
9 Powerful Cloud Cost Optimization Strategies for 2025
Beyond the Bill: 9 Advanced Cloud Cost optimization Strategies
While the cloud offers unparalleled agility, it often comes with a significant and unpredictable price tag. For most organizations, the low-hanging fruit of cost savings, like shutting down idle resources, has already been picked. To truly control and reduce cloud expenditures, a more sophisticated approach is required-one that combines deep technical adjustments with strategic financial governance. This is where advanced cloud cost optimization strategies become essential, moving beyond basic checklists to fundamentally change how you manage cloud infrastructure.
This guide provides a detailed playbook for implementing nine such strategies. We will explore powerful techniques including dynamic resource management with auto-scaling, leveraging spot instances for massive discounts, and optimizing container costs in Kubernetes environments. You will also learn how to build a robust FinOps practice to create a culture of cost accountability across your teams. Each section offers specific, actionable steps and practical examples to help you implement these methods effectively. Whether your goal is to reduce your immediate bill or build a long-term, cost-efficient cloud architecture, these proven strategies will provide the blueprint for success.
1. Right-sizing and Resource Optimization
Right-sizing is the foundational practice of matching your infrastructure resources to your actual workload demands. It involves a continuous analysis of compute, storage, and memory allocations to eliminate wasteful over-provisioning. This strategy directly attacks one of the biggest sources of unnecessary cloud spend, ensuring you pay only for what you truly need without compromising application performance.

This process goes beyond simple monitoring. It requires analyzing historical performance data, such as CPU and RAM utilization, over a significant period to identify instances that are consistently underutilized. For example, a virtual machine running at an average of 15% CPU utilization is a prime candidate for downsizing to a smaller, less expensive instance type. Implementing these changes is one of the most direct and impactful cloud cost optimization strategies available.
Practical Implementation Tips
- Start Safely: Begin your right-sizing journey in non-production environments like development, testing, or staging. This allows your team to build experience and confidence without risking production workloads.
- Use Tools as a Guide: Leverage recommendations from native tools like AWS Trusted Advisor, Google Cloud Recommender, and Azure Advisor. Treat their suggestions as a starting point for your own deeper analysis, not a final command.
- Implement Gradually: Roll out changes incrementally and always have a well-documented rollback plan. This precaution is crucial in case of unforeseen performance issues.
- Validate and Monitor: After a change, analyze performance metrics for at least two to four weeks. This extended period ensures the new instance size is truly optimal and can handle your workload's natural peaks and troughs.
Real-World Success
The impact of right-sizing is proven at scale. Netflix famously pioneered continuous right-sizing for its massive streaming infrastructure, reducing compute costs significantly while handling massive scale. Similarly, Capital One applied this technique aggressively to its non-production environments, achieving a reported 40% cost reduction in those specific areas by eliminating idle developer resources.
2. Reserved Instances and Savings Plans
Reserved Instances (RIs) and Savings Plans are commitment-based pricing models that offer significant discounts for a one or three-year term of guaranteed usage. By committing to a certain level of compute or database usage, you can slash on-demand rates by up to 72%. This strategy is highly effective for applications with stable, predictable workloads, allowing you to convert fluctuating operational costs into a predictable budget line item.
The bar chart below visualizes the typical savings progression when moving from on-demand pricing to long-term commitments.
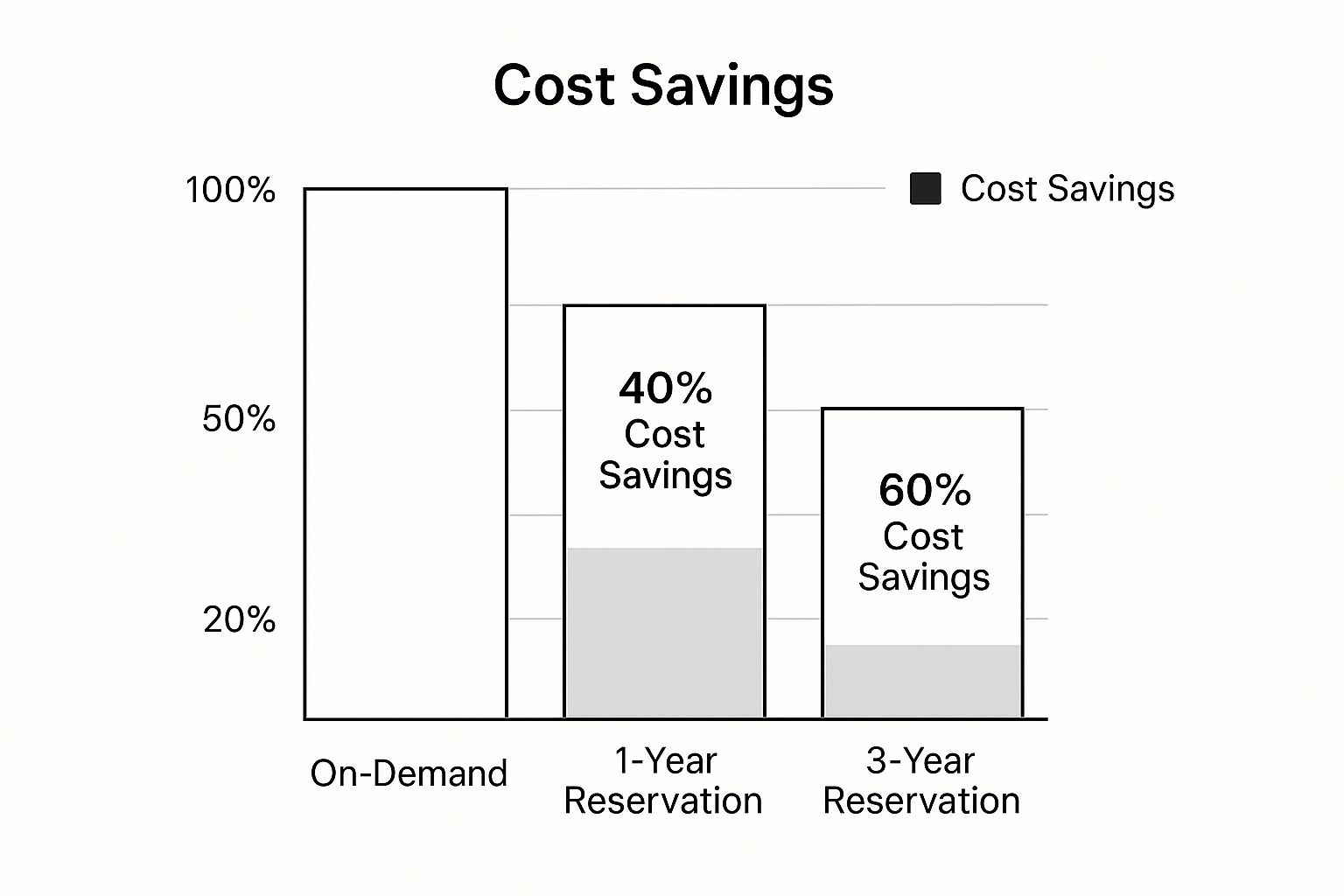
As shown, a three-year commitment can yield upwards of 60% in savings, a substantial increase over a one-year term. Locking in these rates provides budget certainty and frees up capital for innovation rather than just keeping the lights on. While it requires upfront analysis, managing a portfolio of these commitments is one of the most impactful cloud cost optimization strategies for any organization operating at scale.
Practical Implementation Tips
- Analyze Historical Data: Review at least six months of usage data to accurately forecast the baseline capacity you can safely commit to.
- Prioritize Flexible Plans: Start with Compute Savings Plans or Convertible RIs. They provide significant savings while allowing you to adapt to changing technology needs.
- Automate Management: Use native tools like AWS Cost Explorer or third-party platforms to monitor reservation coverage and identify optimization opportunities.
- Use the Marketplace: If plans change, sell unused capacity on the AWS Reserved Instance Marketplace to recoup your investment and avoid waste.
Real-World Success
The results of this strategy are proven at scale. Lyft reportedly saved over $100 million by using AWS RIs and Savings Plans. Similarly, Zillow cut its compute costs by 45% with strategic RI purchases, and Pinterest saved 60% on its ML workloads by using Compute Savings Plans.
3. Auto-scaling and Dynamic Resource Management
Auto-scaling is a dynamic practice that automatically adjusts your cloud resources to match real-time demand. This strategy ensures applications have the power to handle traffic spikes by adding resources, then scales them down during quiet periods to avoid paying for idle capacity. This elasticity is fundamental for building a cost-efficient cloud environment.
This approach moves beyond static provisioning by using services like AWS Auto Scaling or Azure Virtual Machine Scale Sets to create policies that respond to live performance metrics. Configuring these rules is one of the most powerful cloud cost optimization strategies, as it perfectly aligns your spending with actual usage. Proper endpoint management and monitoring is vital for tracking these dynamic resources.
Practical Implementation Tips
- Set Cooldown Periods: Use cooldowns to prevent "thrashing," where the system rapidly adds and removes instances due to temporary traffic fluctuations.
- Use Multiple Metrics: Make scaling decisions using a mix of metrics like CPU and memory, not just a single one, for greater reliability.
- Test Policies Thoroughly: Always validate scaling rules in a staging environment to understand their behavior before deploying to production.
- Implement Graceful Shutdowns: Ensure instances complete active tasks before termination during a scale-in to prevent errors and data loss.
Real-World Success
The power of auto-scaling is evident in major digital platforms. Spotify uses it to handle peak listening hours, reportedly reducing compute costs by 35%. The New York Times relies on it to manage huge traffic surges during breaking news. Famously, Pokemon Go used auto-scaling to successfully handle unpredictable, viral traffic spikes at launch, a feat impossible with static provisioning.
4. Spot Instances and Preemptible VMs
Leveraging spot instances and preemptible VMs is a powerful strategy that involves using a cloud provider's excess, unused compute capacity at a steep discount, often up to 90% off on-demand prices. The core trade-off is that these resources can be reclaimed by the provider with very short notice when that capacity is needed for on-demand customers. This makes them ideal for workloads that are fault-tolerant, stateless, or can be interrupted and resumed without significant impact.

This approach, popularized by services like Amazon EC2 Spot Instances, Azure Spot Virtual Machines, and Google Preemptible VMs, is not for every workload. It is perfectly suited for batch processing, big data analytics, CI/CD pipelines, and machine learning training jobs. By designing applications to handle interruptions gracefully, organizations can unlock immense savings. Adopting this model is one of the more advanced cloud cost optimization strategies that can fundamentally change the economics of running large-scale compute operations.
Practical Implementation Tips
- Diversify and Conquer: Don't rely on a single instance type or availability zone. Spreading your workload across multiple instance pools significantly reduces the risk of a widespread interruption.
- Implement Checkpointing: For long-running jobs, save the state of your application periodically. This allows the job to resume from the last checkpoint if an instance is reclaimed, preventing a total loss of work.
- Use Fleet Management: Leverage tools like AWS Spot Fleet or Azure VM Scale Sets. These services automatically request the lowest-priced instances across your specified types and zones to maintain your target capacity.
- Monitor Price History: Analyze historical spot pricing data to understand trends. This helps in setting appropriate bid prices and identifying instance types that offer the best balance of low cost and stability.
Real-World Success
The financial impact of using spot instances is massive for companies with compute-intensive tasks. Netflix famously processes its massive video encoding pipeline using Spot Instances, saving millions annually on a core business function. Likewise, Lyft runs many of its machine learning model training jobs on spot capacity, reporting cost reductions of over 70%. Epic Games also relies on spot fleets to handle immense, variable compute loads for its globally popular game, Fortnite.
5. Cloud Storage Optimization and Tiering
Cloud storage optimization is a technique centered on intelligent data lifecycle management. It involves automatically moving data between different storage tiers, from high-performance "hot" storage to low-cost "archive" storage, based on access patterns and age. This strategy dramatically reduces storage expenses for large datasets without sacrificing accessibility.
The approach works by creating automated policies that govern data movement. Data accessed daily can reside in a standard tier, but after 30 days of inactivity, it might move to a less expensive infrequent access tier. This proactive management, powered by native services like Amazon S3 Intelligent-Tiering and Azure Blob Storage access tiers, is one of the most impactful cloud cost optimization strategies available for data-heavy organizations.
Practical Implementation Tips
- Analyze Access Patterns First: Before creating policies, use storage analytics to understand which data is hot versus cold. This insight is foundational for effective tiering.
- Start with Low-Impact Data: Begin applying lifecycle rules to older, less frequently accessed data like logs or archives to safely test and validate your policies.
- Monitor and Refine with Analytics: Regularly check analytics to confirm your tiering policies are delivering cost savings and adjust them as access patterns evolve over time.
- Add Compression for Greater Savings: Implement compression and deduplication to reduce the raw size of your data, which amplifies cost reductions across all storage tiers.
Real-World Success
The impact of storage tiering is proven at enterprise scale. Dropbox reportedly reduced its storage expenses by 60% using intelligent tiering strategies. Thomson Reuters achieved $2 million in annual savings by automating its data lifecycle policies, while GE Digital cut IoT data storage costs by 75% by moving older data to colder tiers.
6. Multi-cloud and Hybrid Cost Arbitrage
Multi-cloud cost arbitrage involves strategically placing workloads across different cloud providers to leverage pricing differences, specialized services, and regional availability. Instead of committing to a single vendor, this approach treats cloud platforms as a competitive marketplace, allowing you to select the most cost-effective solution for each specific use case, from data storage to machine learning computation. This advanced strategy helps mitigate vendor lock-in and can unlock substantial savings by exploiting the unique strengths of each provider.
This goes far beyond simply using more than one cloud. It requires a deliberate architecture where applications are designed for portability. For instance, you might run a compute-intensive analytics job on Google Cloud to take advantage of its data tools, while hosting a database on AWS for its robust managed services and another workload on Azure for its enterprise integrations. Mastering this workload placement is one of the most impactful cloud cost optimization strategies for mature organizations seeking to maximize efficiency at scale. You can explore detailed multi-cloud optimization tactics to gain further insight into this approach.
Practical Implementation Tips
- Focus on Portable Workloads: Start with stateless applications or containerized services using Kubernetes. Their inherent portability makes it much simpler to move them between clouds without significant re-architecting.
- Use Unified Management Tools: Employ infrastructure-as-code tools like HashiCorp Terraform or management platforms like Flexera to provision and manage resources consistently across different providers from a single control plane.
- Implement Cross-Cloud Monitoring: A unified monitoring solution is non-negotiable. It is essential for tracking performance and costs across all environments to maintain a holistic view of your spending and operational health.
- Negotiate Strategically: Leverage your total cloud spend across multiple providers as a bargaining chip. Committing significant volume to more than one vendor can often unlock better enterprise discounts than going all-in on a single one.
Real-World Success
The power of this strategy is evident in major tech companies. Snap Inc. famously maintains a multi-cloud posture, giving it significant leverage during pricing negotiations with its primary providers. Similarly, global enterprises like McDonald's use a multi-cloud and hybrid approach for regional cost optimization and resilience. In one documented case, a financial services firm achieved a 30% cost reduction by strategically moving specific data processing workloads to the most economical platform, proving the direct financial benefit of arbitrage.
7. Serverless and Function-as-a-Service (FaaS) Optimization
Serverless computing represents a paradigm shift from provisioning servers to executing code on demand. This approach, centered on Function-as-a-Service (FaaS) platforms like AWS Lambda or Azure Functions, allows you to run application logic in response to events without managing any underlying infrastructure. Its core value is a pay-per-execution model, which entirely eliminates costs for idle compute resources.
Instead of paying for an "always-on" virtual machine, you only pay for the precise milliseconds your code is running. When an event trigger occurs, the cloud provider instantly allocates resources, executes your function, and then tears it all down. This automatic scaling to zero is what makes the model so powerful. Adopting this is one of the most transformative cloud cost optimization strategies for applications with intermittent, event-driven, or unpredictable traffic patterns.
Practical Implementation Tips
- Fine-tune Function Memory: Memory allocation in FaaS is often directly tied to CPU power. Experiment with different memory settings to find the optimal balance; sometimes, slightly increasing memory can reduce execution time and result in a lower overall cost.
- Manage Cold Starts: For latency-sensitive applications, use features like Provisioned Concurrency to keep a certain number of function instances warm and ready. Use this feature strategically, as it incurs a cost, but it can be essential for user-facing APIs.
- Optimize Execution Duration: Profile your code to identify and eliminate bottlenecks. Shorter runtimes directly translate to lower costs, so focus on efficient logic, optimized dependencies, and fast external API calls.
- Implement Smart Retries: Inefficient error handling can lead to a cascade of costly, repeated invocations. Use exponential backoff strategies and configure dead-letter queues to gracefully handle failures without running up your bill.
Real-World Success
The financial and operational benefits of serverless are proven in massive enterprise applications. Coca-Cola migrated its sprawling vending machine communications platform to a serverless architecture, allowing it to scale effortlessly to handle millions of transactions without server management. Similarly, iRobot leverages serverless processing for the vast streams of IoT sensor data from its Roomba devices, eliminating idle infrastructure costs and scaling instantly to meet data ingestion peaks.
8. Cloud Financial Operations (FinOps)
Cloud Financial Operations, or FinOps, is a cultural and operational practice that brings financial accountability to the variable spending model of the cloud. It fosters collaboration between engineering, finance, and business teams to manage cloud costs effectively. The goal is to empower teams to make trade-offs between speed, cost, and quality in real-time.
This approach isn't just about saving money; it's about making money by enabling innovation and business growth. FinOps establishes a framework of processes, tools, and governance to provide visibility, allocate costs, and optimize spending. By embedding financial discipline directly into the development lifecycle, it turns cost management into a core competency, making it one of the most strategic cloud cost optimization strategies for mature organizations.
Practical Implementation Tips
- Establish Clear Governance: Start with executive sponsorship to build a FinOps culture. Define clear roles, responsibilities, and governance frameworks, which are as crucial for financial health as they are for data integrity. Learn more about the principles of effective governance.
- Implement Consistent Tagging: Enforce a consistent and comprehensive cost allocation tagging policy across all cloud resources. This is foundational for accurate showback and chargeback, allowing you to attribute every dollar spent to a specific team, project, or product.
- Hold Regular Reviews: Establish a cadence of regular, cross-functional meetings where teams review spending reports, discuss anomalies, and plan optimization initiatives. This creates a continuous feedback loop for improvement.
- Automate Policy and Detection: Use automation to enforce cost-saving policies, such as shutting down non-production resources after hours, and to detect spending anomalies before they become major issues.
Real-World Success
The impact of a strong FinOps practice is clear across industries. Nike implemented FinOps to reduce its cloud waste by 50% while simultaneously accelerating its pace of innovation. Likewise, Spotify's FinOps culture enabled an estimated 40% cost optimization as it scaled its global operations. Target also leveraged FinOps to achieve granular cost visibility across its business units, empowering individual teams to own their cloud spend.
9. Container and Kubernetes Cost Optimization
Container cost optimization focuses on efficiently managing containerized workloads, particularly within Kubernetes, through precise resource allocation and intelligent workload scheduling. This strategy directly addresses cost by maximizing the density of applications running on your infrastructure, a concept known as bin-packing, ensuring you extract the most value from every compute node.
This goes beyond simply running containers; it's about mastering the orchestration layer to improve utilization and reduce the number of virtual machines needed. By fine-tuning how Kubernetes schedules pods, you can transform platforms like Amazon EKS, Google GKE, and Azure AKS into powerful cloud cost optimization strategies. This prevents the common and costly pitfall of over-provisioned, underutilized clusters.
Practical Implementation Tips
- Right-size Container Resources: Define accurate CPU and memory requests and limits for each container. This guarantees resources for scheduling and prevents "noisy neighbor" problems by capping usage.
- Use Affinity Rules: Implement node affinity and anti-affinity to guide pod placement. Co-locate services that communicate frequently or separate critical workloads for better performance and resilience.
- Implement Namespace Quotas: Apply resource quotas at the namespace level to create clear boundaries for teams or applications, preventing any single project from consuming excessive cluster resources.
- Monitor and Autoscale Nodes: Continuously monitor cluster node utilization. Use cluster autoscalers to add or remove nodes based on real-time demand, ensuring you only pay for what you use.
Real-World Success
The impact of this is proven at scale. Adidas reportedly cut infrastructure costs by 60% by adopting Kubernetes. Pinterest dramatically improved its cluster efficiency, boosting resource utilization from 30% to over 80%. E-commerce platforms like Shopify also rely on Kubernetes autoscaling to manage massive traffic spikes during events like Black Friday, controlling costs without risking performance.
Cloud Cost Optimization Strategies Comparison
| Strategy | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Right-sizing and Resource Optimization | Medium – needs ongoing tuning | Moderate – monitoring tools and analytics | Cost savings 20-50%, improved performance | Dynamic workloads, cost-sensitive environments | Immediate savings, better performance, eco-friendly |
| Reserved Instances and Savings Plans | Low to Medium – upfront planning | Low – requires capacity forecasting | Cost savings 30-70%, predictable billing | Stable, steady-state workloads | High discount, predictable costs, capacity reservation |
| Auto-scaling and Dynamic Management | High – complex configuration | Moderate – needs metrics and automation | Automatic cost optimization, scalability | Variable or unpredictable traffic | Auto cost control, improved availability, handles spikes |
| Spot Instances and Preemptible VMs | Medium – requires fault-tolerant design | Low – opportunistic use of excess capacity | Up to 90% cost savings but possible interruptions | Batch jobs, flexible, fault-tolerant workloads | Massive savings, hybrid cost optimization |
| Cloud Storage Optimization and Tiering | Medium – lifecycle policy setup | Moderate – analytics and tiered storage | Storage costs reduction 50-80%, data managed | Variable data access patterns, archival data | Automated cost control, data durability |
| Multi-cloud and Hybrid Cost Arbitrage | High – complex multi-cloud ops | High – multi-platform management | Cost optimization, vendor lock-in avoidance | Multi-cloud strategy, workload portability | Cost benefits, resilience, negotiating leverage |
| Serverless and FaaS Optimization | Medium – design for serverless | Low – no infrastructure to manage | Zero idle costs, automatic scaling | Event-driven, variable traffic, rapid development | Pay-per-use cost model, no server management |
| Cloud Financial Operations (FinOps) | High – organizational change | High – cross-functional tools and effort | Cultural cost accountability, optimized spend | Enterprise-wide cloud cost governance | Cost transparency, data-driven budgeting |
| Container and Kubernetes Cost Optimization | High – needs container expertise | Moderate to High – container orchestration | Higher resource utilization (60-80%), cost reduction | Containerized workloads, microservices | Efficient bin-packing, scaling, resource sharing |
Embedding Cost Efficiency into Your Cloud DNA
Navigating the complexities of cloud spending can feel overwhelming, but mastering it is not an insurmountable challenge. The journey through these nine distinct areas reveals a powerful truth: true cloud cost optimization strategies are not about a single tool or a one-time fix. They represent a fundamental shift in how your organization perceives, manages, and utilizes cloud resources. It is the beginning of a continuous journey toward profound operational and financial excellence.
The common thread weaving through the technical precision of right-sizing instances, the dynamic agility of auto-scaling, and the strategic use of Kubernetes is a proactive, data-driven mindset. This is complemented by the financial acumen required to leverage Reserved Instances and Savings Plans effectively. The ultimate goal is to embed this cost-aware consciousness into every stage of your application lifecycle, transforming it into an integral part of your organization's DNA.
From Tactical Fixes to Strategic Mastery
Achieving a state of sustained cloud efficiency requires moving beyond isolated, reactive measures. The strategies detailed in this article provide a comprehensive toolkit that blends technical execution with high-level financial planning.
- Technical Levers: Strategies like optimizing Spot Instance usage, implementing intelligent storage tiering, and refining serverless function performance are your direct control mechanisms. They are the hands-on actions your engineering teams can take to immediately impact consumption and reduce waste at the resource level.
- Strategic Frameworks: Layered on top of this are the strategic frameworks. Embracing FinOps establishes a culture of accountability, while multi-cloud arbitrage provides a sophisticated method for financial maneuvering. These elements provide the "why" and "how" for your technical efforts, ensuring they align with broader business objectives.
The most crucial takeaway is that these components are not mutually exclusive; they are symbiotic. The most successful organizations are those that empower their engineers with financial context and their finance teams with an understanding of technical trade-offs.
Your Actionable Roadmap to Cloud Financial Health
Transforming these concepts into tangible results requires a clear plan. Here are the immediate next steps you can take to begin your optimization journey:
- Establish a Definitive Baseline: You cannot optimize what you do not measure. Use native tools like AWS Cost Explorer, Azure Cost Management, or Google Cloud Billing dashboards to gain a granular understanding of your current spending patterns. Identify your top cost drivers and establish key performance indicators (KPIs) to track progress.
- Target Low-Hanging Fruit for Quick Wins: Build momentum by tackling the most obvious inefficiencies first. This includes terminating idle or "zombie" resources, deleting unattached storage volumes, and downgrading oversized development and testing environments. These early victories help demonstrate value and build support for more complex initiatives.
- Champion a Cross-Functional Approach: Break down the silos between Engineering, Finance, and Operations. Form a small, dedicated team or a "center of excellence" responsible for cloud financial management. This group will be responsible for setting standards, evangelizing best practices, and ensuring cost becomes a shared responsibility across the entire organization.
By methodically implementing these cloud cost optimization strategies, you transition cost management from a burdensome chore into a powerful competitive differentiator. Every dollar saved on inefficient infrastructure is a dollar that can be reinvested into innovation, talent acquisition, and market expansion. This disciplined approach ensures your cloud investment not only supports today's operations but also sustainably fuels tomorrow's growth.
The landscape of cloud services and pricing models is in constant flux. To maintain your competitive edge, continuous education and access to specialized knowledge are paramount. For professionals looking to deepen their expertise in advanced cloud, AI, and data architecture topics, platforms like DATA-NIZANT provide the critical insights needed to stay ahead. Explore our in-depth resources and tutorials at DATA-NIZANT to ensure your optimization efforts remain at the cutting edge.

