
Unveiling the Power of Tree-Based Algorithms
This listicle provides a clear comparison of random forest vs decision tree algorithms, along with an overview of five other key tree-based models. You’ll learn the core differences, advantages, and use cases for each, enabling you to choose the right algorithm for your machine learning tasks. Understanding these algorithms is essential for effectively tackling prediction and classification challenges. This comparison covers Decision Tree, Random Forest, Gradient Boosting Machine (GBM), XGBoost, LightGBM, CatBoost, and Extra Trees.
1. Decision Tree
When comparing random forest vs decision tree, it’s essential to understand each algorithm individually. A Decision Tree is a supervised machine learning algorithm that uses a tree-like model of decisions and their possible consequences. It works by recursively partitioning a dataset into smaller and smaller subsets, simultaneously building a decision tree in an incremental fashion. This process continues until the subsets are homogeneous enough or a predefined stopping criterion is met. The final result is a tree with decision nodes, representing tests on attributes, and leaf nodes, representing the final classifications or decisions.
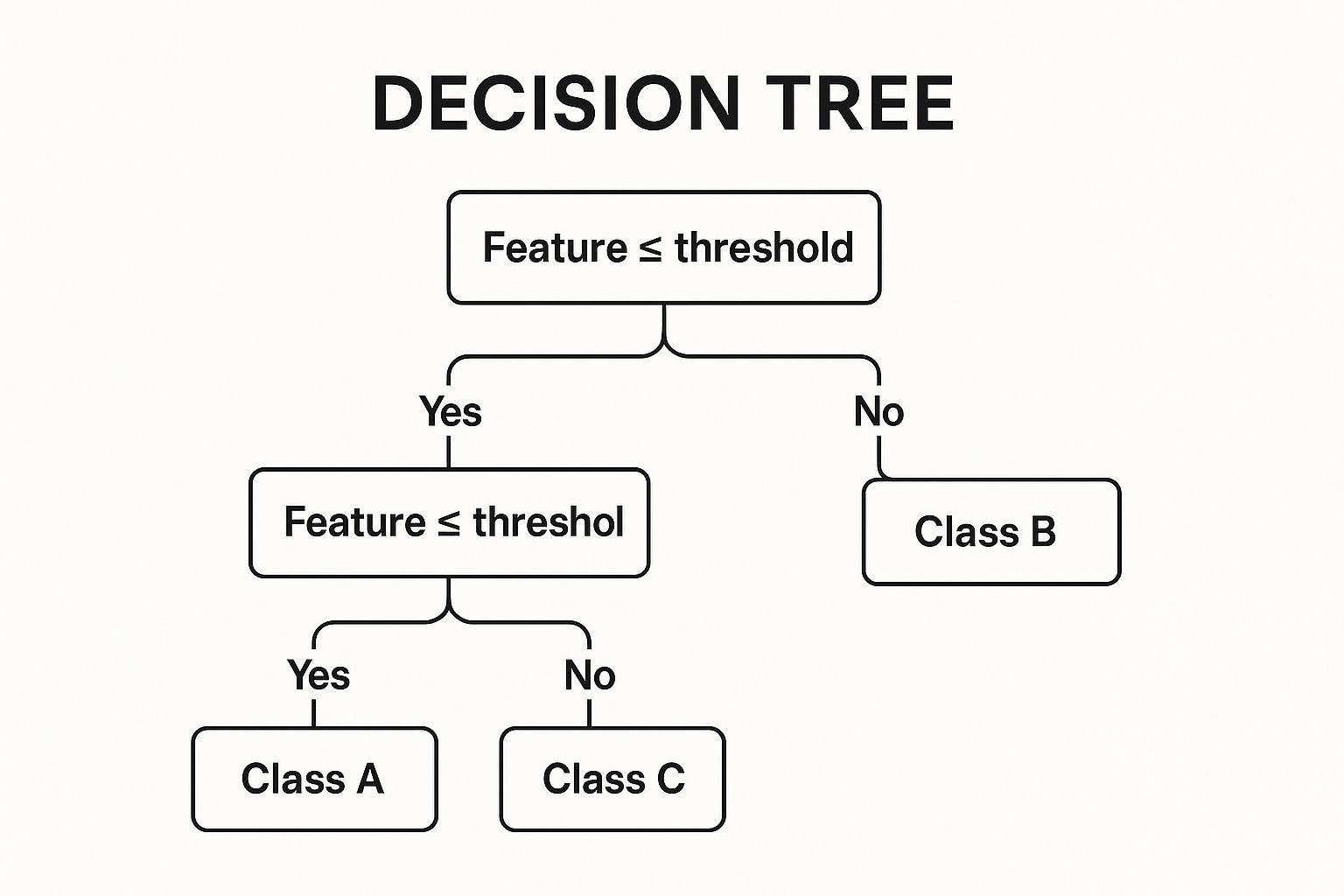
The infographic above visualizes a simplified decision tree for deciding whether to play tennis based on weather conditions. It starts with the outlook, then considers humidity and wind conditions to arrive at a final decision. This example showcases the hierarchical, if-then decision-making process inherent in decision trees. By following the branches based on the specific weather conditions, you arrive at the final decision of whether to play tennis or not.
Key features of decision trees include their intuitive tree-like structure with nodes and branches, their hierarchical, if-then decision-making process, and their ability to handle both categorical and numerical data. As a non-parametric method, a decision tree doesn’t assume any specific data distribution, making it versatile. Furthermore, it supports both classification and regression tasks, predicting categorical labels or continuous numerical outcomes, respectively. Decision trees excel in situations where interpretability is crucial.
Decision trees offer several advantages: they’re easy to understand and interpret, require minimal data preprocessing, can handle both numerical and categorical data, automatically perform feature selection, and are computationally inexpensive to train and predict. However, they also have drawbacks: they’re prone to overfitting, especially with deep trees, exhibit high variance (small changes in data can result in very different trees), can create biased trees if some classes dominate, and are not ideal for continuous numerical outcomes in regression tasks. Individual decision trees generally have lower prediction accuracy than ensemble methods like random forests, a key point of comparison in the “random forest vs decision tree” discussion.
Several real-world applications showcase the power of decision trees. Examples include customer churn prediction in telecommunications, credit risk assessment in banking, disease diagnosis in healthcare, and customer segmentation in marketing.
To effectively utilize decision trees, consider these tips: use pruning techniques to reduce overfitting, set appropriate maximum depth to control complexity, consider cross-validation for hyperparameter tuning, ensure balanced datasets for better performance, and visualize the tree to gain insights into the decision-making process. Learn more about Decision Tree
Pioneering figures in the development and popularization of decision trees include Leo Breiman, J. Ross Quinlan (creator of the ID3 and C4.5 algorithms), and the development of CART (Classification and Regression Trees) by Breiman et al. Decision trees deserve their place in the “random forest vs decision tree” discussion because they serve as the foundational building blocks for more complex ensemble methods like random forests. Understanding their strengths and weaknesses is crucial for appreciating the advancements offered by random forests.
2. Random Forest
In the “random forest vs decision tree” debate, understanding the strengths of each approach is crucial. Random Forest stands out as a powerful ensemble learning method that builds upon the foundation of decision trees. Instead of relying on a single decision tree, Random Forest constructs multiple trees during training. It then combines the predictions of these individual trees to arrive at a final, more accurate prediction. For classification tasks, it uses the mode of the classes predicted by the trees, while for regression tasks, it uses the average prediction. The key to Random Forest’s effectiveness lies in its use of bootstrap aggregating (bagging) and feature randomness, which create an uncorrelated forest of decision trees, thereby reducing overfitting and improving prediction accuracy.

Random Forest boasts several compelling features that contribute to its widespread adoption. It leverages bootstrap sampling—random sampling with replacement—to create diverse training datasets for each tree. Furthermore, at each node of a tree, the algorithm randomly selects a subset of features for consideration, further enhancing diversity and reducing correlation among trees. This combination of bagging and random feature selection leads to a more robust and accurate model compared to single decision trees. Random Forest also provides built-in feature importance calculations, offering valuable insights into the data. The method effectively handles missing values and maintains accuracy even with incomplete datasets. Furthermore, it automatically balances datasets when class distributions are imbalanced, minimizing the impact of skewed data.
The advantages of using Random Forest are numerous. It consistently achieves higher accuracy than individual decision trees, particularly in complex datasets. It is significantly more robust to overfitting compared to single trees, making it suitable for a wider range of applications. Its ability to handle high-dimensional data with numerous features makes it a valuable tool in fields like genomics and finance. The provided feature importance metrics facilitate feature selection and offer insights into the underlying data relationships. Finally, its inherent handling of missing values and automatic dataset balancing simplifies the preprocessing steps in the machine learning pipeline.
However, Random Forest is not without its drawbacks. It is inherently less interpretable than a single decision tree, making it more challenging to understand the reasoning behind its predictions. Computationally, it is more intensive than single trees, requiring more processing power, memory, and storage. Training time also increases with the number of trees, which can be a limiting factor for large datasets. While generally robust to overfitting, Random Forest may still overfit on particularly noisy datasets.
Random Forest has found successful implementations across various domains. In financial markets, it is used for predicting stock prices and assessing market risk. In remote sensing, it aids in land cover classification and analysis of satellite imagery. Fraud detection systems in banking and insurance utilize Random Forest to identify suspicious transactions and patterns. In healthcare, it contributes to medical diagnosis and predictive modeling for patient outcomes. Finally, in e-commerce, it powers recommendation systems that personalize user experiences. Learn more about Random Forest and its broader applications in machine learning infrastructure.
For practitioners, several tips can enhance the effectiveness of Random Forest. A good starting point is to use 100-500 trees and then adjust based on performance metrics. Cross-validation is essential for tuning hyperparameters such as max_depth and min_samples_split. The built-in feature importance metrics can guide feature selection for improved model efficiency. Balancing training speed and accuracy by choosing an appropriate number of estimators (n_estimators) is crucial. Finally, for imbalanced datasets, employing stratified sampling can further improve model performance.
Random Forest’s place in this “random forest vs decision tree” comparison is well-deserved due to its superior accuracy, robustness, and versatility. While decision trees offer interpretability, Random Forest often provides the necessary performance boost for real-world applications, making it a favored choice among data scientists and machine learning practitioners. Popularized by Leo Breiman and Adele Cutler in 2001 and further developed by researchers at Berkeley University, its implementation in the scikit-learn library has contributed significantly to its widespread adoption.
3. Gradient Boosting Machine (GBM)
In the ongoing discussion of random forest vs. decision tree, Gradient Boosting Machine (GBM) emerges as a powerful ensemble method that often surpasses both in predictive performance. While both random forests and decision trees offer valuable approaches to machine learning, GBM builds upon the concept of decision trees in a unique and effective way. Learn more about Gradient Boosting Machine (GBM)
GBM constructs a predictive model by sequentially adding decision trees to an ensemble. Unlike random forests, where trees are built independently, GBM trains each tree to correct the errors made by its predecessors. This sequential, additive nature is key to GBM’s strength. It employs gradient descent to minimize a chosen loss function, effectively steering the model towards increasingly accurate predictions with each new tree. The base learners in GBM are typically shallow decision trees, making the model less prone to memorizing the training data and improving its ability to generalize to unseen data. GBM supports both classification and regression tasks, broadening its applicability across various domains.
The sequential approach and use of gradient descent give GBM several advantages. It excels at capturing complex, non-linear relationships in data and often achieves higher accuracy than random forests, particularly in datasets with intricate patterns. GBM also handles mixed data types effectively and exhibits robustness to outliers and missing data (with proper handling during implementation). Furthermore, GBM models provide feature importance metrics, offering insights into the factors driving predictions – a valuable asset for interpretation and feature selection.
However, GBM is not without its drawbacks. Its sequential nature makes it computationally more expensive and harder to parallelize than random forest. It is also more prone to overfitting, particularly if hyperparameters are not carefully tuned. This sensitivity necessitates meticulous optimization of parameters like learning rate, the number of trees (estimators), and regularization parameters. Early stopping, based on performance on a validation set, is another crucial technique to prevent overfitting. Starting with shallow trees (e.g., depth 3-5) is often recommended and monitoring training vs. validation performance is vital for guiding the training process.
GBM’s power is demonstrably evident in its widespread successful implementations. Examples include web search ranking at Yahoo (via the MART algorithm), click-through rate prediction in online advertising, and numerous winning solutions in Kaggle competitions. It’s also widely applied in fields such as energy consumption forecasting and financial risk modeling, showcasing its versatility and performance.
For those looking to leverage GBM’s capabilities, several tips are essential: Use a small learning rate (typically in the range of 0.01 to 0.1) and a larger number of estimators. Regularization techniques like L1 or L2 regularization should be applied to prevent overfitting. Early stopping is strongly advised.
GBM’s development and popularization are credited to Jerome H. Friedman of Stanford University. Its influence has been further amplified by efficient implementations in popular libraries like XGBoost (by Tianqi Chen), LightGBM (by Microsoft), and CatBoost (by Yandex). These libraries have made GBM more accessible and have fueled its adoption across diverse domains. GBM’s combination of predictive power and interpretability firmly establishes its place in the discussion of random forest vs. decision tree, offering a powerful alternative for those seeking high accuracy and detailed insights.
4. XGBoost (Extreme Gradient Boosting)
XGBoost (Extreme Gradient Boosting) is a powerful and versatile machine learning algorithm that has gained immense popularity in recent years, especially in structured/tabular data problems. While often compared to random forests and decision trees due to its tree-based nature, XGBoost distinguishes itself through its optimized implementation of gradient boosting. It’s not simply an alternative, but rather an advancement, building upon the strengths of gradient boosting machines (GBMs) with enhancements focused on speed, performance, and scalability. It works by sequentially building an ensemble of decision trees, where each subsequent tree corrects the errors of its predecessors. Instead of simply averaging predictions like in random forests, XGBoost employs gradient descent to minimize a loss function, effectively learning from the residuals of previous trees. This iterative process allows XGBoost to capture complex relationships in the data and achieve high predictive accuracy.

XGBoost’s prominence in the machine learning landscape is due in part to its numerous advantages. Key features include its optimized implementation of gradient boosting, regularization techniques (L1 and L2) to prevent overfitting, built-in handling of missing values, tree pruning using a depth-first approach, parallel and distributed computing capabilities, and cache optimization for efficient memory usage and out-of-core computation. These features translate to generally higher performance and faster training and inference speeds compared to standard GBMs. It also offers built-in cross-validation, simplifying model evaluation and hyperparameter tuning.
While XGBoost often outperforms traditional GBMs and even random forests in many scenarios, it’s important to be aware of its potential drawbacks. It can be more complex to tune than random forests, requiring careful consideration of its numerous hyperparameters. If not properly configured, XGBoost can be susceptible to overfitting. Furthermore, its ensemble nature makes it less interpretable than single decision trees, although techniques exist to explore feature importance. Finally, for extremely large datasets, memory management can become a concern.
XGBoost’s effectiveness is demonstrably proven through its widespread adoption and success in diverse applications. It has been the winning algorithm in numerous Kaggle competitions, highlighting its predictive power. Notable real-world examples include its contribution to the Higgs Boson discovery at CERN, its application in ad click-through rate prediction at major tech companies, use in credit scoring by financial institutions, and implementation in fraud detection systems.
When choosing between random forest vs decision tree, or even more advanced algorithms, XGBoost shines when high predictive accuracy and efficiency are paramount. Its ability to handle complex relationships in the data, coupled with its speed and scalability, makes it well-suited for a wide range of tasks.
Here are some tips for effectively utilizing XGBoost:
- Use early stopping to prevent overfitting: Monitor performance on a validation set and stop training when improvement plateaus.
- Tune
learning_rateandn_estimatorstogether: A smaller learning rate generally requires more trees. - Consider setting a
max_depthto control complexity: Limiting tree depth can help prevent overfitting. - Use cross-validation for hyperparameter tuning: This ensures a robust evaluation of model performance.
- Scale features for better performance: This can improve convergence speed and overall accuracy.
- Monitor feature importance for feature selection: XGBoost provides insights into the relative importance of different features.
XGBoost was popularized by Tianqi Chen and Carlos Guestrin in 2016, originating from the University of Washington and the DMLC (Distributed Machine Learning Community). Although no single website serves as the definitive resource, the project’s documentation and numerous online tutorials offer comprehensive information.
5. LightGBM
While comparing random forest vs decision tree, it’s important to consider alternative tree-based algorithms that often outperform both. LightGBM (Light Gradient Boosting Machine) is one such powerful algorithm. Developed by Microsoft, it’s a gradient boosting framework that uses tree-based learning algorithms. Designed for distributed and efficient training, LightGBM prioritizes both accuracy and speed, making it a compelling alternative in many scenarios. It achieves this efficiency through innovative techniques like Gradient-based One-Side Sampling (GOSS) and Exclusive Feature Bundling (EFB), which significantly enhance the scalability and speed of traditional gradient boosting methods.

LightGBM’s core strength lies in its unique leaf-wise (best-first) tree growth strategy. Unlike level-wise growth employed by many other algorithms, including some implementations of random forest and decision trees, LightGBM grows trees leaf by leaf, choosing the leaf that offers the maximum reduction in loss. This approach can lead to more complex trees that capture intricate patterns in data, contributing to higher accuracy. GOSS further enhances efficiency by focusing on the gradients of data instances with larger errors, effectively reducing the contribution of instances with smaller gradients during training. EFB addresses the challenge of sparse data by bundling mutually exclusive features, reducing the number of features needed for training without significant information loss. The histogram-based algorithm employed by LightGBM for handling continuous features also contributes to its speed and efficiency.
LightGBM has found successful applications across diverse domains. Microsoft uses it for user behavior prediction, and it has seen widespread adoption in click-through rate prediction for online advertising. Its speed and efficiency also make it well-suited for real-time prediction services, financial market forecasting, and recommendation systems in e-commerce, often exceeding the performance of both random forest and single decision trees.
Features and Benefits:
- Leaf-wise (best-first) Tree Growth: Focuses on maximizing loss reduction at each step, leading to potentially higher accuracy.
- Gradient-based One-Side Sampling (GOSS): Improves training speed by focusing on data instances with larger gradients.
- Exclusive Feature Bundling (EFB): Optimizes the handling of sparse data for improved efficiency.
- Histogram-based Algorithm: Efficiently bins continuous features for faster training.
- Native Categorical Feature Support: Eliminates the need for manual one-hot encoding.
- Optimized for Speed and Memory Efficiency: Handles large datasets effectively.
- Parallelization Capability: Enables faster computation through distributed processing.
Pros:
- Faster training speed compared to XGBoost and standard Gradient Boosting Machine (GBM).
- Lower memory usage than other gradient boosting implementations.
- Often achieves better accuracy than random forest in many scenarios, especially on large datasets.
- Efficiently handles large datasets.
- Built-in support for categorical features.
- Supports parallel processing for faster computation.
Cons:
- Leaf-wise growth can lead to overfitting on small datasets, requiring careful parameter tuning.
- Relatively less extensive documentation and community support compared to more established algorithms like XGBoost.
- Sensitivity to hyperparameter settings, necessitating careful tuning.
- Less interpretable than single decision trees, although more so than deep learning models.
Tips for Using LightGBM:
- Control model complexity by using a larger
num_leavesvalue while restrictingmax_depth. - Leverage built-in categorical feature support using the
categorical_featureparameter. - Prevent overfitting by employing early stopping techniques.
- For large datasets, consider reducing
max_binfor faster training. - Set
min_data_in_leafto avoid overfitting, especially on smaller datasets. - Utilize bagging with
feature_fractionandbagging_fractionfor improved robustness.
Popularized By: Microsoft Research, Guolin Ke (Microsoft Research Asia), DMTK (Distributed Machine Learning Toolkit) team
LightGBM deserves its place in any comparison of random forest vs decision tree because it offers a compelling alternative that frequently outperforms both in terms of speed and accuracy, particularly on large datasets. While it may require more careful tuning, its ability to handle large datasets and complex relationships makes it a valuable tool for anyone working with tree-based models. Its efficient handling of categorical features further simplifies the modeling process, offering a significant advantage over traditional methods that require explicit encoding. While random forests and decision trees remain valuable tools, understanding LightGBM provides data scientists with a powerful alternative for tackling complex prediction tasks.
6. CatBoost: A Powerful Gradient Boosting Alternative to Random Forests and Decision Trees
While comparing random forest vs decision tree models, it’s important to consider other powerful tree-based algorithms. CatBoost, short for Category Boosting, earns its place on this list as a high-performance gradient boosting on decision trees library developed by Yandex. It stands out for its exceptional handling of categorical features, a common challenge in many datasets, and often provides a significant advantage over traditional methods like random forests and single decision trees.
CatBoost distinguishes itself through several key innovations:
- Native Handling of Categorical Features: Unlike random forests or decision trees which require manual encoding, CatBoost automatically handles categorical features efficiently and effectively, reducing preprocessing time and potential information loss. It leverages an innovative algorithm that minimizes prediction shift, a common issue with other boosting methods.
- Ordered Boosting: This permutation-driven alternative to traditional gradient boosting further reduces prediction shift, improving model generalization and robustness. It creates symmetrical trees based on category combinations, which offers a more effective way to handle categorical features than one-hot encoding or other preprocessing techniques.
- Fast and Scalable: CatBoost offers GPU acceleration, enabling faster training and inference. This makes it a viable option even for large datasets, although it can be slower than LightGBM in some cases.
When comparing random forest vs decision tree for a specific task, especially one with categorical data, CatBoost often emerges as a superior choice. Here’s why:
When to Use CatBoost:
- Datasets with significant categorical features: If your data includes numerous or complex categorical variables, CatBoost can significantly outperform methods that require manual encoding.
- Limited tuning time: CatBoost’s robust performance out-of-the-box minimizes the need for extensive hyperparameter tuning, making it an efficient choice.
- Concerns about overfitting: CatBoost’s built-in mechanisms combat overfitting, allowing for more reliable predictions.
- Imbalanced Datasets: CatBoost has proven to be effective on imbalanced datasets, a common problem in areas like fraud detection.
- Need for fast inference: CatBoost offers fast inference times, which is essential for deploying models in production systems.
Pros:
- Superior handling of categorical features
- Robust performance with minimal tuning
- Less prone to overfitting
- Fast inference time
- Good performance on imbalanced datasets
- Built-in visualization tools
Cons:
- Can be slower to train than LightGBM on large datasets
- Higher memory consumption during training
- Relatively newer with a smaller community than XGBoost
- Less flexibility in some customization aspects
- Limited support for distributed training
Examples of Successful Implementations:
- Search ranking at Yandex
- Recommendation systems with categorical features
- Financial risk assessment
- Fraud detection with imbalanced classes
- Weather forecasting with mixed data types
Actionable Tips:
- Leverage native categorical feature handling with the
cat_featuresparameter. - Use
gpu_ram_partparameter when training on GPU. - For large datasets, consider Bayesian bootstrapping.
- Experiment with different growing policies (
SymmetricTreeorDepthwise). - Utilize
od_waitparameter for effective early stopping. - Start with default parameters; they are often well-optimized.
Popularized By: Yandex Research team, Anna Veronika Dorogush (Yandex), Andrey Gulin (Yandex), Liudmila Ostroumova Prokhorenkova
While random forest and decision tree models remain valuable tools, CatBoost provides a compelling alternative, particularly when dealing with categorical data. Its ability to handle these features natively, combined with its robust performance and built-in safeguards against overfitting, make it a powerful addition to any data scientist’s toolkit.
7. Extra Trees (Extremely Randomized Trees)
When comparing random forest vs decision tree algorithms, a powerful alternative often emerges: Extra Trees (Extremely Randomized Trees). This ensemble learning method, like Random Forest, leverages the wisdom of the crowd by constructing multiple decision trees and averaging their predictions. However, Extra Trees injects an additional layer of randomness into the process, distinguishing it from its close cousin and offering unique advantages in certain scenarios.
Extra Trees distinguishes itself from Random Forest through two key modifications:
- Bootstrap Aggregating (Bagging) Removal: Unlike Random Forest, which utilizes bootstrap samples (randomly sampled subsets with replacement) of the dataset to train each tree, Extra Trees uses the entire original dataset for each tree’s construction. This seemingly minor change has significant implications for variance reduction.
- Completely Random Split Point Selection: While Random Forest searches for the best split point at each node based on a subset of features, Extra Trees takes a more radical approach. It selects split points entirely at random. This extreme randomization further diminishes the correlation between individual trees, significantly reducing overfitting and boosting generalization performance.
How Extra Trees Works:
The algorithm constructs multiple decision trees. For each tree, the entire dataset is used. At each node of the tree, a random subset of features is considered. Instead of searching for the optimal split point among those features, Extra Trees selects a split point completely randomly for each feature. This process is repeated recursively until leaf nodes are created. When making a prediction, each tree casts its vote, and the final prediction is determined by averaging the predictions of all trees (for regression) or by majority voting (for classification).
Why Extra Trees Deserves Its Place in the Random Forest vs Decision Tree Discussion:
Extra Trees offer a unique trade-off in the bias-variance spectrum. While Random Forest focuses on minimizing bias by optimizing splits, Extra Trees prioritizes variance reduction through extreme randomization. This makes Extra Trees especially valuable in situations with high-dimensional data and noisy features, where the risk of overfitting is paramount. Furthermore, its simplified split selection process results in significantly faster training times compared to Random Forest, a critical advantage when dealing with large datasets.
Pros:
- Often reduces variance further than Random Forest: The extreme randomization reduces the correlation between individual trees, leading to better generalization.
- Faster training time than Random Forest: Random split selection significantly accelerates the training process.
- Effective for high-dimensional data: Less susceptible to the curse of dimensionality.
- Less prone to overfitting on noisy features: Robust to irrelevant or noisy data.
- Good performance with minimal tuning: Often requires less hyperparameter optimization.
- Provides feature importance metrics: Allows for insights into feature relevance.
Cons:
- May have higher bias than Random Forest in some cases: The random split selection can introduce bias, particularly if feature relevance varies significantly.
- Can underperform Random Forest when feature relevance varies significantly: In scenarios where some features are highly predictive, the random splitting may miss optimal splits.
- Less interpretable than single decision trees: The ensemble nature makes interpretation more challenging.
- Requires more trees than Random Forest for stable predictions: Due to the increased randomness, more trees are needed to achieve stable performance.
- May struggle with strongly relevant features due to random splitting: Random splits might not capture the full predictive power of important features.
Examples of Successful Implementation:
- Image classification tasks: Extra Trees have demonstrated success in various image recognition problems.
- Genomic data analysis: Effective for handling high-dimensional genomic datasets.
- Text categorization: Used for classifying text documents into different categories.
- Remote sensing applications: Applied to analyze remote sensing data for land cover classification.
- As a feature selection method for other models: The feature importance scores from Extra Trees can guide feature selection for subsequent models.
Tips for Using Extra Trees:
- Use more trees than in Random Forest (e.g., 500-1000): This compensates for the increased randomness.
- Adjust
max_featuresto control randomness in feature selection: This parameter determines the number of features considered at each split. - Consider Extra Trees when training speed is important: If time is a constraint, Extra Trees can provide a faster alternative to Random Forest.
- Try both Random Forest and Extra Trees to compare performance: The best algorithm depends on the specific dataset and problem.
- Use for feature selection before applying other algorithms: Leverage the feature importance metrics to identify relevant features.
- Set
min_samples_splithigher than in Random Forest to combat noise: This helps prevent overfitting on noisy data.
Popularized By:
Pierre Geurts, Damien Ernst, and Louis Wehenkel (2006), University of Liège, Belgium. The algorithm is readily available in popular machine learning libraries like scikit-learn.
Algorithm Performance Comparison: Random Forest vs Others
| Algorithm | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Decision Tree | Low – straightforward tree construction and splitting | Low – minimal preprocessing, low computational cost | Moderate accuracy; interpretable but prone to overfitting | Simple classification/regression, interpretable models | Easy to understand; handles numeric & categorical data; fast training |
| Random Forest | Moderate – ensemble of many trees with bagging | Medium to High – more memory and computation needed | Higher accuracy and robustness than single trees | High-dimensional data, classification, regression, imbalanced data | Reduces overfitting; feature importance; handles missing data |
| Gradient Boosting Machine (GBM) | High – sequential training with gradient descent | Medium to High – slower training, sequential process | High accuracy but sensitive to noise and overfitting | Complex modeling tasks, competitions, non-linear relationships | Strong predictive power; handles mixed data; provides feature importance |
| XGBoost | High – optimized, parallel gradient boosting implementation | Medium to High – efficient but requires tuning | Very high accuracy with fast training and inference | Large-scale data, competitions, scenarios demanding speed & accuracy | Efficient and fast; regularization included; handles missing data |
| LightGBM | High – leaf-wise growth with advanced sampling techniques | Medium – optimized for speed and memory | High accuracy with faster training than XGBoost | Large datasets, low latency predictions, categorical features | Faster training; lower memory usage; built-in categorical feature support |
| CatBoost | High – ordered boosting and native categorical handling | Medium to High – GPU acceleration possible | Robust accuracy, less overfitting, good on categorical & imbalanced data | Categorical data, imbalanced datasets, fast inference needs | Native categorical handling; less tuning needed; ordered boosting |
| Extra Trees (Extremely Randomized Trees) | Moderate – very randomized splitting without bootstrapping | Medium – faster training but needs more trees | Comparable to or better variance reduction than RF | High-dimensional data, noisy features, faster training priority | Faster training; low variance; good feature importance |
Making the Right Choice for Your Data
Choosing between a random forest vs decision tree, or exploring more advanced methods like gradient boosting (GBM, XGBoost, LightGBM, CatBoost) and Extra Trees, depends heavily on your specific needs. As we’ve explored, a single decision tree, while interpretable, can be prone to overfitting. Random forests address this by combining multiple trees, increasing robustness and predictive accuracy. However, the added complexity might sacrifice some interpretability. Gradient boosting methods like XGBoost and LightGBM often provide superior performance on complex datasets but require careful tuning. For teams seeking OpenAI alternatives due to cost, data privacy, or specialized features, integrating powerful tree-based models like these, and others described here, from other providers offers substantial benefits. Choosing the right model is a critical step in any machine learning project, impacting everything from development time to final model performance.
Mastering these nuances empowers you to leverage the full potential of tree-based models, extracting valuable insights and making more accurate predictions. This translates to better business decisions, more effective resource allocation, and ultimately, a stronger competitive edge in today’s data-driven world. The optimal choice is the one that best aligns with your project’s unique characteristics and desired outcomes.
Ready to streamline your model selection and optimization process for tree-based algorithms? Explore the power of DATA-NIZANT, a platform designed to simplify and enhance your workflow when working with algorithms like random forest and decision trees, from selection to deployment. Deepen your understanding and unlock the true potential of your data.




