
At its core, the transformer is a deep learning model that reads entire sequences of data, like sentences, all at once. Unlike older models that had to process information one word at a time, transformers use a special mechanism called self-attention. This allows them to weigh the importance of every single word against all the others, capturing rich contextual relationships in one go.
This ability to process everything in parallel is what fuels today's most powerful AI, from ChatGPT to the language translation services we use every day.
The Shift Away From Sequential Processing
Before transformers, the world of natural language processing (NLP) was all about sequential models. Think of a Recurrent Neural Network (RNN) or a Long Short-Term Memory (LSTM) network as someone reading a book one word at a time. By the time they get to the last page, they’ve probably forgotten crucial details from the first chapter.
This one-word-at-a-time approach was a massive bottleneck. These models struggled to learn long-range dependencies—those subtle but critical connections between words that are far apart in a sentence or paragraph. This made complex tasks, like translating long documents or writing coherent articles, a real challenge.
To give you a clearer picture, let's compare these older approaches with the transformer model.
Transformer vs Traditional RNN/LSTM Architectures
| Feature | Traditional Models (RNN/LSTM) | Transformer Architecture |
|---|---|---|
| Data Processing | Sequential (one token at a time) | Parallel (processes all tokens at once) |
| Contextual Understanding | Limited; context fades over long sequences | Deep; captures relationships across the entire input |
| Long-Range Dependencies | Struggles to connect distant words | Excels at connecting distant words via self-attention |
| Training Speed | Slow due to its sequential nature | Highly parallelizable and much faster on GPUs |
| Key Mechanism | Recurrence (hidden states passed sequentially) | Self-attention (weighing the importance of all words) |
As you can see, the transformer didn't just offer an incremental improvement; it represented a fundamental rethinking of how machines could process language.
The Breakthrough Paper
Everything changed in 2017 with a groundbreaking paper titled, "Attention Is All You Need." The authors threw out the entire recurrence-based design. Instead of plodding along sequentially, their new model could look at every piece of the input data at the exact same time.
This paradigm shift brought two huge advantages:
- Parallelization: Since the model no longer had to wait for the previous word's calculation to finish, training became exponentially faster on modern hardware like GPUs.
- Deeper Context: The core mechanism, self-attention, gave the model a complete, interconnected map of the entire input right from the start.
This wasn't just a performance boost; it fundamentally altered how we build language models. It solved the long-standing problem of long-range dependencies by giving the model a "bird's-eye view" of the text, enabling a much richer grasp of context. Today, this architecture is the undisputed backbone of virtually all state-of-the-art large language models (LLMs).
To really get what makes the transformer architecture tick, we need to look under the hood at its two main parts: the Encoder and the Decoder.
Think of them as a highly specialized team. The Encoder is the diligent analyst, meticulously reading and understanding the input text. Its only job is to process the entire sentence at once, creating a rich numerical representation—a dense vector—that captures not just the words, but the meaning and context between them. This isn't just a simple list; it's a sophisticated summary packed with relational information.
Then you have the Decoder, the articulate writer of the team. It takes that detailed summary from the Encoder and gets to work. Its goal is to generate the output, whether that’s translating the sentence, answering a question, or finishing a story. It leans on the Encoder's deep contextual understanding to produce a relevant and coherent result, one word at a time.
This diagram shows how data flows between these two parts, and you can see how concepts like self-attention are right at the heart of the process.
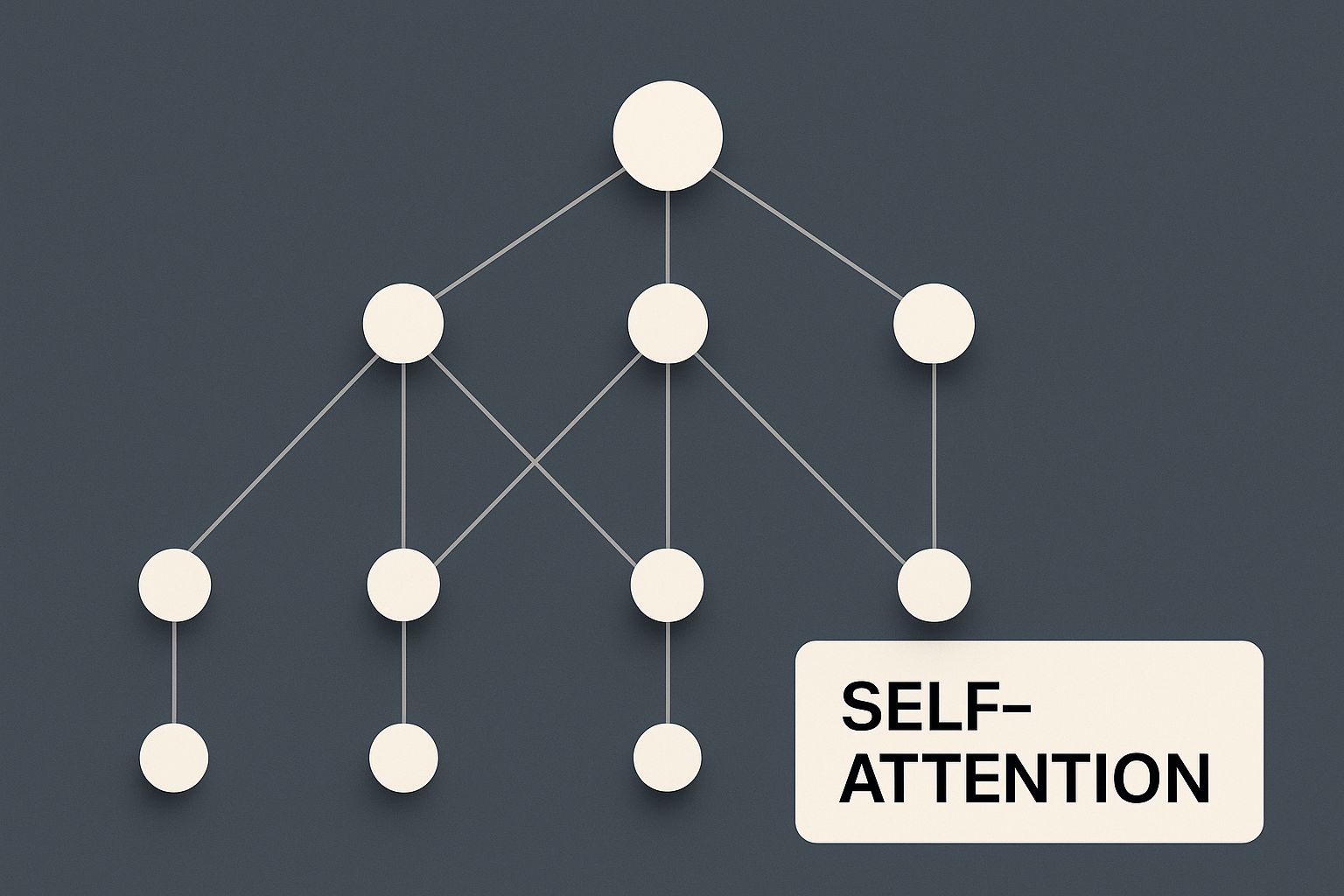
As the visual shows, it’s not a straight line from A to B. It’s a complex network where information is refined through multiple layers, all built on the foundation of self-attention, which makes this deep contextual analysis possible.
The Role of Positional Encoding
So, transformers process all words in a sentence simultaneously. This is great for speed, but it created a big problem: the model had no natural sense of word order. To the machine, "the dog chased the cat" and "the cat chased the dog" looked identical. This is where Positional Encoding comes in as a clever fix.
Before the input ever reaches the Encoder, a unique positional "tag" is added to each word's embedding. This tag is just a mathematical vector that essentially tells the model where each word sits in the sequence. It's like adding a unique timestamp to every word, allowing the model to preserve the original sentence structure and grammatical sense.
Key Insight: Positional Encoding is the trick that injects sequential information into a system designed for parallel processing. Without it, the transformer would understand the words but be clueless about their order, turning coherent sentences into a meaningless jumble.
Layers and Feed-Forward Networks
Neither the Encoder nor the Decoder is a single, monolithic block. They are actually stacks of identical layers piled on top of each other. The original "Attention Is All You Need" paper, for example, used a stack of six layers for both the Encoder and the Decoder. Stacking layers is what allows the model to build up progressively more abstract and complex representations of the text.
Each of these layers, in both the Encoder and Decoder, contains two main sub-components:
- A Self-Attention Mechanism: This is the star of the show, which we'll get into next. It's responsible for weighing the importance of different words relative to each other.
- A Feed-Forward Network: After the attention mechanism has done its thing, the output is passed through a simple, but vital, feed-forward neural network (FFN).
The FFN takes the context-rich output from the attention layer and applies another round of processing. What’s interesting is that the FFN in each layer works on each word position independently. This helps to further refine the contextual information before it's passed up to the next layer in the stack, ensuring that with each step, the model's understanding gets deeper.
How Self-Attention Powers Modern AI

If you've ever wondered how models like ChatGPT seem to just get what you're asking, the answer often comes down to a mechanism called self-attention. It's the secret sauce that gives the transformer architecture its uncanny ability to grasp context.
Self-attention lets a model look at any word in a sentence and instantly measure its relationship to every other word—no matter how far apart they are.
Take this sentence: "The robot picked up the ball because it was heavy." A human instantly knows "it" refers to "the ball." Self-attention gives an AI model this same superpower. It mathematically links "it" back to "ball" with a high score, while giving a low score to the less likely candidate, "robot."
This was a major break from older models. The original transformer design threw out the old playbook of recurrence and convolutions, relying entirely on attention. This not only improved context but also allowed the model to process all parts of the input at once, a massive leap in efficiency. You can get the full story on this architectural shift from the history of the transformer architecture on Wikipedia).
The QKV Model Demystified
So, how does this actually work under the hood? Self-attention uses a clever system based on three vectors for each and every word: a Query, a Key, and a Value.
Think of it like a hyper-efficient library lookup.
- Query (Q): This is a word asking a question. For the word "it," the query is essentially, "What in this sentence do I refer to?" It's actively seeking a connection.
- Key (K): This is like the label on a filing cabinet. Every other word has a Key that announces, "This is what I am." The "ball" Key signals its identity as a noun and an object in the sentence.
- Value (V): This is the actual substance inside the cabinet. It's the meaningful information the word carries, ready to be used once a match is found.
To find the right connection, the model takes the Query from one word and compares it against the Keys of all the other words. A high match results in a high attention score. These scores then determine how much of each word's Value gets blended into a new, context-rich representation for the original word.
Multi-Head Attention for a Richer View
A single self-attention mechanism is powerful, but it’s like asking just one expert for their opinion—they might miss something. To get a more complete picture, transformers use Multi-Head Attention.
This technique runs the whole Query, Key, and Value process several times in parallel, but each run gets its own unique perspective. It’s like assembling a team of specialists to analyze the sentence, all at the same time.
Analogy in Action: Imagine one attention "head" is a grammarian focused on subject-verb agreement. Another is a linguist looking at semantic meaning (what objects are being discussed). A third is an editor laser-focused on pronoun references.
By running, say, eight or sixteen of these attention heads at once, the model weaves a much richer and more nuanced web of connections. Each head spits out its own context-aware vector, and these are all combined to give the model a multi-faceted understanding that a single head could never achieve. This is a core reason why the transformer architecture explained today delivers such impressive results.
The Evolution of Transformer Models
The original "Attention Is All You Need" paper didn't just introduce a new model; it kicked off a Cambrian explosion in AI research. While the paper laid out the complete encoder-decoder blueprint, the AI community almost immediately started tinkering, pulling it apart, and rebuilding it in specialized ways.
This wasn't just random experimentation. Different problems demand different tools. The full transformer, while powerful, wasn't always the most efficient choice. Why use the whole toolbox when a single wrench will do? Researchers realized they could get better performance on specific tasks by using only the components they actually needed. This practical insight led to three distinct families of transformer models that dominate the field today.
The Three Pillars of Modern Transformers
These architectural splits created a clear division of labor among models, allowing each to become an expert in its domain. To better understand this, let's compare the three main types.
Key Transformer Model Variants
| Model Type | Primary Function | Famous Examples |
|---|---|---|
| Encoder-Only | Understanding and analyzing text (Comprehension) | BERT, RoBERTa, ALBERT |
| Decoder-Only | Generating new text from a prompt (Creation) | GPT series, BLOOM, LLaMA |
| Encoder-Decoder | Transforming an input sequence into an output sequence (Translation) | T5, BART, Original Transformer |
This specialization was a game-changer. It allowed models to be not just powerful, but also efficient and perfectly suited for their intended jobs.
Encoder-Only Models: The Readers
First up are the Encoder-only models, with Google's BERT (Bidirectional Encoder Representations from Transformers) being the most famous pioneer. Think of these models as expert "readers." They completely discard the decoder and focus exclusively on the encoder stack's ability to build a deep, contextual understanding of text.
What makes them so good at this? They can see the entire sentence at once—both the words that come before and after a specific point. This bidirectional context is their superpower, making them perfect for tasks that require true comprehension.
- Sentiment Analysis: Figuring out if a product review is positive or negative by catching subtle nuances in language.
- Named Entity Recognition: Scanning a document and identifying all the people, places, and organizations mentioned.
- Search Query Understanding: Grasping the real intent behind your search to give you better results.
These models are masters of analysis, not creation. They digest text and output rich numerical representations, which are then fed into a simpler machine learning model to make a final decision, like classifying a sentence or identifying an entity.
Decoder-Only Models: The Writers
On the other side of the coin, we have the Decoder-only models. This is the family that includes the incredibly popular GPT (Generative Pre-trained Transformer) series from OpenAI. These are the "creative writers" of the AI world. They're built entirely from the decoder stack and are fine-tuned for one thing: generating new, coherent text.
They work by predicting the very next word based on all the words that came before it—a process called autoregression. This makes them phenomenal at open-ended tasks where the goal is to produce fluent, human-like language. This is the magic behind everything from drafting emails and writing articles to powering the conversational skills of the AI chatbots we interact with daily.
These models can be further specialized for all sorts of writing styles and knowledge domains. In fact, learning how to fine-tune an LLM is one of the most powerful ways to adapt these models for specific business needs.
Key Takeaway: The split into different architectural families was a crucial step in the transformer's journey. It created a world where some models are highly specialized for understanding existing text (Encoders), while others are masters of generating new text (Decoders), setting the stage for the incredibly diverse and capable AI tools we have today.
Real-World Applications of Transformers
All the theory behind encoder stacks and attention scores really comes to life in the tools you probably use every single day. The transformer architecture is the quiet engine powering a huge slice of modern AI, bridging the gap from abstract concepts to real, tangible impact.
This is because its core strengths—processing information in parallel and deeply understanding context—make its influence both clear and widespread.
For instance, when you use a service like Google Translate, you're watching a transformer in action. It captures subtle nuances and idiomatic expressions far better than older methods ever could. Instead of just a word-for-word swap, it grasps the entire sentence's meaning, which is why the results feel so much more natural and accurate.
Powering Conversation and Creation
Virtual assistants have also become way more capable thanks to transformers. When you chat with Siri or Alexa, the transformer architecture is what allows for more natural, context-aware conversations. The model can actually remember what you said a few sentences ago, letting you ask follow-up questions without the interaction feeling stiff and robotic. That ability to maintain context is a direct result of the attention mechanism.
And in the world of software development, the impact is just as significant.
- Code Generation: Tools like GitHub Copilot use transformers to analyze the code you've already written. They can then suggest not just the next line, but entire functions and logical blocks, which can seriously speed up development.
- Bug Detection: By treating code as a language, transformers can spot potential errors or funky patterns that a human developer might overlook. Think of it as a powerful proofreading assistant for your code.
Key Insight: The real magic of transformers is their versatility. The same fundamental architecture that can translate German to English can also write Python code or power a chatbot. This just goes to show how well it can master different types of sequential data.
The Rise of Generative AI
The evolution of decoder-only models, in particular, kicked off a massive wave of creative applications. The release of GPT-3 by OpenAI in 2020 was a huge moment—a transformer-based model with an incredible 175 billion parameters. Its ability to generate coherent and contextually rich text on almost any topic showed everyone the immense potential of this architecture. You can get a detailed look at how these models operate in our guide to the power of large language models.
This explosion in generative AI was really fueled by scaling up decoder-only models. It proved that with enough data and computing power, transformers could do things that once felt like science fiction. As people started using simple text prompts to create everything from poetry and music to functional websites, the practical power of the transformer architecture explained in this guide became impossible to ignore.
Common Questions About Transformer Architecture
As transformers have taken center stage in modern AI, a lot of good questions come up. The concepts can feel a bit abstract at first, but walking through the common sticking points is the best way to build a solid intuition for why this architecture is so powerful.
One of the first questions people usually ask is: what really separates a transformer from an older model like an RNN? The big idea is parallel vs. sequential processing. An RNN chugs through a sentence one word at a time, kind of like how we read. A transformer, on the other hand, looks at the entire sentence all at once.
This parallel approach isn't just faster on modern hardware; it’s also much better at spotting connections between words that are far apart, a major weakness of older models.
Why Was Self-Attention So Important?
That naturally leads to the next question: why was self-attention such a game-changer? Self-attention is the secret sauce that makes this parallel, all-at-once processing possible. It's the mechanism that lets the model mathematically score how relevant every single word in a sentence is to every other word.
Think about the sentence, "The server is busy because it has too many requests." Self-attention is what helps the model know, with high confidence, that "it" refers to "server" and not to "requests." Getting this right was a massive headache for older models. Self-attention offered an elegant and scalable way to understand these deep contextual links, which is everything when it comes to understanding language.
The arrival of transformers in 2017 kicked off an explosion in AI and NLP. They quickly became the foundation for the massive language models we see today, like OpenAI's GPT series. This was a major shift toward "foundation models"—huge models trained on web-scale data that can be adapted for countless different tasks. If you're curious to learn more, DataCamp has a great tutorial on how transformers work.
Core Insight: Self-attention wasn't just another feature. It was a complete paradigm shift. It threw out the slow, step-by-step "memory" of RNNs and replaced it with an instant, interconnected web of relationships. This unlocked a much deeper level of language comprehension.
What Happened to Encoder-Only Models Like BERT?
Another point of confusion is why decoder-only models like GPT seem to have taken over, while encoder-only models like BERT are less in the spotlight. BERT was a beast for tasks that required a deep understanding of text, like search and sentiment analysis. But the industry's focus quickly shifted toward generation.
Decoder-only models are built to do one thing exceptionally well: predict the next word. This makes them perfect for creating new content, whether it's powering a chatbot or writing an article. The industry’s push for general-purpose, conversational AI simply gave the "writer" (the decoder) a huge advantage over the "reader" (the encoder).
Of course, building and deploying these massive models has become a whole field of its own. You can dive deeper into this topic in our guide on mastering AI model management.
At the end of the day, the different architectures aren't really competing—they're specializing. The transformer architecture explained in this guide is more of a flexible blueprint than a rigid design. The future will almost certainly bring more hybrid models that cherry-pick the best of all these approaches for new, incredibly powerful applications.
At DATA-NIZANT, we demystify the complex world of AI and data science. Explore our expert-authored articles and in-depth analyses to stay ahead of the curve. Visit us at https://www.datanizant.com.

