
Top 8 Natural Language Processing Applications in 2025
Beyond the Buzzwords: Unpacking How Machines Understand Our World
Natural Language Processing (NLP) has quietly revolutionized how we interact with technology, evolving from a niche academic field into the engine behind our daily digital experiences. While terms like AI and machine learning are common, the specific natural language processing applications are what truly bridge the gap between human communication and machine intelligence. This article moves beyond generic descriptions to provide a deep, strategic analysis of eight major NLP domains that are reshaping industries.
We will dissect how these technologies function, explore innovative real-world examples from industry leaders, and provide actionable takeaways for businesses and developers. From the sophisticated conversational AI in your pocket to the complex systems that analyze market sentiment, we’ll uncover the ‘how’ and ‘why’ behind each application. Our goal is to offer tactical insights and replicable strategies you can use. For leaders looking to harness this power, understanding these applications is the first step toward building a competitive advantage. Prepare to see how NLP is not just changing the game, it’s building an entirely new one.
1. Chatbots and Virtual Assistants
Chatbots and virtual assistants are among the most recognizable natural language processing applications today. These AI-driven conversational interfaces, including well-known examples like Amazon’s Alexa and OpenAI’s ChatGPT, are designed to understand user queries in natural language and provide relevant, human-like responses. They serve a wide range of functions, from customer service and personal assistance to complex information retrieval and task execution.
How Chatbots Leverage NLP
The core functionality of these systems relies on several key NLP techniques. When a user provides input, the system first parses the text or speech to break it down into manageable components. It then applies intent recognition to understand the user’s goal (e.g., “book a flight”) and entity extraction to identify crucial details like dates, locations, or names (e.g., “to London,” “tomorrow”). Based on this understanding, the system retrieves information or triggers an action and generates a coherent, context-aware response.
The following infographic illustrates the fundamental workflow of how a chatbot processes a user’s request.
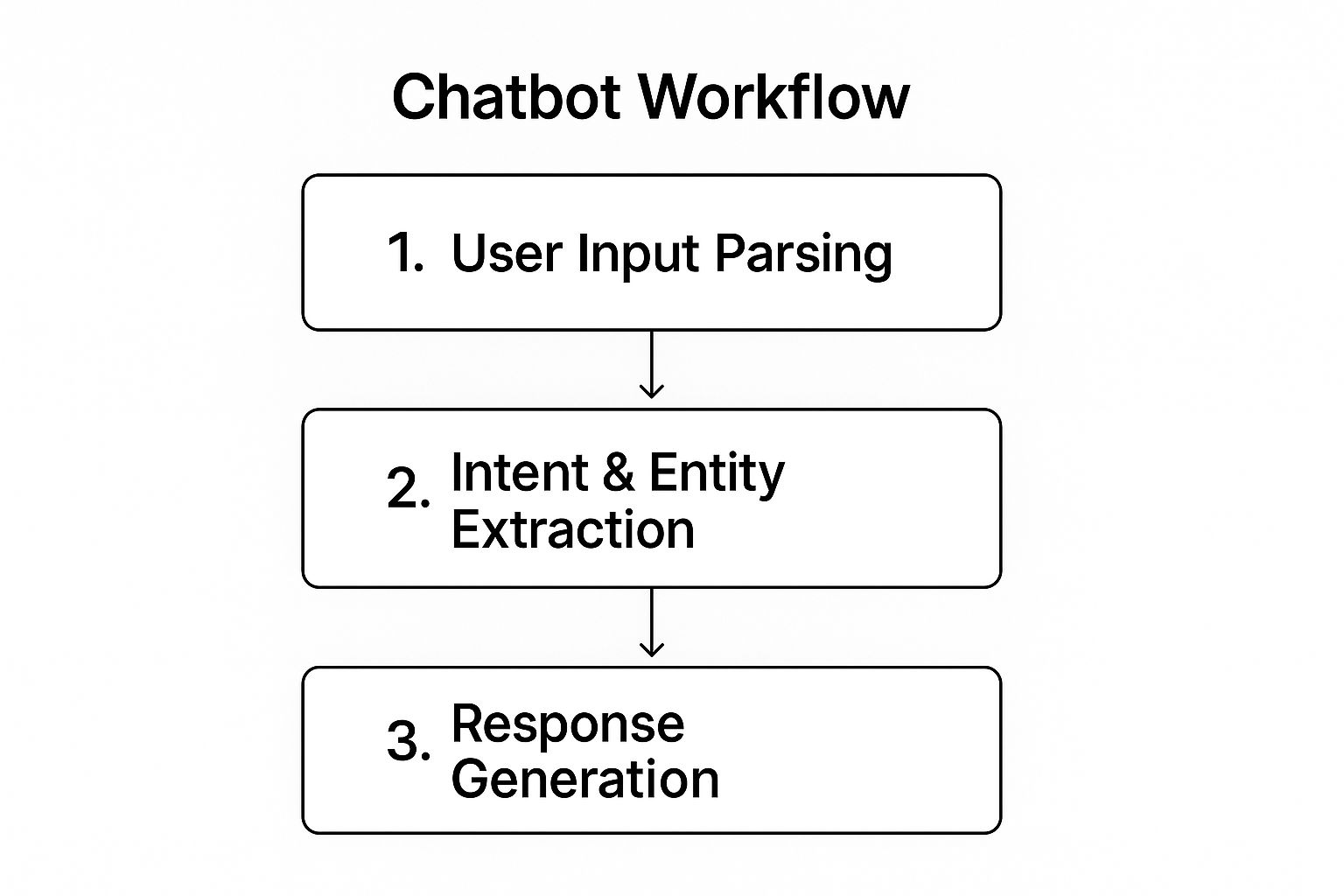
This streamlined process, from parsing input to generating a response, is the engine that powers effective conversational AI, enabling seamless interaction.
Strategic Implementation and Impact
For businesses, implementing chatbots can lead to significant improvements in efficiency and customer satisfaction. A banking chatbot, for instance, can handle thousands of simultaneous account inquiries, freeing up human agents for more complex issues. This not only reduces operational costs but also provides customers with 24/7 support. Success hinges on a well-defined strategy.
Actionable Takeaways:
- Design Clear Conversation Flows: Map out common user journeys and create logical conversation paths. Crucially, design robust fallback responses for when the bot doesn’t understand a query.
- Implement Escalation Paths: Ensure a seamless handover to a human agent when the chatbot reaches its limits. This prevents user frustration and maintains a high quality of service.
- Continuously Monitor and Train: Regularly analyze conversation logs to identify common failure points and areas for improvement. Use these real-world interactions to update and retrain your NLP models.
2. Machine Translation
Machine translation (MT) is a classic yet rapidly evolving natural language processing application that automatically converts text or speech from a source language to a target language. Modern systems, like Google Translate and DeepL, have moved beyond simple word-for-word substitution to advanced neural machine translation (NMT). These models analyze the full context of a sentence to capture grammar, nuances, and semantic meaning, producing remarkably fluent and accurate translations.

How Machine Translation Leverages NLP
At its core, NMT uses sophisticated deep learning models, often based on transformer architectures, to process entire sequences of text. The process involves an encoder that reads the source sentence and compresses its meaning into a numerical representation, or vector. A decoder then uses this vector to generate the translated sentence word by word in the target language, paying close attention to the context established by the encoder. This encoder-decoder framework allows the system to handle long-range dependencies and complex grammatical structures far more effectively than older statistical methods.
Strategic Implementation and Impact
For global businesses, machine translation is a transformative tool for breaking down language barriers and scaling international operations. E-commerce platforms can use it to instantly translate product descriptions for a worldwide audience, while multinational corporations can facilitate seamless internal communication across diverse teams. For example, a company like Microsoft integrates its Translator service into enterprise applications, enabling real-time translation in meetings and documents. The strategic goal is to make content universally accessible, accelerating market entry and improving global customer engagement.
Actionable Takeaways:
- Train Custom Models: For specialized fields like law or medicine, train a custom NMT model with your domain-specific terminology to significantly improve translation accuracy and relevance.
- Implement Human-in-the-Loop: For high-stakes content like legal contracts or marketing campaigns, use machine translation as a first draft. Implement a workflow where human translators post-edit the output to ensure quality and cultural appropriateness.
- Utilize Confidence Scores: Leverage translation confidence scores provided by many APIs. This allows you to automatically flag low-confidence translations for human review, optimizing resources while maintaining quality control.
3. Sentiment Analysis
Sentiment analysis, also known as opinion mining, is a powerful natural language processing application that computationally identifies and categorizes opinions expressed in a piece of text. This technology is crucial for businesses and organizations seeking to understand social sentiment, customer feedback, and brand reputation by automatically determining whether the underlying tone is positive, negative, or neutral. It operates on various scales, from analyzing an entire document to dissecting the sentiment toward specific features or aspects within a sentence.

How Sentiment Analysis Leverages NLP
At its core, sentiment analysis uses NLP to decode subjective information. The process often begins with text preprocessing to clean the data by removing irrelevant information. Then, a model classifies the text’s emotional polarity. This can be done through rule-based systems that use sentiment lexicons (lists of words with pre-assigned scores) or through machine learning models trained on vast datasets of labeled examples. More advanced techniques like aspect-based sentiment analysis can even identify specific opinions about different product features, for example, distinguishing that a customer loves a phone’s “camera” but dislikes its “battery life” within the same review.
Strategic Implementation and Impact
For businesses, sentiment analysis provides a direct line to the voice of the customer, transforming unstructured text from reviews, social media, and support tickets into actionable business intelligence. For example, a company like Brandwatch can monitor real-time Twitter sentiment during a product launch to gauge public reception and quickly address emerging negative trends. This capability allows organizations to proactively manage their brand reputation, refine marketing strategies, and improve products based on direct market feedback, moving from reactive problem-solving to proactive, data-driven decision-making.
Actionable Takeaways:
- Use Domain-Specific Lexicons: Generic sentiment dictionaries can fail to capture industry-specific jargon. Develop or use lexicons tailored to your domain (e.g., finance, healthcare) for higher accuracy.
- Handle Negations and Modifiers: Preprocess text to correctly interpret phrases like “not good” or “barely acceptable.” Simple models can misclassify these without rules that account for linguistic nuances.
- Combine Rule-Based and ML Models: Leverage a hybrid approach. Use rule-based systems for speed and clear logic, and use machine learning models for handling complex, nuanced text where rules fall short.
4. Text Summarization
Text summarization is one of the most powerful natural language processing applications, designed to automatically condense lengthy documents into concise, coherent summaries. These systems tackle information overload by distilling essential information, allowing users to grasp the main ideas of articles, reports, or legal documents without reading them in full. Tools like Google News, which provides quick summaries of articles, and academic paper summarizers showcase this technology’s value.
How Text Summarization Leverages NLP
Summarization systems primarily use two distinct methods. Extractive summarization identifies and pulls key sentences or phrases directly from the source text, ranking them based on importance and assembling them into a summary. Abstractive summarization, a more advanced approach, involves generating entirely new sentences that paraphrase and capture the core meaning of the original document, much like a human would. This requires sophisticated NLP models, such as transformers like Google’s PEGASUS or OpenAI’s GPT series, to understand context and generate fluent, accurate text.
Strategic Implementation and Impact
For businesses, automated summarization drives significant productivity gains. Financial analysts can quickly digest long market reports, legal teams can process case files faster, and researchers can stay current with vast amounts of literature. For instance, a legal tech firm can deploy a system to create executive summaries of complex contracts, reducing review time from hours to minutes. Success depends on selecting the right summarization method for the task and fine-tuning models on domain-specific data to ensure accuracy and relevance.
Actionable Takeaways:
- Combine Extractive and Abstractive Methods: For a balanced approach, use an extractive method to first identify key information, then use an abstractive model to rephrase it into a more natural and coherent summary.
- Fine-Tune on Domain-Specific Data: A generic summarization model may miss industry-specific nuances. Train your models on your own documents, such as internal reports or legal briefs, to improve performance.
- Validate Against Human-Generated Summaries: To ensure quality, regularly compare machine-generated summaries with those created by human experts. Use metrics like ROUGE (Recall-Oriented Understudy for Gisting Evaluation) to quantify performance and guide improvements.
5. Named Entity Recognition (NER)
Named Entity Recognition (NER) is a powerful information extraction technique that stands as a cornerstone of many sophisticated natural language processing applications. Its primary function is to automatically identify and classify named entities within unstructured text into predefined categories. These categories commonly include person names, organizations, locations, dates, monetary values, and other specific types of information, effectively transforming raw text into structured data.
How NER Leverages NLP
At its core, NER processes text to locate and categorize key pieces of information. The system scans sentences to identify potential entities, often using a combination of grammatical rules and statistical models. For example, in the sentence “Acme Corp. announced a $5 million investment in its London office on Tuesday,” an NER model would apply entity identification to pinpoint “Acme Corp.,” “$5 million,” “London,” and “Tuesday.” It would then use entity classification to label them as an organization, a monetary value, a location, and a date, respectively.
This process is fundamental for making sense of large volumes of text. By extracting structured entities, systems can organize information, populate databases, and enable more advanced analytical tasks. For a deeper dive into related text analysis methods, you can explore tutorials on advanced data extraction techniques.
Strategic Implementation and Impact
For businesses, integrating NER can unlock immense value from text-based data that would otherwise remain untapped. In the financial sector, NER models are used to scan earnings reports and news articles to quickly identify company names, key executives, and financial figures, providing analysts with critical data for market analysis. Similarly, legal teams use NER to automatically parse contracts and court documents to extract party names, effective dates, and jurisdictional clauses, drastically accelerating the due diligence process.
The success of an NER system depends on its accuracy and its relevance to a specific domain. A model trained on general news text may struggle with the specialized terminology found in medical records or scientific papers. Therefore, a strategic approach to implementation is crucial for achieving high performance.
Actionable Takeaways:
- Fine-Tune Pre-trained Models: Start with robust, pre-trained models from libraries like spaCy or Hugging Face, but fine-tune them on your domain-specific data. This customizes the model to recognize unique entities relevant to your industry, such as drug names or technical components.
- Combine Rule-Based and Statistical Methods: For highly predictable patterns like product codes or specific ID formats, supplement your statistical model with rule-based systems. This hybrid approach often yields higher accuracy than using either method alone.
- Implement an Annotation and Validation Loop: Use domain experts to review and correct the model’s predictions. This feedback loop, often part of an active learning strategy, continuously improves the model’s accuracy by focusing on its weakest areas.
6. Question Answering Systems
Question Answering (QA) systems are advanced natural language processing applications designed to provide precise, direct answers to questions posed in human language. Unlike standard search engines that return a list of documents, QA systems synthesize information from vast knowledge bases, documents, or the web to deliver a specific, contextual response. Prominent examples include Google Search’s instant answer boxes, the computational prowess of Wolfram Alpha, and the knowledge recall capabilities of Amazon’s Alexa.
How Question Answering Systems Leverage NLP
The power of a QA system lies in its ability to deeply comprehend a question and locate the exact information needed. The process begins with question analysis, where NLP models deconstruct the query to identify its type (e.g., “who,” “what,” “where”) and key entities. Next, the system performs information retrieval to scan indexed sources and find relevant passages. Finally, answer extraction techniques are used to pinpoint the precise phrase or sentence that directly answers the user’s question, which is then presented as a coherent response.
This sophisticated pipeline transforms raw data into actionable knowledge, making it a cornerstone of modern information access and one of the most impactful natural language processing applications today.
Strategic Implementation and Impact
For enterprises, implementing QA systems can revolutionize internal knowledge management and customer support. A QA system built on technical documentation can empower engineers to find specific solutions instantly, bypassing manual searches. This accelerates development cycles and reduces downtime. Similarly, customer-facing QA bots can resolve complex queries that standard FAQ chatbots cannot, improving first-contact resolution rates. Success requires a commitment to maintaining high-quality, up-to-date knowledge sources and robust evaluation.
Actionable Takeaways:
- Maintain High-Quality Knowledge Sources: The accuracy of your QA system is directly tied to the quality of its underlying data. Regularly update and curate your documents or knowledge base to ensure relevance and correctness.
- Implement Answer Verification: For critical applications, use ensemble methods or fact-checking layers to validate answers against multiple sources. This builds user trust and enhances reliability.
- Provide Source Attribution: Increase transparency by citing the source documents from which an answer was extracted. This allows users to verify information and explore the context further.
7. Speech Recognition and Synthesis
Speech recognition and synthesis are foundational natural language processing applications that bridge the gap between human speech and digital text. Speech-to-text (STT) systems, like those powering dictation software, convert spoken words into machine-readable text. Conversely, text-to-speech (TTS) technology, used in everything from GPS navigation to audiobook narration, generates natural-sounding human speech from text. These capabilities are crucial for creating voice-activated interfaces and accessibility tools.
How Speech Recognition and Synthesis Leverage NLP
These technologies rely on complex acoustic and linguistic models. For STT, the system first processes raw audio to clean up noise and isolate phonetic components. It then uses an acoustic model to map these sounds to phonemes and a language model to assemble those phonemes into probable words and coherent sentences. For TTS, the process is reversed: the system analyzes text to understand its phonetic structure and prosody (intonation, rhythm), then generates a corresponding audio waveform, often using deep learning models like WaveNet to create lifelike speech.
The integration of these systems enables seamless voice-based interactions, from controlling smart home devices with Amazon Alexa to using live transcription features in Zoom meetings.
Strategic Implementation and Impact
For businesses, integrating speech technologies opens up new channels for user interaction and enhances accessibility. For example, IVR (Interactive Voice Response) systems in call centers can use STT to understand customer requests without rigid keypad menus, improving user experience. TTS can provide automated, dynamic audio alerts or read out content for visually impaired users. Successfully deploying these natural language processing applications requires a focus on the specific audio environment and user base. Managing the devices where these voice interactions occur is also critical. Learn more about how to secure these access points with effective endpoint management.
Actionable Takeaways:
- Train on Diverse Data: To ensure high accuracy, train your speech recognition models on a wide variety of accents, dialects, and speaking styles representative of your target users.
- Implement Robust Audio Preprocessing: Use noise reduction and echo cancellation algorithms to clean audio signals before processing. This is especially vital for applications used in variable environments like cars or public spaces.
- Provide Clear Visual Feedback: When designing voice user interfaces (VUIs), incorporate visual cues to show the system is listening, processing, or has misunderstood a command. This helps manage user expectations and reduce frustration.
8. Content Generation and Writing Assistance
One of the most transformative natural language processing applications is AI-powered content generation and writing assistance. These systems, powered by advanced large language models like OpenAI’s GPT-4, are capable of producing human-like text for a vast array of purposes. They range from drafting marketing copy and generating code to providing editorial suggestions and assisting with creative writing, fundamentally changing how content is created and refined.
How Content Generation Tools Leverage NLP
The foundation of these tools is a sophisticated understanding of language structure, context, and semantics. When a user provides a prompt, the system analyzes the input to grasp the intended topic, tone, and format. It then uses its training on massive datasets to predict the most probable sequence of words to generate a coherent and relevant response. Transformer architectures, a key NLP innovation, enable these models to weigh the importance of different words in the input, ensuring long-range context is maintained. This allows tools like Jasper AI to create compelling business content or GitHub Copilot to generate functional code snippets.
Strategic Implementation and Impact
For businesses, integrating AI writing assistants translates into a dramatic increase in content production velocity and consistency. A marketing team, for instance, can use a tool like Copy.ai to rapidly generate dozens of variations of ad copy for A/B testing, a task that would take a human writer hours. This allows for more agile and data-driven marketing campaigns. Similarly, developers using GitHub Copilot can accelerate their coding workflow by having the AI suggest entire functions based on comments or existing code, reducing repetitive tasks and boosting productivity.
Actionable Takeaways:
- Provide Clear and Specific Prompts: The quality of the output is directly tied to the quality of the input. Instead of a vague request like “write a blog post,” provide detailed instructions about the topic, target audience, desired tone, and key points to include.
- Use AI as a Creative Partner, Not a Replacement: Treat the generated text as a first draft or a source of inspiration. The most effective strategy involves combining AI-generated content with human oversight, editing, and fact-checking to ensure accuracy, originality, and brand alignment.
- Develop a Content Review Framework: Establish a clear workflow for reviewing and refining AI-generated materials. This should include checks for factual accuracy, plagiarism, and adherence to brand voice and ethical guidelines before publication.
NLP Applications Feature Comparison
| AI Technology | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Chatbots and Virtual Assistants | Medium – Requires NLU models and dialogue management | High – Needs cloud infrastructure and training data | Consistent 24/7 conversational support | Customer service, personal assistants, information retrieval | Scalable, reduces operational costs, improves customer satisfaction |
| Machine Translation | High – Complex NMT architectures with attention mechanisms | High – Large datasets and GPU resources for training | Instant cross-language translation | Global communication, multilingual content accessibility | Supports many languages, cost-effective, continuously improving accuracy |
| Sentiment Analysis | Medium – Polarity and emotion models with multi-language support | Moderate – Labeled training data and APIs | Automated emotional tone detection | Brand reputation monitoring, social media analysis | Processes large data volumes, provides objective sentiment insights |
| Text Summarization | Medium to High – Extractive/abstractive models with fine-tuning | Moderate to High – Large text corpora for training | Concise summaries preserving key information | News aggregation, document digestion, accessibility | Saves time, enables quick decision-making, scalable processing |
| Named Entity Recognition (NER) | Medium – Multi-class classification with domain adaptation | Moderate – Labeled entity datasets | Structured extraction of entities from text | Information organization, compliance monitoring | Supports multi-language, improves search and information retrieval |
| Question Answering Systems | High – Combines retrieval and comprehension models with reasoning | High – Large knowledge bases and complex models | Precise, contextual answers to natural language queries | Self-service information access, intelligent search | Instant answers, scales to large data, supports complex queries |
| Speech Recognition and Synthesis | High – ASR and TTS with noise robustness and multi-accent support | High – Audio datasets and real-time processing power | Accurate speech-to-text and natural voice synthesis | Voice assistants, accessibility tools, voice-controlled devices | Enables hands-free interaction, supports accessibility, multilingual |
| Content Generation and Writing Assistance | High – Large language models with context understanding | Very High – Massive compute and data for training | Coherent, human-like text generation | Creative writing, marketing content, code generation | Accelerates content creation, maintains tone consistency, scalable |
Your Next Move in the NLP Revolution
As we’ve journeyed through the diverse landscape of natural language processing applications, a clear picture emerges. The technology has evolved far beyond a niche academic discipline into a fundamental engine of modern business and digital interaction. We’ve seen how sophisticated chatbots are revolutionizing customer service, how neural machine translation is dismantling global communication barriers, and how sentiment analysis is providing an unprecedented window into the voice of the customer.
The strategic thread connecting these powerful examples, from text summarization to named entity recognition, is the transformation of unstructured text and speech into structured, actionable intelligence. The true value isn’t just in the technical wizardry of the models themselves, but in their targeted application to solve specific, high-value business problems. The success stories we explored are not about adopting AI for its own sake; they are about using NLP to streamline workflows, mitigate risk, personalize user experiences, and unlock new revenue streams.
From Insight to Implementation: Actionable Takeaways
Mastering the concepts behind these natural language processing applications is no longer optional for forward-thinking organizations and practitioners. The key is to move from theoretical understanding to strategic implementation.
Here are your actionable next steps:
- For Business Leaders and Strategists: Conduct a “language data audit.” Identify where your organization’s most critical information is trapped in unstructured formats like emails, support tickets, contracts, and customer reviews. Map these data sources to the NLP applications we’ve discussed. For instance, could a custom NER model extract key terms from legal documents to accelerate due diligence? Could sentiment analysis on support tickets proactively identify at-risk customers?
- For Engineers and Data Scientists: Go beyond off-the-shelf APIs. While pre-trained models are excellent starting points, the real competitive advantage lies in fine-tuning these models on your proprietary data. Focus on building robust data pipelines and establishing clear metrics for success that align with business KPIs, not just model accuracy. Experiment with smaller, more efficient models for specific tasks to optimize cost and performance.
The Imperative of Strategic and Ethical Application
The increasing accessibility of powerful NLP models presents a dual reality. On one hand, it lowers the barrier to entry, empowering more teams to build incredible solutions. On the other, it magnifies the importance of responsible and strategic deployment. The future of impactful NLP lies not just in building more powerful models, but in building smarter, more ethical, and more focused applications. The most successful implementations will be those that are deeply integrated into business processes, guided by clear ethical frameworks, and continuously measured against tangible outcomes. The language revolution is here, and your next move will determine your place in it.
To navigate the complexities of AI adoption and turn these insights into a competitive advantage, you need a partner dedicated to deep, actionable analysis. DATA-NIZANT provides the critical intelligence and strategic frameworks necessary to master natural language processing applications and lead your industry. Explore our in-depth resources at DATA-NIZANT to start building your strategic AI roadmap today.
🔗 Unlocking Large Language Models: The Game-Changing Powerhouse of Modern NLP
📅 Published: 2024
Breaks down how LLMs like GPT transform natural language understanding using transformers and emergent capabilities.
🔗 Thought Generation in AI and NLP
📅 Published: 2021
Explores how language models simulate human-like thought processes and creativity in generating contextually rich content.
🔗 From Syntax to Semantics: How Neural Networks Empower NLP and Large Language Models
📅 Published: 2022
Details how neural architectures shift NLP from rule-based syntax to deep semantic understanding in modern applications.
🔗 Tokenization in NLP: Breaking Down Language for Machines
📅 Published: 2020
A foundational article explaining how tokenization acts as the first step in enabling machines to interpret text.
🔗 Understanding the Correlation Between NLP and LLMs
📅 Published: 2022
Analyzes the convergence between traditional NLP methods and large-scale transformer-based models.
🔗 LLM Evaluation Metrics
📅 Published: 2025
Outlines key metrics like BLEU, ROUGE, and perplexity to objectively measure the quality of large language model outputs.
🔗 Decision Tree vs Random Forest: Key Differences Explained
📅 Published: 2021
A visual, digestible explanation of decision trees and ensemble methods like random forests—often foundational in ML/NLP tasks.

