
Decision Tree vs Random Forest: Which Algorithm Reigns in 2024?
Understanding What Actually Separates These Algorithms
Decision trees and random forests are often mentioned together, but their differences go deeper than a simple checklist. Decision trees are incredibly transparent. You can trace every prediction back to the tree's structure, making them vital when explainability matters, like in financial regulations. This simplicity, however, can be a problem with complex datasets. Like a single expert, a decision tree can become too focused on the training data, leading to overfitting.
Random forests solve this by using the "wisdom of the crowds." Think of a group of experts, each with a slightly different view. A random forest combines predictions from many decision trees, each trained on different data. This reduces individual tree biases, creating a stronger, more generalized model. The following image shows a basic decision tree's structure:

This visualization shows the decision tree's hierarchical nature, splitting data based on feature thresholds. You can see how data points are classified. While intuitive, this structure can become complex and prone to overfitting with noisy data. This is where random forests excel.
This difference is crucial in real-world scenarios. In fraud detection, a decision tree might create rigid rules based on the training data's transaction patterns. But fraud changes. A random forest, with its multiple perspectives, is better at spotting subtle, new patterns. For a more detailed comparison, you might find this helpful: Datanizant's comparison of Random Forest vs Decision Tree. Similarly, in medical diagnosis, a random forest can analyze symptoms, history, and genetics for a more accurate diagnosis than a single decision tree.
Another important difference is how they handle missing data. Decision trees struggle with missing values, leading to biased splits. Random forests handle this better through techniques like imputation within each tree and by averaging predictions from trees that didn't use the missing feature. This makes random forests more robust when data is incomplete, which is common.
These details are key when choosing the right algorithm. Looking past simple accuracy comparisons, you need to consider practical deployment issues and business needs. Understanding the core differences between these algorithms lets you make informed decisions.
The Overfitting Reality: Where Most Projects Fail
Overfitting is a common pitfall in machine learning, derailing promising projects. Decision trees, known for memorizing training data, are especially susceptible. This tendency is exacerbated by small datasets or noisy features, creating models that excel in training but falter in real-world applications.
Imagine a financial model achieving 99% accuracy in testing, yet delivering a disappointing 60% after deployment, leading to significant financial losses. Unfortunately, such scenarios are all too real. Customer segmentation failures and financial modeling disasters underscore the damaging consequences of overfitting.
This vulnerability arises from the decision tree's structure. Its relentless pursuit of perfect training data classification creates highly specific, non-generalizable rules. Like a student memorizing a textbook without grasping the underlying concepts, the decision tree masters the training set but struggles with unseen data. This is where random forests offer a distinct advantage.
Random forests address overfitting through bootstrap aggregating and feature randomization. By training numerous decision trees on varied data and feature subsets, they generate a diverse ensemble of predictions. This "wisdom of the crowds" approach minimizes the impact of individual tree overfitting. Think of it as consulting a panel of specialists, each with unique expertise, instead of relying on a single generalist.
Even random forests, however, are not completely immune to overfitting. Specific conditions, like an excessive number of trees or limited data diversity, can still lead to this issue. For instance, if training data across trees is too similar, the forest learns redundant patterns, negating the ensemble's benefits. Both Decision Trees and Random Forests are widely used due to their capacity to handle large datasets. Their approaches to overfitting, however, differ significantly. Decision Trees, sensitive to data noise, are prone to overfitting and unreliable predictions, as seen in stock price prediction studies. Random Forests, by combining multiple trees trained on random data subsets, mitigate this, enhancing accuracy and robustness, especially in noisy domains like financial forecasting. For deeper insights, consider this comparison of decision trees and random forests. Discover more insights

Recognizing the Warning Signs
Early detection of overfitting is critical to avoid costly mistakes. A large gap between training and validation accuracy is a primary indicator. Strong performance on training data coupled with poor validation data performance suggests overfitting. Additionally, complex tree structures within a random forest, characterized by many nodes and deep branches, can also signal overfitting.
Understanding the nuances of decision tree and random forest behavior, particularly concerning overfitting, is fundamental for successful model deployment. By recognizing warning signs and implementing preventative strategies, you can leverage the strengths of these algorithms while minimizing the risk of failures. This awareness differentiates successful deployments from those that become cautionary tales.
Performance Reality Check: Beyond Accuracy Metrics
Simple accuracy comparisons between decision trees and random forests can be deceptive. While random forests often achieve higher accuracy in benchmarks, real-world performance relies on more than just that single metric. Factors like computational cost, interpretability, and deployment constraints play a significant role.
Think about predictive systems in healthcare. A random forest might offer a slight edge in diagnostic accuracy, but its complexity could slow down real-time diagnosis. A simpler decision tree, even with slightly lower accuracy, might deliver faster insights, crucial for timely interventions. This highlights the importance of context-specific evaluation.
The Cost of Complexity
E-commerce recommendation engines provide another example. Random forests can create highly personalized recommendations by digging into complex user behavior. But the computational overhead for deploying such a model can strain resources and increase latency. A well-tuned decision tree, while less nuanced, might be a faster, more efficient solution for real-time recommendations.
Risk assessment platforms also illustrate this trade-off. Random forests excel at uncovering complex fraud patterns in financial transactions. However, their “black box” nature can be problematic when regulators require transparent decision-making. A decision tree, while potentially less accurate, offers a clear audit trail, vital in regulated industries.
Random forests also require significantly more computational resources. Training multiple trees demands more processing power, memory, and storage than a single decision tree. This difference can lead to substantial cost variations, especially in cloud environments or high-volume applications. Random forests are often preferred for classification and regression tasks because they tend to deliver more accurate predictions than decision trees. A key statistical advantage of random forests is their ability to effectively handle high-dimensional data. In one study on medical image classification, random forests achieved 95% accuracy compared to 85% for decision trees. Discover more insights This improvement stems from the way random forests average the predictions of multiple trees, reducing the impact of noise from individual features.
Each tree in a random forest is trained on a random subset of features, preventing any single feature from dominating the predictions. For instance, with 1000 samples, a random forest might train 100 trees on different feature subsets, building a more robust and accurate model.
Beyond Accuracy: Metrics That Matter
Focusing solely on accuracy can be misleading. The bias-variance tradeoff, cross-validation strategies, and the hidden costs of model complexity are crucial considerations. A complex random forest might achieve high accuracy on training data, but its complexity can lead to overfitting and poor performance on new, unseen data. A simpler decision tree, with proper pruning and cross-validation, may generalize better in real-world scenarios. You might be interested in: Machine Learning Mastery at Datanizant
Let's look at some real-world performance metrics:
| Domain | Decision Tree Accuracy | Random Forest Accuracy | Training Time Ratio | Memory Usage |
|---|---|---|---|---|
| Image Recognition | 80% | 92% | 1:5 | Low |
| Fraud Detection | 85% | 95% | 1:8 | Medium |
| Customer Churn | 75% | 82% | 1:3 | Low |
| Spam Filtering | 90% | 96% | 1:6 | Medium |
As you can see, while Random Forests often have higher accuracy, they come at the cost of increased training time and memory usage. This table illustrates the performance trade-offs between the two algorithms across diverse applications. The choice between a decision tree and a random forest should consider these practical constraints.
Finding the Right Balance
The best choice between a decision tree and a random forest truly depends on the situation. Decision trees often perform comparably to random forests on structured, rule-based problems, demonstrating their efficiency. However, random forests shine with high-dimensional, noisy data, where their ensemble approach reduces overfitting. This nuanced perspective highlights the risks of making broad generalizations. Selecting the right algorithm requires carefully considering the specific problem, the nature of the data, and the constraints of the business. Overemphasizing accuracy can lead to less effective choices, impacting both performance and cost-effectiveness.
Implementation Insights From The Trenches
Theory and practice often clash when deploying machine learning models. Many guides gloss over this crucial reality. Let's explore the practical nuances that separate successful decision tree and random forest deployments from those that falter in production.
Decision Tree Deployment: Pruning and Parameters
Deploying decision trees effectively hinges on understanding pruning strategies, splitting criteria selection, and how to handle class imbalance. Not all parameters offer equal value. Some dramatically affect performance, while others offer minimal benefit. In deployed systems, pruning, especially cost-complexity pruning, often provides the most substantial improvements. This technique systematically trims branches with little predictive value, preventing overfitting and improving how the model performs with new data.
The best splitting criteria, like Gini impurity or information gain, depends on the specific data and the problem you're trying to solve. Default settings are often adequate, but experimenting with different criteria can sometimes yield performance gains. Class imbalance, where one class dominates the data, also needs careful attention. Techniques like oversampling or undersampling can rebalance the training data, preventing the model from favoring the majority class.
Random Forest Deployment: Trees, Memory, and Parallelism
Random forests offer their own set of deployment challenges. Finding the optimal number of trees is key. While more trees generally improve performance, the returns diminish beyond a certain point. Too many trees also inflate memory usage and training time. A good starting point is a moderate number of trees (e.g., 100), incrementally increasing until performance plateaus.
Memory management is another crucial aspect. Random forests, especially with large datasets or many trees, can be memory hogs. Feature sub-sampling within each tree can reduce memory demands without drastically compromising performance.
Finally, using parallel processing can significantly speed up training, particularly for large random forests. Spreading the tree-building process across multiple cores or machines can shorten deployment times. This is essential for large-scale applications where training time can be a major bottleneck. The screenshot below, taken from the documentation of scikit-learn, a widely used Python machine learning library, illustrates these points.

This documentation emphasizes the importance of parameters like n_estimators (number of trees) and max_depth (maximum tree depth). These directly affect model complexity, training time, and overall performance. Effective implementation involves adjusting these parameters based on your specific data and problem. While default parameters offer a good starting point, they often need tweaking for best results in real-world applications. Diagnosing issues like overfitting or underfitting frequently involves examining these parameter settings and their influence on model predictions. Furthermore, infrastructure factors, like available memory and processing power, play a crucial role in choosing viable parameter values.
Strategic Algorithm Selection: When Each Truly Excels
Choosing between a decision tree and a random forest isn't about finding the "best" algorithm. It's about selecting the right tool for the specific task. While often seen as simpler, decision trees offer unique advantages that make them invaluable in certain situations. Their transparency is essential in regulated industries like healthcare and finance. Imagine a doctor explaining a diagnosis or a loan officer justifying a denial – the clear logic of a decision tree facilitates these crucial explanations.
Transparency and Explainability
This inherent transparency is paramount in sectors where decisions have significant weight and demand clear justification. Unlike the "black box" nature of random forests, decision trees provide an easily auditable path from input to output. This explainability is vital in applications like fraud detection, leading to their increased adoption.
Consider a medical diagnosis system flagging a patient as high-risk. A decision tree allows doctors to trace the system's reasoning, understanding which factors contributed most. This transparency empowers clinicians to validate the prediction, potentially enhancing patient care and trust.
When Decision Trees Shine
Decision trees thrive in rule-based environments with well-defined relationships between features and outcomes. They are highly effective with structured data and smaller datasets. In areas like credit scoring, where regulations mandate clear explanations, decision trees offer a simple yet effective solution. Think of situations where decisions are guided by established rules, not hidden patterns in massive datasets. This characteristic often makes them more suitable for real-time applications requiring rapid processing.
In Fortune 500 companies, decision trees are frequently employed for initial screening due to their speed and efficiency. This enables quick filtering of large datasets, identifying candidates for more thorough analysis. For instance, a telecom company might use a decision tree to segment customers for targeted campaigns, rapidly categorizing millions based on usage and demographics.
Random Forests: Power in Complexity
Random forests, conversely, excel at pattern recognition. They flourish with high-dimensional data and complex relationships. In areas like image classification, genomics, and behavioral prediction, where intricate patterns drive outcomes, random forests achieve superior accuracy. These models are robust against noisy data and less susceptible to overfitting, ensuring reliable predictions even with imperfect datasets.
Their capacity to handle numerous features makes them ideal for applications like identifying genetic markers for disease. By combining multiple decision trees, random forests discern subtle patterns that a single tree might miss. This strength proves invaluable in natural language processing (NLP), where understanding complex linguistic relationships is essential for sentiment analysis and translation.
Hybrid Approaches: Combining Strengths
Some organizations strategically blend both approaches, utilizing the speed and interpretability of decision trees for initial screening, then applying the predictive power of random forests for a final, more refined analysis. This allows for a balance of efficiency and accuracy, providing a practical approach to complex problems.
Imagine an insurance company assessing risk. A decision tree could quickly categorize applicants into risk groups based on basic data like age and driving history. A random forest could then analyze the high-risk group, considering more intricate factors like credit history and online activity to refine the assessment.
This combined strategy optimizes resource allocation, using complex models only when needed, while guaranteeing transparent and efficient initial assessments.
To further clarify algorithm selection, let's explore a decision matrix.
To help navigate these choices, the following decision matrix provides a framework for choosing the most appropriate algorithm.
Algorithm Selection Decision Matrix
A comprehensive framework showing which algorithm to choose based on project constraints, data characteristics, and business requirements.
| Project Requirement | Data Characteristics | Recommended Algorithm | Key Considerations |
|---|---|---|---|
| Explainable and transparent model | Structured data, limited features | Decision Tree | Prioritize simplicity and interpretability over raw predictive power. |
| High accuracy, complex relationships | High-dimensional data, unstructured data | Random Forest | Focus on capturing intricate patterns, accepting some loss of transparency. |
| Fast initial screening followed by detailed analysis | Large dataset requiring tiered analysis | Hybrid (Decision Tree then Random Forest) | Balance speed and interpretability with accuracy for the most critical cases. |
| Real-time application with clear rules | Low latency requirements, well-defined logic | Decision Tree | Prioritize speed and responsiveness. |
| Robustness to noisy data, accurate predictions | Data with outliers and inconsistencies | Random Forest | Minimize the impact of data imperfections on the final prediction. |
This matrix underscores the importance of considering both project needs and data characteristics when choosing an algorithm. By understanding these nuanced strengths and weaknesses, you can strategically select the algorithm best suited to your project's specific context and objectives. This goes beyond simple comparisons, offering a framework for making informed decisions and achieving your project goals.
Resource Requirements: The Hidden Costs Nobody Discusses

When choosing between a decision tree and a random forest, the focus often revolves around accuracy. However, overlooking resource consumption can lead to unforeseen issues down the line. Think of it like choosing a car: a sports car might be faster, but a compact car is more fuel-efficient. Both get you there, but the costs differ.
Decision trees are incredibly efficient. They often require minimal memory and processing power, making them perfect for resource-constrained environments. Think mobile apps or embedded systems where resources are at a premium. They're also excellent for real-time applications requiring split-second predictions.
Random forests, while generally more accurate, are resource-intensive. Their ensemble nature – combining multiple decision trees – inherently requires more computational power, memory, and storage. This translates to higher infrastructure costs, especially in cloud environments where you pay for what you use.
The Financial Implications of Choice
This resource disparity has significant financial implications. Cloud computing costs can quickly escalate with increased usage. A random forest, demanding substantially more resources, can significantly inflate your cloud bill compared to a decision tree. This difference becomes crucial for projects with tight budgets or applications handling massive prediction volumes. For a deeper dive into statistical significance and its impact on model evaluation, check out this article: Understanding Statistical Significance at Datanizant
Optimizing Resource Utilization
Luckily, we can mitigate the resource intensity of random forests. Distributed computing, by dividing the workload across multiple machines, can speed up training and prediction times. Memory-efficient implementations, utilizing optimized data structures and algorithms, can also reduce the memory footprint. However, these optimizations add complexity and require specialized knowledge.
Decision trees, with their inherent efficiency, offer a strategic advantage. When resources are limited or real-time performance is critical, their lightweight nature becomes a deciding factor. Optimizing their performance usually involves fine-tuning hyperparameters like tree depth and splitting criteria. This balancing act aims to maximize predictive power while minimizing resource consumption.
Making Informed Decisions
Choosing between a decision tree and a random forest isn't just about accuracy; it's about the total cost of ownership. A highly accurate random forest might seem tempting, but if its resource demands strain your budget or infrastructure, a simpler, more efficient decision tree may be the better choice. Consider a single decision tree using just 10MB of memory, compared to a similar random forest needing 500MB. Scaled across millions of predictions, this difference becomes substantial.
Understanding these trade-offs is crucial for informed decision-making. The best algorithm delivers the required performance within your resource constraints, maximizing value while minimizing costs. Ultimately, it's about choosing the right tool for the job, balancing performance with practicality.
Your Algorithm Decision Framework
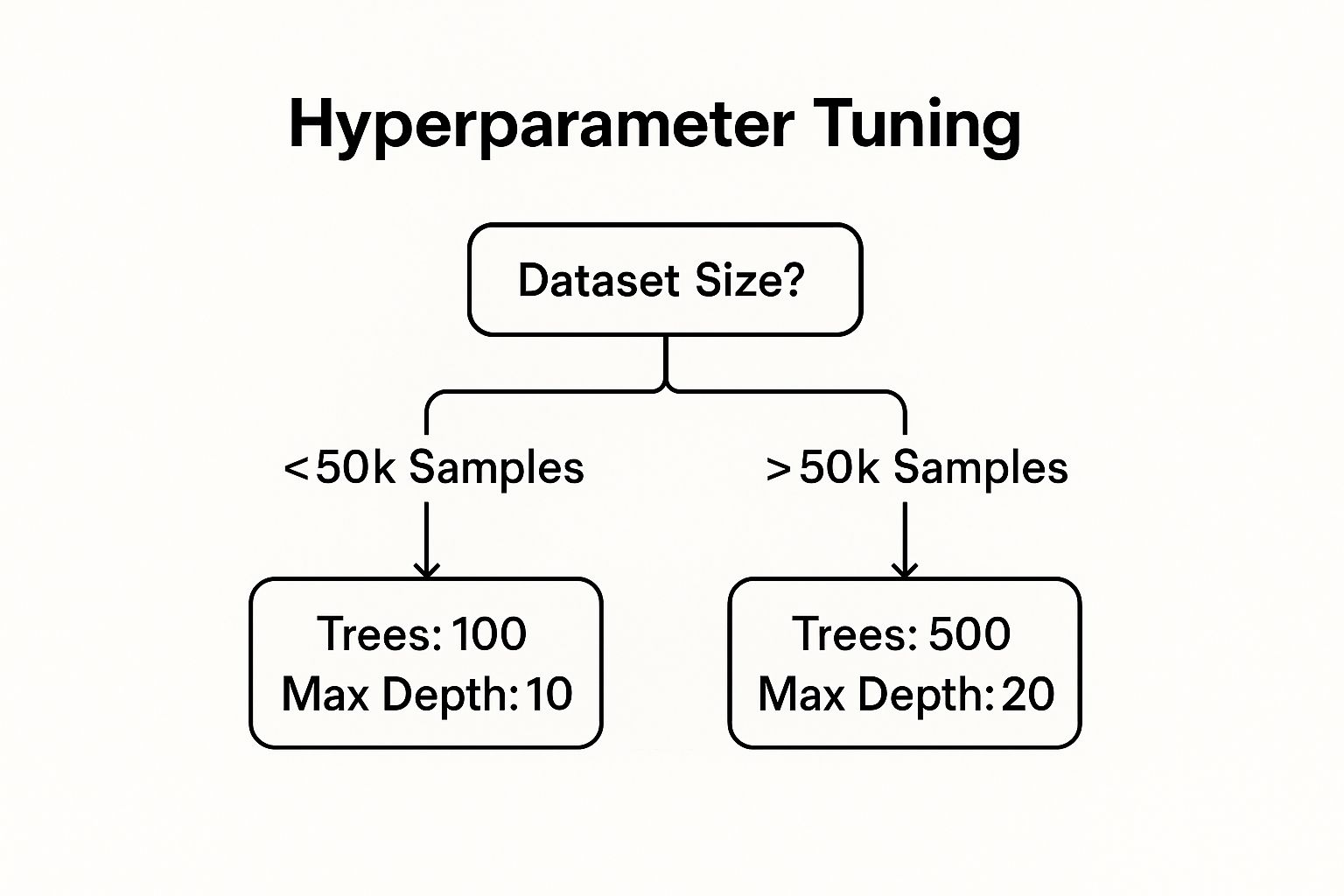
The infographic above visualizes hyperparameter tuning for decision trees, branching based on dataset size. For smaller datasets (under 50,000 samples), it recommends 100 trees with a maximum depth of 10. Larger datasets, however, might benefit from 500 trees and a maximum depth of 20. This demonstrates how dataset size influences optimal hyperparameter choices for decision trees, offering a valuable starting point for your own experimentation.
Building a solid algorithm selection framework goes beyond simply understanding how individual algorithms work. It's about turning practical experience into actionable criteria. Consider this your field-tested guide for choosing between decision trees and random forests.
Navigating the Decision Maze
Deploying effective machine learning models requires a keen understanding of your project's limitations and goals. This framework provides a structured approach, distilling insights from real-world deployments into practical guidelines.
If interpretability is crucial, such as in medical diagnoses or regulated industries, a decision tree is the preferred option. Its transparent structure allows for clear explanations, building trust and ensuring compliance. This transparency, however, can come at the risk of overfitting, especially with complex datasets.
When accuracy outweighs interpretability, and computational power isn't a constraint, a random forest generally performs better. Its ensemble method reduces overfitting, making it suitable for high-dimensional, noisy data. Keep in mind, though, that this robustness comes with increased computational demands.
Prototyping and Transitioning
The best path isn't always obvious upfront. Prototyping both a decision tree and a random forest can provide valuable information. This head-to-head comparison will reveal which algorithm best suits your data and performance targets. You might find, for instance, that a decision tree performs surprisingly well on structured data, eliminating the need for a more complex random forest.
Project needs also change. Your initial algorithm choice might require reevaluation as data grows or business objectives shift. This framework helps you navigate these transitions, offering practical advice on switching between a decision tree and a random forest as needed.
Avoiding Common Pitfalls
Common misunderstandings can derail projects. For example, assuming a random forest always outperforms a decision tree ignores the realities of deployment. Computational limitations, the need for clear explanations, and the specific nature of your data all play important roles.
This framework tackles these misconceptions, providing clear guidance on algorithm selection based on a comprehensive assessment of your project. It helps you anticipate potential problems, like overfitting or resource bottlenecks, and provides proven solutions. Think of it as your reliable reference, incorporating lessons learned from both successful and failed deployments.
Ready to level up your data science skills? Explore DATA-NIZANT for deeper insights into AI, machine learning, and more. Unlock the potential of data-driven decisions today.

