
Breaking Down Data Science Fundamentals

Entering the field of data science can feel overwhelming. This section clarifies the core components, cutting through the noise to examine the skills practitioners need to tackle real-world challenges. We'll explore how statistics, coding, and domain expertise combine to create effective solutions, with a focus on practical application.
Key Building Blocks of Data Science
Data science isn't simply about complex algorithms. It's about utilizing the appropriate tools to extract meaningful insights from data. This means understanding the underlying principles of several key areas. For instance, statistical thinking is crucial for interpreting data and forming accurate conclusions.
Data preparation, while sometimes the most time-consuming part of the process, is also vital. Mastering the process of cleaning and transforming data is just as important as developing complex models. It ensures your results are accurate and dependable.
- Statistical Thinking: Understanding concepts like probability distributions, hypothesis testing, and regression analysis is essential. It's not just about calculating numbers; it's about understanding why you're using specific methods and how to understand the outcomes.
- Coding Skills: Proficiency in languages like Python or R, along with relevant libraries, is crucial. You need to be able to write efficient code for data cleaning, transformation, and model building.
- Domain Expertise: Understanding the specific industry context of the data, whether it's business, healthcare, or finance, is key. This specialized knowledge allows data scientists to pose the correct questions and interpret the findings in a meaningful way.
The Growing Importance of Data Science
Demand for data science skills has skyrocketed, reflecting the increasing importance of data-driven decisions in numerous industries. Job postings requiring a data science degree saw a dramatic increase, rising from 47% in 2024 to 70% in 2025.
This 23% jump shows how much businesses rely on data science for shaping their strategies and achieving their objectives. For more in-depth information, see this helpful resource: Data Scientist Job Outlook 2025
Data Science vs. AI and Machine Learning
Data science often intersects with artificial intelligence (AI) and machine learning (ML), but they are distinct fields. AI and ML concentrate on creating intelligent systems and algorithms. Data science, on the other hand, uses these tools, along with statistical analysis and domain knowledge, to analyze and interpret data. For a closer look at the differences, check out this article: Data Science vs. Artificial Intelligence & Machine Learning: What's the Difference?
These fundamental data science concepts provide a solid base for a successful career in the field. Mastering these core ideas and continually adapting to industry changes are key to making a real difference as a data scientist.
Statistical Thinking That Actually Gets Results

Statistical thinking is fundamental to data science. But knowing formulas isn't enough. This section explores how practical experience bridges the gap between theory and application, showing how seasoned data scientists use statistical concepts in their daily work.
Essential Statistical Concepts For Data Scientists
Certain statistical concepts are crucial for any data scientist. These aren't just theoretical ideas; they are practical tools used every day to tackle real-world problems. A deep understanding of these concepts is key to extracting meaningful insights from data.
-
Probability Distributions: These describe the probability of different outcomes. The normal distribution, often depicted as a bell curve, frequently models things like height and weight. Selecting the appropriate distribution is vital for accurate analysis.
-
Hypothesis Testing: This process starts with a hypothesis about the data. Statistical tests then determine how likely that hypothesis is to be true. A/B testing in marketing relies heavily on hypothesis testing. For example, it helps determine if changes to a website's design improve conversion rates.
-
Regression Analysis: This method models the relationship between different variables. You might use regression to predict house prices based on factors like size, location, and age. Choosing the right regression model depends on the specifics of your data and research question.
Applying Statistical Thinking in Practice
Experienced data scientists do more than just crunch numbers; they critically assess data and ask insightful questions. They understand the why behind statistical techniques, not just the how. This deeper understanding is more valuable than memorizing formulas. It empowers them to make informed decisions based on solid statistical reasoning.
For instance, understanding the assumptions behind different statistical tests is essential. Using a test when its assumptions aren't met can lead to inaccurate conclusions. This methodical approach is what sets highly effective data scientists apart. The global data science platform market is projected to grow from $120.49 billion in 2024 to $485.95 billion by 2029, a CAGR of 33.1%. This impressive growth highlights the rising demand for skilled data professionals. Learn more about this trend: Find more detailed statistics here.
Developing Statistical Intuition
Developing statistical intuition requires both time and practice. It's about recognizing patterns, identifying potential biases, and understanding the limits of statistical methods. Working with real-world datasets and case studies is one way to hone this intuition.
Staying current with the latest techniques and advancements in the field is equally important. Data science is constantly changing. Continuous learning through conferences, research papers, and engagement with the data science community is crucial.
The following table summarizes some key statistical concepts used in data science:
Key Statistical Concepts in Data Science
This table outlines essential statistical concepts that form the foundation of data science practice.
| Statistical Concept | Application in Data Science | Importance Level |
|---|---|---|
| Probability Distributions | Modeling data, making predictions, understanding data distribution | High |
| Hypothesis Testing | A/B testing, validating assumptions, determining statistical significance | High |
| Regression Analysis | Predictive modeling, understanding relationships between variables | High |
| Confidence Intervals | Estimating population parameters, quantifying uncertainty | Medium |
| P-values | Assessing statistical significance, making decisions based on hypothesis tests | Medium |
This table highlights the core concepts and their importance in data science. Understanding these concepts is crucial for effective data analysis and interpretation.
This approach empowers data scientists to confidently address complex business challenges and deliver reliable insights. The ability to apply statistical thinking effectively is what turns raw data into usable knowledge.
The Art of Data Preparation Nobody Tells You About

Data preparation is the often-overlooked cornerstone of data science. While model building and generating insights grab the headlines, experienced data scientists know that up to 80% of their time is spent cleaning and preparing data. This section explores the practical techniques that separate expert data scientists from novices when tackling the inevitable messiness of real-world data.
Handling Missing Values and Outliers
Real-world datasets are rarely pristine. Missing values and outliers are common occurrences that can significantly impact your analysis. Addressing these issues is a critical first step in data preparation. Consider, for instance, customer purchase data where some customer ages are missing. Ignoring these missing values can lead to skewed and inaccurate results.
There are various ways to handle missing values. You can replace them with the average age, employ a more complex imputation method, or, if the missing data is extensive, remove those entries entirely. Each strategy has its pros and cons, and the optimal approach depends on the specific dataset and the objectives of the analysis. Outliers, data points that deviate significantly from the norm, also require careful consideration. They can indicate errors in data collection or genuinely unusual occurrences.
Transforming Raw Data Into Analysis-Ready Assets
Raw data is frequently in a format that is not suitable for immediate analysis. Transforming this raw data into a usable format is essential for data preparation. It's similar to prepping ingredients for a recipe. You wouldn't throw a whole onion into a soup; you'd chop it first. Data requires similar processing and transformation.
This might involve converting data types, creating new variables from existing ones (feature engineering), or scaling and normalizing numerical data. For example, categorical data like "customer type" can be converted into numerical codes for use in machine learning algorithms. Robust data validation is essential in this phase. You can find excellent resources on data validation best practices.
Efficient Workflows and Documentation
Effective data scientists cultivate efficient workflows for data preparation. They utilize tools and techniques to automate repetitive tasks, saving valuable time and minimizing the risk of errors. However, automation should not sacrifice quality. Implementing checks and balances to maintain data accuracy and consistency throughout the process is paramount.
Thorough documentation is equally vital. Clear documentation saves significant time when revisiting projects or collaborating with colleagues. It should detail the steps taken during data preparation, the rationale behind those choices, and any challenges encountered. This facilitates easy replication and mitigates the introduction of errors down the line.
The Competitive Advantage of Systematic Data Preparation
A systematic approach to data preparation is more than just cleaning data; it's about establishing a foundation for reliable insights. Mastering data preparation empowers you to make informed decisions, develop more accurate models, and ultimately deliver greater value. In an increasingly data-driven world, this becomes a true competitive edge.
Choosing the Right Tools for Your Data Science Arsenal
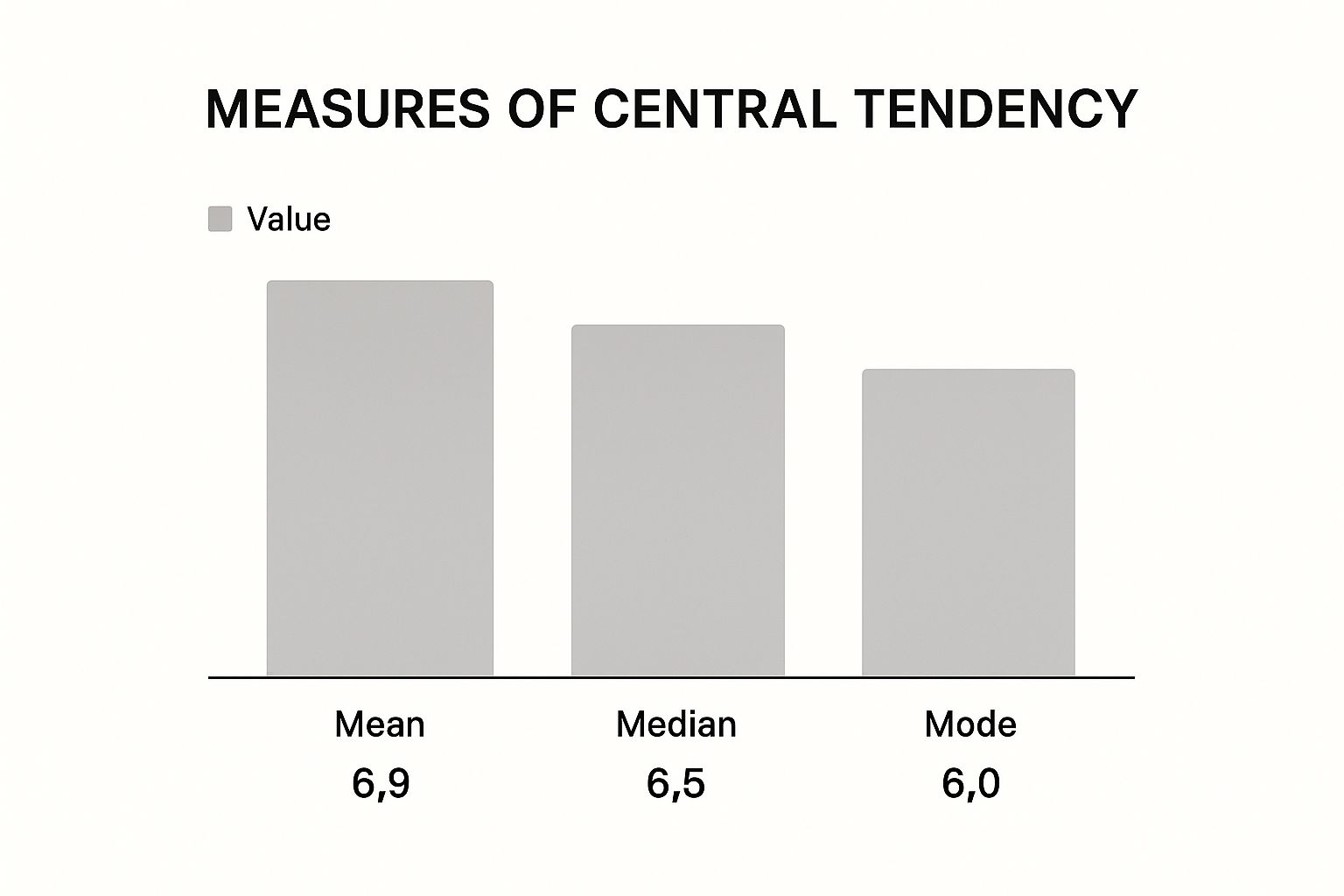
The infographic above illustrates the mean, median, and mode for a sample dataset. Notice how the mean and median are relatively close, while the mode is considerably lower. This suggests a concentration of data points around the center, but with a noticeable cluster of lower values impacting the mode. Just as a carpenter selects the appropriate tool for a task, a data scientist must carefully choose the right tools for each project. This section explores how professionals strategically select and combine various tools based on project needs, going beyond mere personal preference.
Key Tools and Technologies
Data scientists employ a diverse range of tools, each with its own set of strengths and weaknesses. Understanding these nuances is crucial for selecting the most effective approach for a given task. Python and R are two prominent programming languages in the data science field, each offering distinct advantages. Python is renowned for its versatility and extensive libraries such as Pandas and Scikit-learn, making it ideal for machine learning and data manipulation. R, on the other hand, is preferred for statistical computing and data visualization, particularly with packages like ggplot2.
SQL is essential for managing and querying relational databases, a frequent task for data scientists working with extensive datasets. Additionally, familiarity with specialized libraries can significantly improve efficiency when working with particular data types or analytical methods. This adaptability enables data scientists to tackle diverse challenges and choose the best tools for each specific situation. For those looking to expand their skillset, this resource might be helpful: How to master R and Python in data science.
To help illustrate the differences between these key languages, let's take a look at the following comparison:
Comparison of Popular Data Science Programming Languages
A detailed comparison of the strengths, weaknesses, and ideal use cases for major programming languages used in data science.
| Language | Strengths | Weaknesses | Best Use Cases | Learning Curve |
|---|---|---|---|---|
| Python | Versatile, extensive libraries (Pandas, Scikit-learn), large community support | Can be slower than compiled languages, some specialized statistical functions may require additional packages | Machine learning, deep learning, data manipulation, scripting, automation | Relatively easy |
| R | Powerful for statistical computing and visualization (ggplot2), strong academic community | Can be less versatile than Python for general-purpose programming, steeper learning curve for some | Statistical modeling, data visualization, research, specialized statistical analysis | Moderate to steep |
| SQL | Essential for database management and querying, highly efficient for data retrieval | Not ideal for complex data manipulation or statistical modeling, syntax can be specific to database systems | Data extraction, data warehousing, database management, reporting | Moderate |
As you can see, each language offers unique advantages, reinforcing the importance of selecting the right tool for the job.
Matching Tools to Project Needs
A proficient data scientist doesn't limit themselves to a single tool. They strategically integrate various technologies based on the project's objectives. For example, they might use SQL to retrieve data from a database, Python to clean and preprocess it, and then R to conduct statistical analysis and generate visualizations. This adaptable approach ensures both efficiency and accuracy.
The data science and predictive analytics market is experiencing rapid growth. Valued at $25.24 billion in 2025, it's projected to reach $179.05 billion by 2037, growing at a CAGR of 18.8%. For more in-depth analysis of this expanding market, see: Find more detailed statistics here. This growth highlights the increasing demand for professionals skilled in using data science tools.
Prioritizing Transferable Skills
While specific tools may become outdated, fundamental skills such as statistical thinking, problem-solving, and communication remain crucial. Focusing on these transferable skills will be beneficial throughout your career. For instance, understanding data cleaning and preparation is vital irrespective of the tools used. Solid data preparation is fundamental to data science success, and you can learn more about implementing data validation best practices. Likewise, the ability to effectively communicate your findings is always valuable, regardless of the presentation platform.
Building a Data Science Toolkit
Building a data science toolkit requires a balanced approach. Begin by mastering fundamental programming languages and basic statistical concepts. Then, explore specialized tools and libraries aligned with your career goals. If you're interested in machine learning, for instance, delving deeper into Python's Scikit-learn would be a valuable next step. Continuously evaluating new tools and techniques and aligning them with current trends and your evolving skills is essential for professional development. This continuous learning ensures your toolkit remains relevant and effective in the dynamic field of data science.
Machine Learning Concepts That Actually Matter
Building on the fundamentals of data science, machine learning offers a powerful toolkit for uncovering insights and making predictions. This section goes beyond the hype, focusing on the core concepts that are truly important for practicing data scientists.
Algorithm Selection: Choosing the Right Tool for the Job
Choosing the right machine learning algorithm is just as important as selecting the right tool for any other job. There's no single solution that fits every situation. A linear regression model might work well for predicting a continuous variable like sales revenue, but a support vector machine might be more effective for classification tasks, such as image recognition.
Experienced data scientists know to avoid overly complex models when simpler ones will do. They prioritize efficiency and interpretability, carefully considering the specific problem and the nature of the data before choosing an algorithm. This often involves testing multiple algorithms and comparing how they perform.
Model Evaluation: Measuring Success
Building a machine learning model is just the first step. Evaluating its performance is equally crucial. Standard metrics like accuracy, precision, and recall offer different perspectives on how effective a model is.
For example, a model with high accuracy could still perform poorly if it consistently misclassifies a particular data category. This highlights why it's essential to consider a range of evaluation metrics. Cross-validation techniques, involving splitting the data into subsets for training and testing, help confirm a model's reliability and prevent overfitting, where a model performs well on training data but poorly on new, unseen data.
Feature Selection and Engineering: Refining the Inputs
The quality of a machine learning model's output depends heavily on the quality of its input. Feature selection involves selecting the most relevant variables (features) for the model. Too many irrelevant features can add noise and hinder performance.
Feature engineering, on the other hand, involves creating new features from existing ones, which can often improve the model's ability to understand complex relationships within the data. For example, combining "date of birth" and "current date" to create an "age" feature might be more informative for the model. This careful refinement of the input data is essential for getting the best results.
Addressing Common Challenges: Practical Solutions
Real-world machine learning often involves challenges like imbalanced datasets, where one class of data is much larger than another, and model interpretability, which makes understanding how a model makes predictions difficult. Fortunately, practical solutions exist for these issues. Techniques like oversampling or undersampling can address imbalanced datasets. Methods like SHAP values can improve model interpretability. Data scientists frequently use hyperparameter tuning, adjusting the model's settings to optimize its performance. This practical approach builds reliable models and extracts valuable insights from the data. Choosing the right platform is essential for efficient data management. Customer Success Platforms are a key element to consider. You might also be interested in how to master machine learning infrastructure. This deeper exploration will help you develop a robust and effective data science toolkit. By focusing on these core machine learning concepts, you can improve your model's performance, tackle challenges, and ultimately make better decisions.
Turning Data Into Stories That Drive Decisions
Data analysis, no matter how insightful, can be ineffective if not communicated clearly. This section explores how data scientists transform complex findings into compelling narratives that inspire action. We'll examine practical visualization techniques that highlight key insights without overwhelming your audience, whether you're presenting to technical colleagues or executive stakeholders.
Identifying the Story Within Your Data
Every dataset holds a unique story waiting to be discovered. Successful data scientists are skilled at uncovering and communicating this narrative. This process begins with understanding your audience. What are their main concerns? What questions are they hoping to answer? For instance, if you're presenting to marketing executives, they're likely more interested in customer behavior patterns than the intricate technical details of your model.
Once you've pinpointed the core message, structure your presentation around it. Start by presenting the most impactful discoveries and bolster them with clear, concise visuals. Think of it as crafting a story: introduce the problem, present your analysis, and conclude with actionable recommendations. This focused approach keeps your audience engaged and ensures your message resonates.
Visualization Techniques: Clarity Over Complexity
Data visualization is essential for making complex data understandable. Effective visualization, however, prioritizes clarity over complexity. Avoid overwhelming your audience with excessive information. Select the appropriate chart type for your data: bar charts for comparisons, line charts for trends over time, and scatter plots for relationships between variables.
If you're comparing sales performance across different regions, for example, a straightforward bar chart is more effective than a complex 3D pie chart. Maintain clean and uncluttered charts, with clear labels and titles. Emphasize the main takeaway from each visual. Remember, the aim is to illuminate, not obfuscate.
Communication Pitfalls and How to Avoid Them
Even the most experienced presenters can stumble into communication traps. One common mistake is using excessively technical jargon. While precision is important, avoid overwhelming your audience with unfamiliar terminology. Instead, explain technical concepts using plain, concise language and relatable analogies. If your audience struggles with a specific term, offer a brief, simple explanation without disrupting the flow of your presentation.
Another pitfall is presenting too much data at once. This can overload the audience and weaken your message. Concentrate on the most important findings and use visuals to support them. If you’re analyzing website traffic, for instance, concentrate on crucial metrics like bounce rate and conversion rate, rather than presenting a flood of raw data. This focused approach ensures your audience absorbs the most relevant information.
Handling Challenging Questions: Confidence and Transparency
Be ready for questions, particularly from technical audiences. If you don't know the answer to a question, it's perfectly acceptable to admit it. It's preferable to acknowledge your limitations than to offer an inaccurate or misleading answer. Offer to follow up with the answer later. This demonstrates integrity and fosters trust. Moreover, be upfront about any limitations or assumptions in your analysis. Transparency strengthens credibility and allows for a richer, more nuanced discussion of your results.
These essential communication principles can significantly improve your effectiveness in the field of data science. Visit DATA-NIZANT to explore a collection of resources on AI, machine learning, and data science and continue developing your data science expertise.




