching production.
- Implement Tiered Alerting: Not all data quality issues are equally urgent. Configure a tiered alerting system to avoid alert fatigue, sending critical alerts immediately while batching lower-priority notifications into a daily digest. You can learn more about its data validation capabilities to see how it can be implemented.
6. Establish Data Cleaning Workflows and Standards
Ad-hoc data cleaning, where each team member tackles problems with their own unique methods, quickly leads to inconsistency, rework, and unreliable outcomes. Establishing standardized workflows is the practice of creating repeatable, well-defined processes for data cleaning that can be applied consistently across datasets and projects. This involves defining roles, responsibilities, standard operating procedures (SOPs), and approval steps to ensure cleaning activities are performed systematically, efficiently, and traceably.
Inspired by principles from the Toyota Production System and Lean Six Sigma, this approach treats data cleaning not as a one-off task but as a managed, industrial process. By standardizing the "how," you reduce the cognitive load on your team, minimize errors, and make the entire process more scalable. This is one of the most vital data cleaning best practices for growing organizations because it builds a foundation of quality and consistency that supports all downstream data initiatives.
How Standardized Workflows Work
Implementing standardized workflows means moving from reactive cleaning to a structured, proactive system. The process typically involves defining the sequence of operations, the tools to be used, and the criteria for what constitutes "clean" data.
- Process Definition: Mapping out the step-by-step cleaning process, from initial data ingestion to final validation. This includes specific procedures for handling duplicates, standardizing formats, and imputing missing values.
- Role Clarification: Clearly defining who is responsible for each step in the workflow. This might include data stewards who approve changes, data engineers who implement the scripts, and business analysts who validate the final output.
- Tool Standardization: Specifying which software, libraries, and scripts should be used for particular tasks to ensure consistency and prevent tool sprawl.
For example, a large retail chain uses a consistent workflow for cleaning point-of-sale data from hundreds of stores. The workflow automatically flags mismatched product codes, corrects common entry errors, and standardizes date formats before loading the data into a central warehouse. Similarly, government agencies rely on rigid, documented workflows to process census data, ensuring every record is handled identically to maintain statistical integrity.
Actionable Tips for Implementation
- Automate Routine Tasks: Start by standardizing and automating the most frequent and high-volume cleaning tasks. This delivers the quickest return on investment and frees up your team to handle more complex edge cases.
- Use Workflow Management Tools: Leverage orchestration tools like Apache Airflow, Prefect, or Dagster to define, schedule, and monitor your cleaning workflows as code. These tools provide version control, automatic retries, and detailed logging.
- Build in Flexibility: While standardization is key, your workflows should allow for exceptions. Create a clear protocol for handling data that fails the standard process, including manual review and escalation paths.
- Review and Iterate: Treat your workflows as living documents. Regularly review their performance, gather feedback from the team, and update them based on new data issues or improved techniques. Building these systems is a core part of MLOps and DataOps. You can learn more about designing automated data pipelines to see how these workflows fit into a larger operational context.
7. Perform Iterative Data Cleaning with Feedback Loops
Viewing data cleaning as a one-and-done task is a common pitfall that often leads to incomplete or suboptimal results. Instead, a more effective approach is to treat cleaning as an iterative, cyclical process. Iterative data cleaning involves performing cleaning activities in stages, with each cycle informed by insights and feedback from previous iterations. This method, inspired by agile and lean methodologies, emphasizes continuous improvement and refinement.
This practice transforms data cleaning from a linear, static procedure into a dynamic and responsive system. It acknowledges that the initial understanding of data quality issues may be incomplete. As you clean and begin to analyze the data, new problems often surface. An iterative approach allows you to address these emerging issues systematically, rather than having to backtrack or start over. Adopting this cyclical method is one of the most powerful data cleaning best practices because it ensures the data evolves to meet the precise needs of its end users.
How Iterative Cleaning Works
The core of this practice is the "build-measure-learn" feedback loop applied to data quality. Instead of aiming for a perfectly clean dataset in a single pass, the process is broken down into manageable sprints or cycles.
- Initial Cleaning Pass: The first cycle addresses the most obvious and high-impact errors identified during data profiling, such as fixing structural issues, handling missing values, and standardizing formats.
- Analysis and Feedback: The partially cleaned data is then passed to data consumers (analysts, data scientists, or business users) for initial analysis or use. They provide feedback on its fitness for purpose, highlighting any remaining inaccuracies or usability problems.
- Refinement Cycles: Armed with this feedback, the data team performs subsequent cleaning iterations. Each cycle targets more nuanced or specific issues that were discovered through practical application, gradually improving the data's quality and reliability.
For example, a marketing team might iteratively clean a new customer dataset. The first pass standardizes addresses for a direct mail campaign. After the campaign, feedback on undeliverable mail reveals deeper issues with ZIP code accuracy, prompting a second, more focused cleaning cycle using address validation services. Similarly, social media platforms continuously refine their content moderation algorithms by cleaning data based on evolving community feedback and updated policies.
Actionable Tips for Implementation
- Plan for Iterations: From the outset of any project, build multiple cleaning cycles into your timeline. Communicate to stakeholders that data cleaning is not a single task but a process of progressive refinement.
- Establish Clear Feedback Channels: Create formal, streamlined channels for data consumers to report issues. This could be a dedicated Slack channel, a ticketing system like Jira, or regular review meetings. The key is to make feedback easy to give and easy to track.
- Use Version Control: Treat your datasets like code. Use tools like Git, DVC (Data Version Control), or even simple file naming conventions (e.g.,
dataset_v1.1_cleaned) to track changes across iterations. This allows you to revert to previous versions if a cleaning step introduces new errors. - Define "Done": Set clear, measurable criteria for when the cleaning process is complete. This could be reaching a certain accuracy threshold (e.g., "99% of records have a valid email format") or receiving sign-off from the primary data stakeholders. An iterative approach fits perfectly within a structured project management framework. You can learn more about managing data science projects effectively to see how this cyclical process integrates into a larger workflow.
7 Best Practices Comparison
| Strategy | Implementation Complexity 🔄 | Resource Requirements 🔄 | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐⚡ |
|---|---|---|---|---|---|
| Develop a Data Profiling Strategy | Medium – requires specialized tools/expertise | Moderate – time-consuming for large datasets | High – clear roadmap, prioritized tasks | Initial data assessment, complex datasets | Detailed data understanding ⭐, improved resource allocation ⚡ |
| Implement Standardized Data Validation Rules | Medium – ongoing maintenance needed | Moderate – setup and rule management | High – consistent, reliable data validity | Enforcing consistency, regulatory compliance | Reduces human error ⭐, automatable checks ⚡ |
| Create Comprehensive Documentation and Audit Trails | Medium – time and storage intensive | Moderate – requires logging and version control | High – transparency, reproducibility | Regulated industries, accountability and audit readiness | Ensures compliance ⭐, builds trust ⚡ |
| Handle Missing Data Strategically | High – requires domain expertise and analysis | High – computationally intensive methods | High – reduces bias, preserves data integrity | Research, analytical studies with important missing data | Preserves statistical power ⭐, flexible approaches ⚡ |
| Implement Automated Data Quality Monitoring | High – complex setup and integration | High – requires monitoring tools and algorithms | High – real-time issue detection | Continuous monitoring, large-scale or real-time data flows | Proactive problem detection ⭐, reduces manual effort ⚡ |
| Establish Data Cleaning Workflows and Standards | Medium – initial setup can be time-consuming | Moderate – needs ongoing updates | High – consistent and scalable cleaning | Teams with multiple members, repeated data cleaning tasks | Consistency and coordination ⭐, efficient scaling ⚡ |
| Perform Iterative Data Cleaning with Feedback Loops | Medium-High – requires coordination and project management | Moderate – multiple iterations and feedback cycles | High – continuous improvement and adaptability | Complex, evolving data, projects requiring feedback loops | Continuous process improvement ⭐, incorporates domain knowledge ⚡ |
From Clean Data to Strategic Advantage
Navigating the landscape of data-driven decision-making requires more than just collecting vast amounts of information; it demands a foundational commitment to its quality and integrity. Throughout this guide, we've explored a comprehensive framework built on seven pillars of data cleaning, moving beyond simple fixes to establish a robust, systematic approach. The journey from raw, chaotic data to a pristine, reliable asset is not a one-time event but a continuous discipline.
Mastering these data cleaning best practices is what separates organizations that merely use data from those that truly harness its power. It’s the difference between building models that predict with stunning accuracy and those that produce misleading or biased results. By embracing this structured methodology, you are fundamentally transforming your organization's relationship with data.
Recapping the Core Principles of Data Excellence
Let's distill the essential takeaways from the practices we've covered. These are not just steps in a process; they are interconnected principles that create a powerful, self-reinforcing cycle of data quality.
- Proactive vs. Reactive: The most significant shift is moving from a reactive "fix-it-when-it-breaks" mentality to a proactive strategy. Implementing data profiling and standardized validation rules allows you to anticipate and prevent quality issues before they contaminate your pipelines and analytics.
- Systematization is Key: Ad-hoc cleaning efforts are inefficient and inconsistent. By establishing formalized data cleaning workflows, creating comprehensive documentation, and building automated quality monitoring, you create a scalable, repeatable system that ensures consistency and accountability across all teams and projects.
- Contextual Intelligence: Not all data imperfections are equal. The art of strategically handling missing data and implementing iterative cleaning with feedback loops underscores the need for context. This approach ensures your cleaning decisions are intelligent, purposeful, and aligned with your specific analytical goals, rather than blindly applying generic rules.
The True ROI of Impeccable Data Hygiene
The benefits of institutionalizing these practices extend far beyond the data science team. When your organization can implicitly trust its data, a ripple effect of positive change occurs. Product development accelerates because teams are not bogged down by data-wrangling. Marketing campaigns become more effective because customer segmentation is based on accurate, reliable information. Executive strategies are forged with confidence, backed by analytics that reflect reality.
The ultimate goal of data cleaning is not just to produce clean datasets. It is to cultivate a culture of trust where every stakeholder, from the ML engineer to the CEO, feels empowered to make bold, data-informed decisions without hesitation.
This commitment to data quality is a direct investment in your organization's agility, innovation, and long-term resilience. In an era where AI and machine learning are becoming central to competitive strategy, the quality of your foundational data is your most critical asset. A flawed data foundation will inevitably lead to flawed models, misguided insights, and costly strategic errors. Conversely, a resilient and trustworthy data foundation becomes the launchpad for groundbreaking innovation and a lasting competitive advantage. The journey begins today, by implementing these foundational principles and turning data quality from an afterthought into a core business imperative.
Ready to move from theory to implementation? The most effective data cleaning best practices are powered by tools that automate, monitor, and scale your quality initiatives. DATA-NIZANT provides a unified platform designed to embed these principles directly into your workflows, offering advanced data profiling, automated validation, and collaborative quality management. Discover how DATA-NIZANT can help you build the trusted data foundation your business deserves.

