
Learning to Rank Explained: Algorithms Behind Search, Recommendations, and Relevance Ranking: Learning to Rank: Transform Your Search Results Instantly
Why Learning To Rank Is Revolutionizing Search

For decades, search engines relied on simpler methods to rank results. These often involved manually adjusted rules and algorithms. While these methods worked, they struggled with the complexities of human language and user intent. This often led to imprecise search results. Users had to sort through many irrelevant pages to find what they needed. This is where learning to rank (LTR) changes everything.
It represents a major shift in how search engines work. LTR uses machine learning to create ranking models that learn and adapt. This results in much more accurate and personalized search results. Users find information faster and more easily. Check out our guide on big data search.
From Hand-Tuned Rules to Machine Learning Mastery
Traditional ranking methods typically focus on matching keywords in a document to the search query. This approach often fails with complex or ambiguous searches. For example, searching for “jaguar” could refer to the animal or the car. The search engine needs to figure out what the user means. The same keywords can also appear in very different contexts.
LTR solves these problems using machine learning algorithms. These algorithms learn complex relationships between searches and documents. This lets LTR models go beyond basic keyword matching. They understand the meaning and context of the search and the content itself. Learn more about learning to rank here.
The Power of Personalization and User Feedback
LTR algorithms can personalize search results. They do this based on individual user preferences and past searches. This means two users searching for the same thing can get different, more relevant results. LTR systems also constantly improve by using user feedback. For instance, if users often click the third result for a specific search, the LTR algorithm learns this. It then adjusts its ranking to show that result higher. This constant feedback makes LTR models more accurate over time.
Why Tech Giants Are Investing Millions
Learning to rank is incredibly effective. Companies like Google, Microsoft, and Amazon invest heavily in LTR research and development. They spend millions of dollars improving their systems. This investment is driven by the real benefits LTR provides:
- Improved Search Accuracy: LTR models consistently deliver better search results than older methods.
- Enhanced User Experience: LTR makes searching faster and easier with accurate and personalized results.
- Increased User Engagement: Users interact more with relevant search results, leading to higher click-through rates and longer website visits.
- Higher Revenue Generation: For online stores, better product recommendations directly increase sales and revenue.
The shift toward LTR shows its power to change search. As LTR technology improves, expect even bigger advancements in search accuracy, personalization, and user experience. You might be interested in: How to master machine learning infrastructure.
The Three Powerhouse Approaches That Drive Rankings
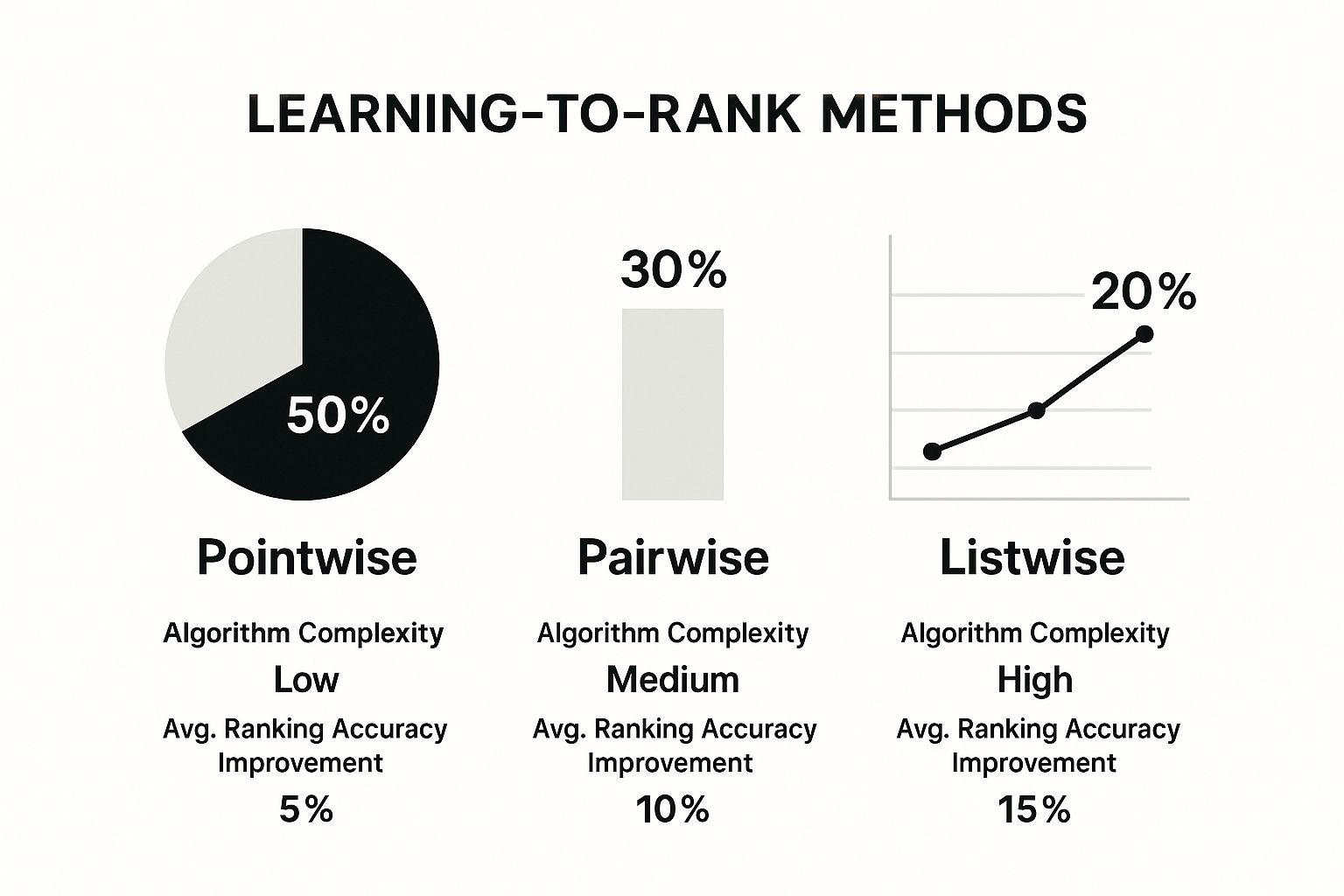
The infographic above illustrates the usage, complexity, and accuracy improvements associated with three primary learning to rank (LTR) methods: pointwise, pairwise, and listwise. The data reveals an interesting trend: while pointwise methods are more prevalent and simpler in research, listwise approaches offer the most substantial accuracy gains. This underscores the inherent trade-off between complexity and performance in LTR algorithms.
Understanding these different LTR methods is essential for anyone building or optimizing search systems. Let’s delve into the three fundamental approaches powering modern ranking algorithms.
Pointwise Methods: Treating Documents Individually
Pointwise methods simplify the ranking problem, treating it like a standard regression or classification task. Each document is analyzed independently, receiving a relevance score based on its features. This score predicts the document’s relevance to a specific query, regardless of other documents. Think of it like evaluating singers in a competition, where each performance is judged in isolation.
- Benefits: Simpler implementation and lower computational costs compared to other methods.
- Drawbacks: Doesn’t consider the relative order of documents, a critical aspect of ranking. This can lead to less effective results when the ranking order is paramount.
Pairwise Methods: Comparing Document Pairs
Pairwise methods introduce the concept of comparison. They analyze pairs of documents, aiming to predict which document is more relevant to a given query. This approach resembles judging a debate, where the emphasis is on the relative strength of arguments.
- Benefits: Accounts for the relative relevance of documents, leading to better ranking accuracy than pointwise methods.
- Drawbacks: Can be computationally more demanding, especially with large datasets. Optimizing for pairwise comparisons may not always optimize the entire ranked list.
Listwise Methods: Optimizing the Entire Ranking List
Listwise methods address the ranking problem directly by evaluating the entire list of documents as a whole. They optimize for ranking metrics like NDCG (Normalized Discounted Cumulative Gain), striving to create the optimal ranked list for each query. This is like arranging a group photo, considering everyone’s position relative to each other for the best overall composition. Pointwise methods see the task as a regression or classification problem on individual query-document pairs, predicting relevance scores. Pairwise methods focus on comparing document pairs to learn their order, while listwise methods analyze all documents simultaneously. Explore this topic further.
- Benefits: Directly optimizes ranking metrics, often producing the most accurate rankings.
- Drawbacks: The most complex and computationally intensive, requiring significant resources for training and implementation.
To illustrate the key differences between these approaches, consider the following table:
Learning to Rank Approaches Comparison
A comprehensive comparison of pointwise, pairwise, and listwise approaches including their methodologies, advantages, disadvantages, and best use cases.
| Approach | Methodology | Advantages | Disadvantages | Best Use Cases |
|---|---|---|---|---|
| Pointwise | Treats each document independently, assigning a relevance score. | Simple to implement, computationally efficient. | Ignores relative order of documents. | Initial ranking models, large datasets where efficiency is crucial. |
| Pairwise | Compares pairs of documents to determine relative relevance. | Captures relative order, improves accuracy over pointwise. | More computationally expensive than pointwise, may not optimize the entire list. | Medium-sized datasets, when relative order is important. |
| Listwise | Optimizes the entire ranked list simultaneously. | Directly optimizes ranking metrics, often yields the most accurate results. | Most complex and computationally intensive. | Smaller datasets, when high accuracy is paramount. |
The table summarizes the core differences and trade-offs associated with each LTR method. The choice depends heavily on the specific needs of your search system.
The selection of the appropriate LTR method depends on various factors, including dataset size, computational resources, and the desired level of accuracy. While pointwise methods offer simplicity, listwise methods pursue the highest accuracy, reflecting the ongoing advancements in search technology. Choosing the right approach is key to enhancing user experience and achieving optimal search results.
Why Listwise Methods Are Dominating the Field
The way we optimize search results has changed dramatically thanks to advancements in learning to rank. While earlier methods like pointwise and pairwise approaches were important stepping stones, listwise methods have taken the lead. The key difference lies in how they tackle the ranking problem. Listwise methods look at the entire list of search results all at once.
This allows for a global optimization strategy, leading to much more relevant searches.
Directly Optimizing Ranking Metrics
This global view lets listwise methods directly optimize for important ranking metrics. These include metrics like nDCG and MAP. These metrics consider both the position and relevance of each document in the list. For instance, nDCG gives priority to highly relevant documents that appear higher up in the results.
By focusing on these metrics during training, listwise algorithms ensure their objectives align with delivering better search quality. This direct connection translates to more relevant results for users and a better overall search experience. For those interested in diving deeper into the world of neural networks, check out this resource: How to master neural networks.
Research backs up the effectiveness of listwise methods. A major experiment analyzed by Tie-Yan Liu at Microsoft Research Asia showed that listwise methods consistently beat pairwise and pointwise approaches on standard datasets. This advantage comes from the ability to directly optimize metrics like nDCG, which more accurately reflect overall ranking goals. To learn more about this exciting field, explore this resource on learning to rank.
From Scores to Global Optimization
Moving from scoring individual documents to optimizing entire lists is a significant leap forward in information retrieval. Older pointwise methods focused on predicting individual document scores. Pairwise methods, while an improvement, only compared pairs of documents.
Listwise methods, on the other hand, analyze the entire list. This allows them to capture the complex relationships between documents and their positions within the list.
The Breakthrough in Information Retrieval
This holistic approach allows for a more nuanced understanding of what users are searching for. It also improves how search results are presented. By treating the entire result list as one unit, listwise methods can fine-tune the order and presentation of information. The result? Maximum user satisfaction and search effectiveness.
This has revolutionized information retrieval, pushing the boundaries of what search engines can do. The constant drive to improve user experience continues to fuel research and development of even more advanced ranking algorithms.
How Industry Giants Transformed Search With Learning to Rank

When we look at companies handling billions of searches daily, the real impact of learning to rank (LTR) becomes evident. Industry leaders like Microsoft Bing and Alibaba have used LTR algorithms to significantly improve their search capabilities, resulting in substantial increases in user satisfaction. LTR algorithms have become a key component of online search and recommendation systems, particularly in large markets like the United States, Europe, and Asia.
Both Microsoft Bing and Alibaba utilize LTR to refine search relevance for millions of queries every day. Want deeper insights into the research behind LTR? Check out this resource: Learning to Rank Research.
Microsoft Bing: Enhancing Search Relevance at Scale
Microsoft Bing faced the considerable task of improving search relevance across a massive user base. By implementing learning to rank, they personalized results and gained a better understanding of user intent. This focus on user experience led to significant improvements in key performance metrics, including higher click-through rates and increased user engagement.
Alibaba: Powering E-Commerce Search
E-commerce giant Alibaba uses learning to rank to drive its product search and recommendation engines. This is a critical component for enhancing user experience and, ultimately, boosting sales. With LTR, Alibaba has witnessed a substantial rise in both user engagement and conversion rates. This underscores the significant business value of effective search, directly influencing their bottom line.
Overcoming Challenges at Scale
Implementing learning to rank on the scale of Bing and Alibaba presents a unique set of challenges:
- Handling Massive Datasets: Training effective LTR models requires the efficient processing of huge amounts of data.
- Meeting Strict Latency Requirements: Search results need to be delivered incredibly fast to maintain a seamless and positive user experience.
- Maintaining Accuracy: Model accuracy is paramount for ensuring truly relevant search results.
To tackle these challenges, these companies have developed innovative solutions, using advanced machine learning infrastructure and optimized algorithms to manage the immense data volume and stringent latency requirements. These advancements guarantee users receive accurate and prompt results.
Inspiring Transformations Across Industries
The successes of Bing and Alibaba with learning to rank have inspired similar adoptions across various industries. This includes e-commerce platforms, content recommendation systems, and even digital advertising. As LTR algorithms continue to evolve, they are steadily improving user experiences across a multitude of online platforms.
The knowledge gained from scaling these systems contributes to the development of more robust and efficient machine learning methods, shaping the future of how we interact with information online. The influence of LTR extends to other fields like personalized medicine and fraud detection, where prioritizing data points is crucial.
The Future of Learning to Rank
The advancement of learning to rank is showing no signs of slowing down. Ongoing research is currently exploring key areas such as:
- Real-Time Learning: Adapting rankings in real-time based on live user interactions and feedback.
- Deep Learning Integration: Leveraging the power of deep neural networks to create more sophisticated and nuanced ranking models.
- Explainable AI: Increasing the transparency of LTR algorithms by making their decision-making processes more understandable.
These developments hold the promise of making learning to rank even more effective, further transforming how we discover information and engage with online platforms.
Measuring Success: The Metrics That Actually Matter
Picking the right metrics is crucial for evaluating how well a learning to rank system performs. These metrics offer quantifiable data that shows how the system is doing and where it could be better. While standard metrics like nDCG (Normalized Discounted Cumulative Gain) and MAP (Mean Average Precision) are a good starting point, they don’t always tell the whole story of user satisfaction.
Traditional Metrics: A Foundation for Evaluation
nDCG takes into account both the position and relevance of each document in the results, giving higher scores to relevant documents that appear higher up. MAP also considers the average precision at different recall levels. These widely used metrics form a solid base for assessing ranking quality.
However, these traditional metrics primarily focus on relevance based on pre-defined labels. They often miss the subtle nuances of user behavior, like how engaged a user actually is with the results.
User Engagement Metrics: Reflecting Real-World Performance
User engagement metrics have become increasingly important in evaluating learning to rank models. Metrics like click-through rate (CTR), dwell time, and conversion rate offer valuable insights into actual user interactions. For instance, a high CTR for top-ranked results suggests that the system is doing a good job of showing users what they want.
But even user engagement metrics require careful interpretation. Position bias, the tendency for users to click on higher-ranked results regardless of relevance, can skew CTR. Strategies are needed to account for this bias and accurately measure the real impact of the ranking algorithm. This includes analyzing factors like where clicks happen on the page and the overall distribution of clicks.
The Power of Benchmarking and A/B Testing
Benchmarking against established standards gives another helpful view of your system’s performance. This lets you see how your system compares to other solutions and pinpoint areas with potential for significant gains. A/B testing, where different ranking algorithms are compared head-to-head, helps determine which algorithm is better in real-world scenarios.
These algorithms often handle huge amounts of data. Bing, for example, reportedly uses billions of web pages to constantly refine its ranking models. Learning to rank systems have shown significant improvements in performance metrics. In one benchmark, listwise learning to rank algorithms improved nDCG scores by 10-15% over traditional pairwise methods, leading to noticeably better results for users. You can find more statistics in this Learning to Rank Research paper.
Choosing the Right Metrics for Your Goals
The best metrics to use depend heavily on your learning to rank system’s goals. For e-commerce platforms, conversion rate is key, directly reflecting the impact of ranking on sales. For general search engines, a combination of metrics like nDCG, CTR, and dwell time provides a more complete view of user satisfaction.
The following table summarizes common learning to rank performance metrics, their typical ranges of improvement, and their impact on business outcomes.
Learning to Rank Performance Metrics
| Metric | Description | Typical Improvement Range | Business Impact | Best For |
|---|---|---|---|---|
| nDCG | Measures the quality of the ranked list, considering relevance and position. | 5-15% | Improved search relevance. | General search engines, content platforms. |
| MAP | Measures the average precision across different recall levels. | 2-10% | Enhanced information retrieval. | Search engines, academic search. |
| CTR | Percentage of users who click on a result. | 1-5% | Increased user engagement. | All search systems, advertising. |
| Dwell Time | How long users spend on a page after clicking a result. | 5-20% | Better user experience, increased content consumption. | Content platforms, news sites. |
| Conversion Rate | Percentage of users who complete a desired action (e.g., purchase). | 1-10% | Higher sales, increased revenue. | E-commerce, lead generation. |
Using a combination of these metrics offers a more complete understanding of your system’s performance, its impact on users, and how it affects your business objectives. As machine learning models continue to advance, constantly evaluating and refining ranking metrics is vital for improving search technology.
Building Adaptive Rankings With Online Learning
The future of learning to rank (LTR) hinges on real-time adaptation. This differs greatly from traditional offline models, trained on static datasets and periodically updated. Online learning, on the other hand, constantly refines the ranking model based on live user interactions.
This allows the system to instantly adapt to changing user behavior and preferences. For instance, if a product suddenly becomes popular, an online LTR system can quickly adjust its rankings. This ensures users see the most relevant results, reflecting the shift in demand. This responsiveness demands a closer look at the technical innovations enabling real-time learning at scale.
Balancing Computational Demands and Responsiveness
Online learning faces a key challenge: balancing immediate responsiveness with the computational needs of LTR algorithms. The potential number of rankings increases exponentially with the number of items, causing a computational bottleneck. This issue is particularly noticeable in large-scale applications like e-commerce, where millions of products require ranking.
Fortunately, solutions are emerging. Efficient algorithms and distributed computing architectures are helping to overcome this challenge. These advancements in algorithmic design maintain accuracy even at massive scale. This means online LTR systems deliver relevant results without sacrificing speed.
The Power of Real-Time User Feedback
Online LTR systems use continuous user interaction data, such as clicks, dwell time, and conversions. This allows them to understand user behavior nuances that traditional metrics might miss. For example, if users consistently ignore the top search result, the system can infer that the result isn’t as relevant as predicted.
This instant feedback loop fuels continuous improvement. It ensures the ranking model remains in sync with user needs. Moreover, online LTR systems excel at personalization. By tracking user preferences and interaction history, the system tailors results to each user, leading to a more satisfying experience.
Algorithms for Real-Time Learning at Scale
Several algorithms are driving real-time learning to rank at scale. They are designed to efficiently update the ranking model with each new interaction without needing a full retraining.
- Multi-Armed Bandit Algorithms: These algorithms explore various ranking options while simultaneously applying knowledge from past user interactions. This makes them very effective in scenarios with constantly evolving preferences.
- Online Gradient Descent: This method efficiently updates model parameters based on the gradients of the ranking loss function. It enables incremental learning with each new piece of data.
- Factorization Machines: These models handle large, sparse datasets efficiently. This makes them well-suited for applications like e-commerce recommendations where user-item interactions are limited.
Transforming Industries With Adaptive Ranking
Adaptive ranking is changing how we interact with information across many industries. In e-commerce, online learning improves product recommendations, boosting conversion rates and sales. For content discovery platforms, it personalizes content feeds, showing users articles and videos they find interesting. Adaptive ranking also enhances personalized search within applications, making search more intuitive and helpful. These advancements collectively create a more seamless and personalized online experience. You might be interested in: How to master machine learning infrastructure.
The focus in learning to rank has shifted towards adaptation and personalization. Online learning methods, combined with innovative algorithms, are unlocking the true potential of LTR. They’re creating more relevant and dynamic search results for various online applications.