
Building Your Python Topic Modeling Toolkit
Let’s talk about setting up your Python environment for topic modeling. Trust me, getting this right from the start can save you a ton of headaches down the road. I’ve learned that a well-configured toolkit makes all the difference, especially when projects start to get complex.
Essential Python Libraries
First, you’ll need a few key Python libraries. Gensim is my go-to for topic modeling. It’s got efficient implementations of algorithms like LDA and LSI. I’ve personally used it for everything from analyzing customer reviews to digging into academic papers, and it’s always performed well. For preprocessing, NLTK (the Natural Language Toolkit) is indispensable. Think of it as your Swiss Army knife for text cleaning—tokenization, stemming, stop word removal, you name it. Finally, for visualizations, pyLDAvis is a game-changer. It makes exploring and understanding your topic models so much easier, especially when you need to share your findings with people who aren’t as technical.
Setting Up Your Workspace
For my topic modeling projects, I usually work in Jupyter Notebooks. They’re great because you can experiment with code, visualize results, and document everything in one place. Being able to see your results immediately is incredibly helpful when you’re tweaking models and interpreting the output.
This screenshot shows the Jupyter logo. The interactive nature of Jupyter makes it perfect for iterative tasks like topic modeling. You’re constantly adjusting parameters and checking the results, and Jupyter makes that workflow much smoother.
Managing Memory and Scaling Up
When dealing with larger datasets, memory management becomes critical. I once tried to run a topic model on a huge corpus of news articles on my local machine, and it completely froze up. Lesson learned! For massive datasets, cloud platforms like AWS or Google Cloud are your best bet. They provide the scalability and processing power you need. Even for moderately sized projects, optimizing your code can make a big difference. Things like using generators and iterators in Python can significantly reduce your memory footprint.
Dealing with Version Conflicts
Finally, let’s talk about version conflicts. Inconsistent library versions can lead to some really frustrating debugging sessions. Take it from me, using a virtual environment for each project is a lifesaver. It isolates your project’s dependencies and prevents clashes with other projects. Tools like conda or venv make this easy to manage. It only takes a few minutes to set up, and it’s absolutely worth it. By building a solid toolkit and being mindful of these potential issues, you’ll spend less time wrestling with technical problems and more time uncovering valuable insights from your data.
Text Preprocessing That Makes The Difference
Raw text data, whether it’s social media chatter or complex legal documents, is inherently messy. Over time, I’ve learned that preprocessing is more than just a preliminary step; it’s a crucial factor influencing the performance of your Python topic models. This section shares some hard-won insights, gleaned from both successful projects and, let’s be honest, a few face-palm moments.
Handling Special Characters and Context
Special characters are a common headache. While it’s tempting to just nuke them all, I’ve found that this can strip away valuable context. Think about analyzing social media sentiment. Emoticons like “:)” or “:(” are packed with meaning. Removing them is like throwing away gold. Instead, consider replacing them with descriptive tokens, such as “positive_emoji” or “negative_emoji.” This preserves the sentiment while making the data more palatable for your model.
Aggressive Cleaning: Help or Hindrance?
How aggressive should you be with your cleaning? It depends. With noisy data like online forum posts, scrubbing out HTML tags, URLs, and excessive punctuation can be a lifesaver. But in other cases, like analyzing legal documents, specific punctuation and capitalization can be critical. Overly aggressive cleaning could distort the meaning entirely. It’s a delicate balance: remove the noise without sacrificing the signal.
Tokenization Strategies and Content Types
Tokenization, the process of breaking text into individual words or phrases (tokens), is another key step. The best approach varies with the content. Standard word tokenization might work fine for news articles. But if you’re working with technical documents or code, you’ll likely need specialized tokenizers that understand camel case and syntax nuances. For more on tokenization strategies, check out this guide: Check out our guide on tokenization in NLP.
Stop Words, Stemming, and Lemmatization
Stop words – common words like “the,” “a,” and “is” – are often removed to improve model performance. However, be mindful of context. I once removed “not” from a sentiment analysis project, and my model’s accuracy tanked. Stemming (reducing words to their root, like “running” to “run”) and lemmatization (finding the dictionary form, like “better” to “good”) can be useful, but proceed with caution. Stemming can oversimplify, and lemmatization can be computationally expensive.
Multilingual Content and Domain-Specific Vocabulary
Multilingual content adds another layer of complexity. You might need language-specific tokenizers, stop word lists, and stemming/lemmatization rules. Similarly, domain-specific vocabulary requires careful handling. Medical jargon won’t help a model trained on social media data. A custom vocabulary or a pre-trained model tailored to your domain can make a world of difference. Take a look at the infographic below, which shows the popularity of different topic modeling algorithms:
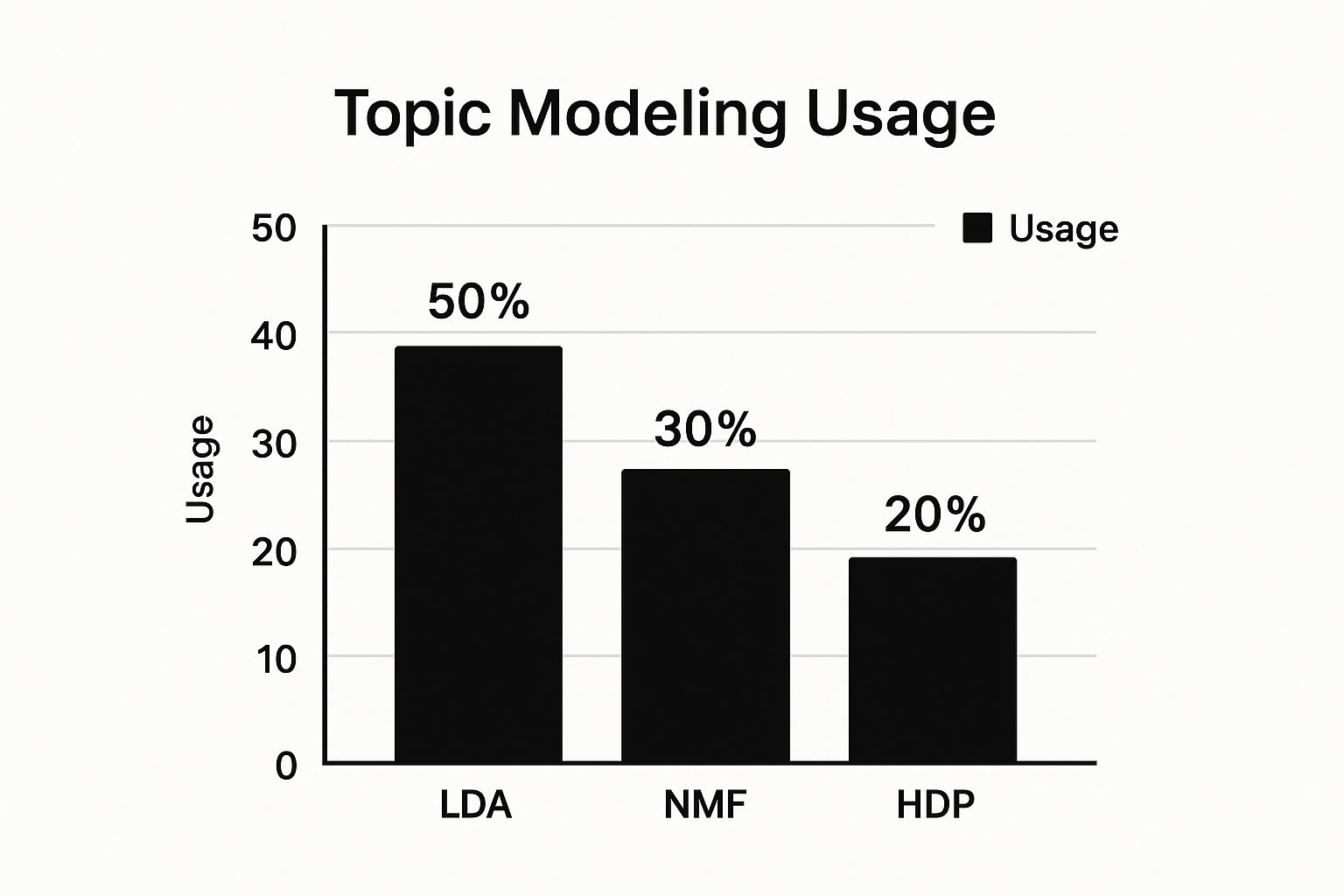
LDA takes the lead, followed by NMF and HDP. This shows how common LDA is, but it also emphasizes the importance of exploring other algorithms, especially if you have specific needs.
Before we wrap up, let’s take a closer look at several text preprocessing techniques:
The following table summarizes the key text preprocessing techniques and their potential impacts on model performance, helping you make informed decisions during your topic modeling journey.
| Technique | Use Case | Pros | Cons | Performance Impact |
|---|---|---|---|---|
| Removing Special Characters | Cleaning noisy text data (e.g., social media, web scraping) | Removes noise and simplifies text | Potential loss of meaning (e.g., emoticons, punctuation in legal text) | Can improve or degrade performance depending on data and how it’s done |
| Lowercasing | Normalizing text | Reduces vocabulary size | Loss of case-sensitive information (e.g., proper nouns) | Generally positive impact due to reduced dimensionality |
| Stop Word Removal | Removing common words | Reduces noise, improves processing speed | Can remove contextually important words | Generally improves performance but requires careful stop word list selection |
| Stemming | Reducing words to root form | Reduces vocabulary size, groups related words | Can oversimplify and lose meaning | Can improve performance on some tasks but may also reduce accuracy |
| Lemmatization | Converting words to dictionary form | Preserves meaning better than stemming | Computationally more expensive | Generally preferred over stemming when accuracy is critical |
| Tokenization | Splitting text into words/phrases | Essential for NLP tasks | Requires choosing appropriate tokenization method | Choice of method can significantly impact downstream tasks |
By carefully considering these preprocessing steps, you can dramatically improve the accuracy and interpretability of your topic models. It’s all about understanding your data and making smart choices to keep what’s important and ditch what’s not.
Picking The Right Algorithm For Your Project
Choosing the right topic modeling algorithm is critical. A bad choice can lead to wasted time and confusing results. I’ve seen it happen – projects stalled, teams frustrated – whether we were analyzing customer feedback or sorting through piles of research papers. So, let’s talk about some popular algorithms and how to choose the best one for your needs.
LDA: The Workhorse
Latent Dirichlet Allocation (LDA) is the go-to algorithm for topic modeling in Python, and there’s a good reason why. It’s generally effective, relatively easy to use, and produces topics that make sense. In one project, we used LDA to analyze customer reviews for a software product. We were able to pinpoint loved and loathed features, which helped the developers prioritize improvements and address user pain points.
NMF: When Simplicity Wins
Non-negative Matrix Factorization (NMF) is simpler than LDA. It’s often faster and easier on your computer’s resources. I’ve found NMF works particularly well with shorter texts like tweets or product descriptions. For instance, we used NMF to analyze social media buzz around a marketing campaign. We quickly identified the main themes and sentiment, allowing us to tweak our messaging in real-time and boost campaign performance.
BERTopic: Adding Context to the Mix
Newer algorithms like BERTopic use pre-trained language models to understand the context of words. This can lead to more accurate and nuanced topics, especially with complex or ambiguous text. I’ve started using BERTopic for categorizing research papers, where understanding the meaning of technical jargon is key. While it takes more computing power, BERTopic can unlock deeper insights than traditional methods.
Making The Choice: A Decision Framework
How do you choose the right algorithm? Here’s the framework I use:
- Data Size and Complexity: For smaller, simpler datasets, NMF might be enough. Larger, more complex texts might need LDA or BERTopic.
- Interpretability: If understanding the topics is crucial, LDA is generally a solid pick. BERTopic can also be interpretable, but it requires more careful examination.
- Computational Resources: NMF is the least demanding. LDA needs more power, and BERTopic requires the most.
- Desired Level of Nuance: If you need highly specific topics, BERTopic’s context awareness can be a real advantage.
Python’s relevance in topic modeling goes beyond academic exercises. Its practicality shines in real-world applications. For example, at PyCon, comparative analyses of Python-based topic modeling libraries showcased their effectiveness in policy analysis and other real-world uses. These libraries handle tasks like document classification and text summarization, highlighting Python’s versatility with different types of text data. Discover more insights about this here.
Evaluating Algorithm Performance
Test different algorithms on your data. Don’t just rely on general benchmarks. I’ve seen simpler methods like NMF outperform more complex ones like LDA. Experimenting early on saves time and headaches. You might be interested in: Machine Learning Mastery.
Real-World Considerations
Picking the right algorithm is just the beginning. Preprocessing, parameter tuning, and evaluation are equally important. We’ll explore these in the next sections. But for now, understanding the strengths and weaknesses of each algorithm puts you on the right path. Experiment, see what works, and unlock valuable insights from your text data. Don’t be afraid to try different approaches!
Training Models That Deliver Real Insights
So, we’ve covered preprocessing and algorithms. Now, let’s get down to the real deal: training effective topic models in Python. This isn’t just about code; it’s about making smart choices that separate insightful models from glorified random word generators. I’ll share some hard-won wisdom from my own topic modeling adventures.
Finding the Sweet Spot for Topic Numbers
Many tutorials suggest picking an arbitrary number of topics. In practice, it’s more of a journey. Metrics like coherence scores are helpful, but they only tell part of the story. My approach? Combine coherence scores with a good old-fashioned manual review of the topics. The goal is balance: enough topics to capture the nuances in your data, but not so many that they become too specific and lose their meaning.
Hyperparameter Tuning: Making a Real Difference
Hyperparameters, those settings that control your model’s learning process, are more important than they might seem. Don’t just stick with the defaults! Experiment with alpha and beta (controlling topic and word distributions). See how they impact your topics. Small adjustments can dramatically improve coherence and how easily you can interpret the results. Python shines in topic modeling, especially for analyzing large datasets. For example, a study on the digital economy used Python libraries to analyze 8,321 documents from the Scopus database. They used Latent Dirichlet Allocation (LDA) to uncover three main topics, with “Digital Transformation” dominating at 56.6% of the tokens. By tweaking parameters like α and η, they boosted the coherence score to 0.4415. Check out the full study.
Recognizing When Your Model is Actually Working
How can you tell if your model is genuinely insightful or just producing random word salads? Go beyond the metrics. Do the topics make sense given your data? Do they align with what you already know about the subject? If you’re analyzing customer reviews, do the topics reflect real product features or customer issues? If not, it’s time to revisit your approach.
Iterative Refinement: A Practical Example
Imagine training an LDA model on news articles. You start with 10 topics and default alpha and beta values. After training, some topics seem too broad and overlap. So, you increase the topic count to 15 and slightly adjust alpha. Retraining reveals more distinct topics, reflecting the various themes in the news. This process of tweaking, training, and reviewing is the core of effective topic modeling.
Handling Convergence Issues and Model Complexity
Sometimes, your model might struggle to converge, meaning it can’t find a stable solution. This can happen with large datasets or complex models. Try increasing the number of passes or changing the initialization method. Be mindful of model complexity, too. More complex models are powerful but demand more data and processing power. Find the balance between complexity and practicality.
The Art of Validation: Domain Knowledge Matters
Even the most advanced Python topic modeling techniques are pointless if they don’t reflect reality. Validate your findings using your own expertise. If you have access to a subject matter expert, have them review the topics and give feedback. This real-world validation is key for ensuring your model’s insights are both relevant and actionable. Speaking of practical advice, check out our guide on ARIMA in Python.
Computational Trade-offs and When to Stop Tweaking
Topic modeling, especially with large datasets, can be computationally demanding. Keep this in mind. A simpler model with slightly lower coherence might be better if it trains significantly faster. Know when to stop tweaking and start analyzing. The ultimate goal is to extract insights, not chase perfect metrics.
Gensim: Your Topic Modeling Ally
The Gensim library is a powerful toolkit for training and evaluating topic models in Python. I rely on it for LDA, LSI, and other algorithms.

This screenshot shows the Gensim logo. Gensim’s efficient implementations make it invaluable for any Python topic modeling project, ensuring smooth and effective model training. It’s a must-have for anyone working with text data in Python.
By understanding these practical considerations, you can go beyond theory and train models that provide real, actionable insights. Remember, it’s an iterative journey, not a one-size-fits-all solution. Experiment, learn from your mistakes, and always check your results against your own domain knowledge.
Evaluation Methods That Actually Matter
Evaluating a Python topic model isn’t just about ticking boxes with coherence scores. It’s about truly understanding if your model is uncovering genuine insights or simply generating statistically plausible noise. I’ve encountered countless models that appear fantastic in theory but completely fail in practice. So, let’s explore evaluation methods that genuinely make a difference.
Understanding Perplexity and Coherence
Perplexity assesses how effectively your model predicts unseen data. A lower perplexity is generally preferred, but it doesn’t tell the whole story. It’s a bit like judging a book by its cover – a captivating cover doesn’t guarantee a compelling narrative. Coherence, on the other hand, measures the semantic relatedness of words within a topic. Higher coherence typically translates to more easily interpretable topics. In my experience, prioritizing coherence often results in more practical and insightful models.
So, while perplexity offers a general overview, coherence often proves a more reliable guide in practical applications.
Beyond the Metrics: Validating with Domain Expertise
Numbers alone aren’t enough. Incorporate your own domain knowledge, or better yet, consult a subject matter expert. Once, while developing a topic model for medical research papers, I shared my results with a physician. Their feedback was invaluable, highlighting topics that were logical, those that were overly broad, and some that were simply incorrect. This real-world validation is absolutely essential. Expert insight can uncover blind spots and provide context that pure statistics might miss.
A/B Testing: Comparing Model Configurations
Just like any machine learning endeavor, A/B testing various model configurations is crucial. Experiment with different numbers of topics, adjust the alpha and beta parameters, and even explore different algorithms. I recall spending weeks fine-tuning a Latent Dirichlet Allocation (LDA) model, only to discover that Non-negative Matrix Factorization (NMF) was a far better fit for my specific dataset. Systematic testing is the key to finding the optimal approach.
Don’t be afraid to try different combinations; you might be surprised by the results.
Detecting Overfitting: Don’t Be Fooled by Data Quirks
Overfitting is a common trap. Your model becomes so attuned to the training data that it struggles with new, unseen data. I’ve run into this when working with datasets containing unique quirks or biases. To identify overfitting, partition your data into training and testing sets. If your model excels on training data but falters on testing data, overfitting is likely the culprit.
A well-generalized model should perform consistently across different subsets of data.
Iterative Improvement: Learning from Real-World Projects
Building an effective topic model is an iterative journey of training, evaluating, refining, and repeating. This approach has evolved through numerous client projects. Begin with a simple model and progressively increase complexity, consistently checking for improvement at each stage. Don’t hesitate to experiment and learn from any setbacks.
Each iteration brings you closer to a model that delivers meaningful insights.
Honest Assessment: When is Your Model Ready?
Knowing when your model is “good enough” is a crucial judgment call, guided by your project objectives. Are you aiming for a broad understanding of the topics within your data, or do you require highly specific categories? Your evaluation criteria will vary accordingly. Be candid about your model’s limitations – acknowledging areas for improvement is always preferable to deploying a flawed model that produces misleading results.
A realistic assessment sets the stage for future refinements and ensures responsible application of your model.
Evaluating with Key Metrics
Understanding the metrics used to evaluate topic models is crucial. The following table provides a breakdown of key metrics, their interpretations, and how they can inform your decisions.
| Metric | Range | Interpretation | Best Use Case | Limitations |
|---|---|---|---|---|
| Perplexity | > 0 | Lower is better; measures how well the model predicts unseen data | Comparing different models or hyperparameter settings | Doesn’t always correlate with human interpretability |
| Coherence Score | Typically 0-1 | Higher is better; indicates semantic similarity within topics | Evaluating topic quality and interpretability | Different coherence measures can yield different results |
By integrating these methods, you can move beyond basic metrics and assess your models in a way that truly reflects their practical value. Remember, Python topic modeling isn’t about chasing perfect numbers. It’s about extracting valuable insights that inform decisions and drive action.
Visualizations That Tell Compelling Stories
So, you’ve built a killer topic model in Python. Awesome! But now you’re staring at a wall of numbers and word lists. Let me tell you, that’s not exactly boardroom-ready material. I’ve been there, done that, and gotten the blank stares to prove it. This section is your guide to transforming those raw insights into compelling visuals that even your non-technical colleagues will get—and even better, actually use.
pyLDAvis: Your Interactive Exploration Tool
First up is pyLDAvis. This Python library is a lifesaver for exploring topic models, particularly those created with LDA. I’ve used it on countless projects to get a handle on the topics, see how they relate, and pinpoint the most important terms for each. Think of it as a powerful magnifying glass for your model.

This screenshot gives you a glimpse of a standard pyLDAvis visualization. Each circle represents a topic, sized according to its prevalence in your data. The spacing between circles shows how similar (or different) the topics are. Over on the right, you’ll see the most relevant terms for the selected topic. What makes this so useful is its interactivity. Click on a topic, and boom—you immediately see its top words, making it super easy to understand the theme.
Matplotlib and Seaborn: Crafting Compelling Static Charts
While pyLDAvis is fantastic for exploration, you’ll often need static charts for reports and presentations. For this, I rely heavily on matplotlib and seaborn. I frequently use bar charts to show how topics are distributed across documents, or to highlight the most frequent terms within a topic. Seaborn’s heatmaps are also handy for visualizing the relationships between topics, offering a quick overview of the model’s structure. With a little tweaking, you can create polished, publication-ready visuals that clearly communicate the core insights.
Building Dashboards for Non-Technical Stakeholders
To really maximize the impact of your work, think about building interactive dashboards. Tools like Plotly Dash and Streamlit are game-changers. They let non-technical users explore the data on their own, filtering by topic, examining key terms, and even diving into individual documents. Giving stakeholders this kind of direct access to the model’s output significantly increases engagement and understanding. It’s about empowering them to discover patterns and insights for themselves.
Addressing Uncertainty and Avoiding Visualization Pitfalls
One crucial point to remember: topic models are all about probabilities, not certainties. Be upfront about this inherent uncertainty. I’ve found that using error bars or confidence intervals in my visualizations helps show the range of possible topic distributions. This prevents overinterpretation. Also, beware of some common traps: avoid cherry-picking topics just to support your narrative, and steer clear of visuals that mask the model’s limitations. Transparency builds trust.
Telling a Story with Your Visuals
Finally, consider the overarching story you’re telling. What are the most crucial takeaways? Which visualizations best convey those takeaways? In one project, I used a network graph to show the connections between topics in a model trained on social media data. This instantly revealed the main clusters of conversation and highlighted hidden relationships that I would’ve completely missed with a basic list of topics. By focusing on the narrative, you transform your visuals from pretty pictures into powerful tools for understanding, discussion, and decision-making.
Scaling And Deploying Production Models
Moving your Python topic modeling project from prototype to a live production environment is a big step. It’s not just about handling more data; it’s a whole different way of thinking about performance, reliability, and how easy it is to maintain. I’ve learned this the hard way – seemingly small issues can become huge headaches when you’re dealing with real-world data. Let’s dive into some of those scaling and deployment challenges.
Handling Large Text Corpora
One of the first roadblocks you’ll hit is the sheer size of real-world text. Training a model on a few thousand documents is a breeze compared to training it on millions. I remember working on a project analyzing customer feedback for a large e-commerce site. The data was massive, and my initial attempts to train a model locally failed miserably. My machine just couldn’t handle it. The answer? Distributed computing. Frameworks like Spark and Dask let you spread the work across many machines, making it possible to process huge datasets that would otherwise be impossible.
Optimizing Memory For Sustained Operation
Even with distributed computing, you still need to be smart about memory. Topic models, especially with big vocabularies, can be real memory hogs. One trick I use is working with generators and iterators. This keeps you from loading the entire dataset into memory at once; you process it piece by piece. Also, look at data structures built for sparse data, like the ones in the scipy.sparse library. This can drastically cut down on memory use and boost performance. On a related note, Python’s role in topic modeling is huge. Its flexibility in building AI insights is helping all sorts of industries. For instance, predictions show a rise of industry-specific data platforms by 2025, many likely leveraging Python for custom topic modeling. This will be big for fields like healthcare and finance, where detailed data analysis is key for strategic planning. Discover more insights about the data industry here.
Building Robust Topic Modeling Pipelines
A production-ready system needs more than just the trained model itself. You need a solid pipeline that takes care of everything: data ingestion, preprocessing, model training, and generating the final output. I suggest using tools like Airflow or Prefect to manage this workflow. These tools give you a way to define, schedule, and keep tabs on your pipeline, making sure each step runs smoothly and you can easily track progress and spot problems.
Online Learning and Real-Time Processing
Sometimes, you need to process documents as soon as they come in. This is where online learning comes in handy. Algorithms like Online LDA let you update your model bit by bit with new data without a full retraining. For true real-time work, think about using streaming platforms like Kafka or Kinesis for data intake and triggering model updates. This lets you analyze and respond to fresh information immediately.
Deployment Patterns and Computational Trade-Offs
The best way to deploy your model depends on what you need it to do. You could deploy it as a REST API, making it accessible to other applications. Or, you could integrate it directly into a bigger system. Keep in mind the computational costs. A complex model might give better results but need more resources. A simpler model might be faster and more efficient, even if it’s a little less accurate. Finding the right balance is important.
Maintaining Model Performance and Monitoring
Your data will evolve, and your model’s performance will likely change over time. Regular monitoring is absolutely crucial. Keep an eye on metrics like coherence and perplexity. If you see a big drop, it might be time to retrain your model or tweak your preprocessing steps. Setting up automated alerts can warn you of problems before they affect your users. By tackling these challenges head-on, you can transform your Python topic modeling projects from prototypes into production systems that consistently deliver valuable insights. It’s an ongoing process, not a one-time fix, but the right strategy will help you build systems that scale, adapt, and keep providing value as your data grows.
Explore how DATA-NIZANT can empower your data-driven journey by visiting them today.





