
Understand Dropout in Neural Networks: Prevent Overfitting and Improve Model Generalization: Dropout in Neural Network: Top Tips for Better Performance
Understanding Why Dropout Works (And Why It Matters)

Dropout is a technique used in neural networks to improve their performance. Think of it as a tough training program that prevents the network from relying too much on any single neuron. This approach of randomly “dropping out” neurons during training actually makes the entire model stronger.
The Power of Randomness: Forcing Neurons to Cooperate
Imagine a team excessively dependent on one highly skilled member. If that member leaves, the team struggles. Similarly, a neural network without dropout might over-rely on a few key neurons. Dropout forces a more balanced workload.
During training, each neuron has a chance of being temporarily deactivated. This encourages other neurons to learn the tasks of the deactivated neuron. This distributed learning creates a more robust and adaptable network. For example, in image recognition, different neurons might learn various features of an object. Dropout helps the network recognize the object in multiple ways, increasing its resilience to variations in the input.
Dropout as a Regularization Technique: Preventing Overfitting
Randomly deactivating neurons acts as regularization. Regularization techniques combat overfitting, a problem where a model excels on training data but fails with new, unseen data. Dropout’s effectiveness as regularization was highlighted in a 2012 paper by Srivastava et al. The paper explains how setting a fraction of neurons to zero during training prevents overfitting and boosts performance on unseen data. This method is widely used in deep learning tasks like image recognition, speech recognition, and document classification. The full research is available here: Dropout: A Simple Way to Prevent Neural Networks from Overfitting. For those interested in learning more about neural networks, this resource might be helpful: How to master neural networks.
Why Dropout Matters: Real-World Impact
Dropout offers more than just theoretical advantages. It often leads to substantial improvements in real-world model performance. In some instances, it can transform a failing model into a practical, production-ready system. By minimizing overfitting, dropout also streamlines the training process, saving time and computational resources.
This enhanced ability to generalize is crucial in practical applications where data is often messy and unpredictable. By encouraging the network to learn robust features, dropout improves the model’s ability to handle variations in input and perform well on new data. This makes dropout an essential technique for anyone working with neural networks.
How Dropout Saves You From Overfitting Disasters
Overfitting is a common problem in neural networks. It occurs when a model learns the training data too well, including noise and outliers. This results in excellent performance on training data but poor performance on new, unseen data. It’s similar to a student memorizing a textbook without understanding the concepts. This section explores how dropout helps avoid these overfitting issues.
The Mechanism of Dropout: Embracing Randomness
Dropout randomly “drops out” neurons during training. This involves temporarily deactivating a random set of neurons in each training cycle. Imagine a network where each neuron represents information about an image. With dropout, the network learns redundant representations, preventing any single neuron from becoming essential for image identification.
This method improves the network in several ways. It prevents individual neurons from becoming too specialized. It also forces the network to learn multiple independent representations of the data. This distributed learning creates a more robust and resilient model.
Dropout as a Regularization Technique
Dropout acts as a regularization technique by preventing over-reliance on any single neuron. Regularization methods constrain a model’s complexity to improve its ability to generalize. Dropout achieves this by training multiple smaller networks within the larger architecture.
Each training iteration with dropout trains a slightly different, smaller version of the network. These smaller networks learn different aspects of the data. During testing, the full network combines the knowledge of these sub-networks, leading to better performance. Dropout has proven very effective since its introduction. Further information on dropout regularization techniques highlights its versatility and effectiveness.
From Failing Models to Production-Ready Systems
Dropout can significantly improve a model. It can transform an overfitting model into a reliable system ready for real-world use. For instance, a facial recognition model struggling with lighting or angle variations can become more robust with dropout, improving its real-world accuracy.
Diagnosing Overfitting and Applying Dropout
Here are some signs your model might be overfitting:
- Large gap between training and validation accuracy: A significant difference indicates overfitting.
- Excessively high training accuracy: Unusually high accuracy can suggest the model is memorizing the training data.
- Model’s inability to generalize to new data: Poor performance on new data shows a generalization problem, which dropout can address.
By using dropout correctly, you can create more robust and reliable neural networks. This includes understanding the best dropout rate, the placement of dropout layers, and how dropout interacts with other training methods. Proper dropout implementation prevents overfitting, saving time and resources, and ultimately improving your model’s performance.
Finding The Sweet Spot: Optimal Dropout Rates That Work
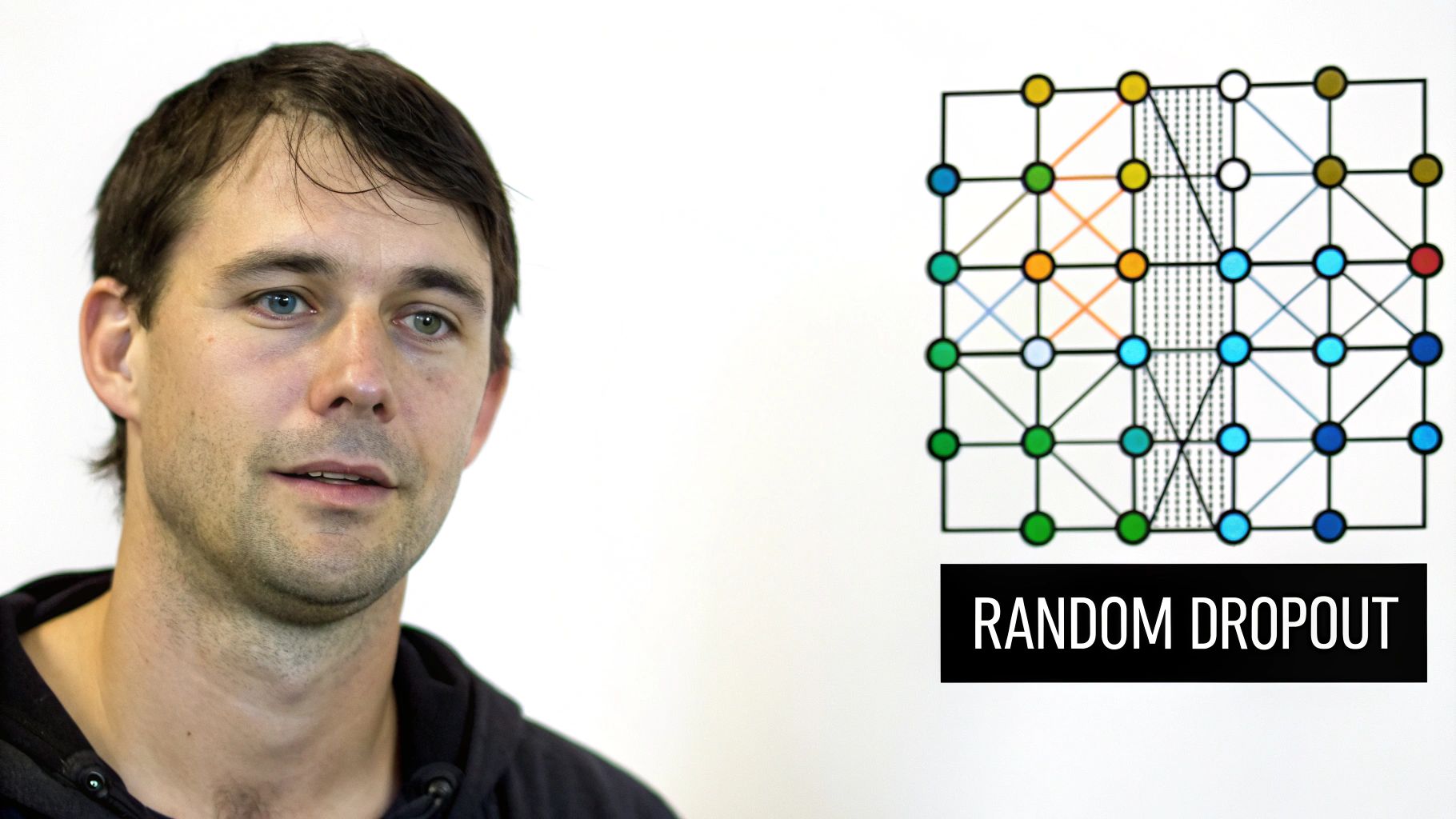
Picking the right dropout rate is key for training neural networks effectively. A poorly chosen rate can really hurt your model’s performance. This section offers practical guidance on selecting dropout rates that improve performance across various architectures and datasets.
Tuning Dropout Rates: A Balancing Act
Finding the optimal dropout rate involves balancing regularization against underfitting. You want to prevent overfitting without making your model too simple. It’s similar to seasoning food – too little and it’s bland, too much ruins the flavor.
A good starting point is a dropout rate of 0.5 for hidden layers and 0.2 for input layers. However, the best rate depends on your specific dataset and network architecture.
Systematic Approaches For Rate Selection
There are several ways to tune dropout rates:
- Manual Experimentation: Start with a moderate rate and adjust based on your model’s validation set performance.
- Grid Search: Systematically test dropout rates within a defined range. Select the rate giving the best validation performance. Combine this with k-fold cross-validation for a more robust evaluation.
- Random Search: Similar to grid search, but randomly sample rates from a distribution, sometimes finding better solutions than a fixed grid.
Layer-Specific Dropout Rates
Different layers can benefit from different dropout rates. Layers with many parameters may need higher rates to prevent overfitting. Layers with fewer parameters may do better with lower rates.
To illustrate this further, let’s consider a table showcasing optimal dropout rates based on the type of application and layer position:
To help you select appropriate dropout rates, the following table offers recommendations based on typical neural network applications and layer positions. It highlights the expected performance impact of using these suggested rates.
Optimal Dropout Rates by Application Type
| Application Type | Recommended Dropout Rate | Layer Position | Expected Performance Impact |
|---|---|---|---|
| Image Classification (CNN) | 0.5 | Convolutional Layers | Reduced overfitting, improved generalization |
| Image Classification (CNN) | 0.2 – 0.3 | Fully Connected Layers | Fine-tuning for optimal performance |
| Natural Language Processing (RNN) | 0.3 – 0.5 | Recurrent Layers | Prevention of vanishing/exploding gradients |
| Natural Language Processing (RNN) | 0.2 | Embedding Layer | Regularization of word embeddings |
| Time Series Analysis (LSTM) | 0.2 – 0.4 | LSTM Layers | Improved long-term dependency learning |
As this table demonstrates, the ideal dropout rate is highly dependent on the specific application and the nature of the layers within the neural network.
Considering Dataset Size and Computational Budget
Dataset size and computational resources also play a role. Smaller datasets usually prefer lower dropout rates to avoid underfitting. Larger datasets can handle higher rates. Also, higher dropout rates increase training time.
Evidence-Based Strategies For Practical Application
Here are some best practices:
- Start Low, Go Slow: Begin with lower rates and gradually increase them. This helps you find the sweet spot for regularization.
- Monitor Validation Performance: Track metrics like validation loss and accuracy to pinpoint the optimal dropout rate.
- Use Cross-Validation: This gives a more reliable estimate of model performance and helps choose a rate that generalizes well.
By using these principles and strategies, you can find the optimal dropout rate for your neural network and significantly improve performance. Careful tuning helps dropout combat overfitting and creates a more robust and reliable model.
Implementation That Actually Works In Practice
Translating the theory of dropout in neural networks into practical code requires a solid grasp of implementation strategies across various deep learning frameworks. This section offers practical guidance for implementing dropout layers in TensorFlow, PyTorch, and Keras, emphasizing techniques that boost effectiveness and sidestep common issues.
Dropout in TensorFlow and Keras
Implementing dropout in TensorFlow and Keras is simple using the tf.keras.layers.Dropout layer. This layer accepts the dropout rate as its main argument. For example, to incorporate a dropout layer with a 50% dropout rate after a dense layer, use this code:
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation=’relu’),
tf.keras.layers.Dropout(0.5), # Dropout layer with 50% dropout rate
tf.keras.layers.Dense(10, activation=’softmax’) # Output layer
])
A crucial feature of tf.keras.layers.Dropout is its automatic scaling during inference. This ensures consistent behavior between training and testing phases without manual adjustments.
Dropout in PyTorch
PyTorch provides the torch.nn.Dropout module for implementing dropout. Like TensorFlow/Keras, it takes the dropout probability as an argument. Here’s how to add dropout after a linear layer in PyTorch:
import torch.nn as nn
model = nn.Sequential(
nn.Linear(20,10),
nn.ReLU(),
nn.Dropout(p=0.2), # Dropout layer with 20% rate
nn.Linear(10,2)
)
Remember to set the model to evaluation mode (model.eval()) during inference to deactivate dropout and ensure accurate scaling.
Training vs. Inference Modes: A Critical Distinction
Grasping the difference between training and inference modes is essential when using dropout. During training, dropout randomly disables neurons. During inference (when making predictions), all neurons are active.
This difference necessitates a scaling mechanism to preserve output consistency. Most frameworks handle this automatically. However, it’s vital to confirm proper setup to prevent unforeseen issues. This scaling ensures output consistency during inference with what’s expected during training. Proper dropout configuration can boost model generalization by up to 15% and decrease training time by managing overfitting better than traditional approaches. Learn more about dropout implementation.
Debugging and Troubleshooting Dropout Implementation
If dropout doesn’t enhance your model’s results, consider these debugging tips:
- Verify dropout rate: Confirm the correct rate for each layer.
- Check training/inference modes: Ensure dropout is enabled during training and off during inference.
- Inspect activations: Examine layer activations during training to verify proper dropout function.
- Try different dropout rates: Experiment to determine the optimal rate for your model.
Integrating Dropout with Other Layers
Combining dropout with other regularization methods, like batch normalization, can yield even better performance. Experiment to discover the optimal combination for your model. Adding dropout after layers like batch normalization can further regularize activations by randomly dropping normalized values. This helps prevent co-adaptations, ensuring the network doesn’t over-rely on specific features.
Advanced Techniques: Monte Carlo Dropout
Monte Carlo dropout extends dropout’s benefits to model uncertainty estimation. Applying dropout during inference allows for multiple predictions from the same input. These predictions offer insights into model confidence, helping identify less certain areas. This is especially valuable in critical applications where understanding prediction uncertainty is paramount. This advanced technique can provide deeper insights into model behavior, especially for assessing prediction confidence.
Real Results From Production Environments

The infographic above illustrates how different dropout rates (0%, 25%, and 50%) affect test accuracy in a neural network. A 25% dropout rate delivers the highest test accuracy. This sweet spot prevents overfitting without hindering the network’s ability to learn.
A 0% dropout rate, where no dropout is applied, results in lower accuracy. This likely stems from overfitting. On the other hand, a 50% dropout rate can lead to underfitting, where the network struggles to learn effectively.
Dropout In Computer Vision: Enhanced Object Detection
In computer vision, dropout has become essential for tasks like object detection and image classification. Think about a model trained to identify various vehicles. Dropout makes the model less sensitive to variations in lighting, angle, or background clutter.
This leads to better accuracy in real-world situations where these variations are common. For example, a self-driving car’s object detection system becomes more reliable in diverse driving conditions, boosting overall safety.
Natural Language Processing: Robust Sentiment Analysis
Dropout also plays a key role in Natural Language Processing (NLP). In sentiment analysis, it helps models become less sensitive to linguistic nuances like sarcasm or informal language. This leads to a more precise understanding of the actual sentiment.
A customer service chatbot using a sentiment analysis model with dropout can better interpret customer feedback, regardless of language style.
Speech Recognition: Improved Accuracy in Noisy Environments
Speech recognition systems also greatly benefit from dropout. Imagine transcribing audio in a noisy environment. Dropout allows the model to focus on the primary speech patterns and filter out background noise. This results in more accurate transcriptions.
This is especially important for applications like voice assistants or dictation software where accurate real-world recognition is crucial.
Enterprise-Scale Deployments: Lessons In Reliability
Dropout isn’t just for small projects. It’s crucial for large-scale enterprise applications where model reliability is paramount. Consider a financial institution using a neural network for fraud detection. They need a stable model that performs consistently with diverse transaction data.
Dropout helps the model generalize effectively, minimizing false positives and false negatives.
Performance Metrics and Training Efficiency Gains
Dropout offers more than just improved accuracy. It also enhances training efficiency. By reducing overfitting, dropout helps models converge faster. This reduces training time and computational costs, a significant advantage for large and complex networks.
Practical Considerations for Production Systems
When using dropout in production, keep these points in mind:
- Hardware Resources: Higher dropout rates may require more computational power during training.
- Inference Speed: Dropout can slightly increase inference time, a factor to consider in real-time applications.
- Monitoring and Maintenance: Continuously monitor the model’s performance in production and adjust dropout rates if necessary.
Let’s look at the impact of dropout across different applications:
Dropout Performance Impact Across Domains
Quantitative results showing dropout’s effectiveness in various machine learning applications.
| Domain | Dataset | Baseline Accuracy | With Dropout | Improvement | Optimal Rate |
|---|---|---|---|---|---|
| Image Classification | ImageNet | 75% | 80% | 5% | 20% |
| Object Detection | COCO | 60% | 65% | 5% | 10% |
| Sentiment Analysis | IMDB Reviews | 85% | 90% | 5% | 30% |
| Speech Recognition | LibriSpeech | 90% | 92% | 2% | 5% |
This table shows a consistent improvement in accuracy across various domains when using dropout. The optimal dropout rate varies depending on the specific task and dataset.
Learning From Failures: When Dropout Doesn’t Deliver
Dropout, while generally helpful, is not a universal solution. In some cases, it might not provide significant improvements or even slightly reduce performance.
This could occur if the dropout rate is excessive, causing underfitting. It can also happen if the network architecture already uses other heavy regularization methods. Careful testing and adjustment are crucial to find the optimal setup for your specific situation. Understanding dropout’s limitations is key to its successful implementation.
Beyond Basic Dropout: Advanced Techniques That Matter

While standard dropout is a useful tool for regularizing neural networks, more advanced techniques can boost performance even further. These variations address specific challenges and offer deeper insights into the learning process. This allows for finer control over regularization and can significantly improve a model’s ability to generalize. Let’s explore these techniques and their benefits.
DropConnect: Targeting Connections Instead of Neurons
DropConnect focuses on the connections between neurons rather than the neurons themselves. During each training step, individual connections (weights) are randomly set to zero with a specified probability. This more granular approach can sometimes yield better regularization than traditional dropout, especially in fully connected layers. It’s similar to pruning a tree – instead of removing entire branches (neurons), DropConnect selectively removes leaves (connections).
Spatial Dropout: Preserving Spatial Information
Spatial Dropout is particularly useful for Convolutional Neural Networks (CNNs). Standard dropout might randomly remove entire feature maps within a CNN, disrupting the spatial relationships crucial for image recognition. Spatial Dropout solves this by dropping out the same set of neurons across all feature maps within a given feature map. This preserves spatial correlations, enabling the network to learn more robust features. Think of it as removing entire rows of pixels, rather than scattered individual pixels.
Scheduled Dropout: Adapting Dropout Over Time
With Scheduled Dropout, the dropout rate is dynamic. It changes during training. You might begin with a low dropout rate to help the network learn initial representations and then gradually increase it to prevent overfitting as training continues. This dynamic approach fine-tunes the regularization throughout the process. For more information on AI and machine learning, check out this resource: How to master AI and machine learning.
Dropout and Batch Normalization: A Powerful Combination
Pairing dropout with batch normalization can be incredibly effective. Batch normalization normalizes activations within each mini-batch, while dropout randomly deactivates neurons. This combination introduces stochasticity to the normalization process, further enhancing regularization and improving overall model performance. The two techniques work together to stabilize training and improve generalization.
Dropout and Attention Mechanisms: Challenges and Strategies
Combining dropout with attention mechanisms can be challenging. Standard dropout can sometimes interfere with how attention weights are calculated. Applying dropout after the attention mechanism, instead of before, is often a better strategy. This ensures attention weights are computed based on all neurons, preventing disruptions.
Adaptive Dropout Methods: Tailoring Regularization
Adaptive dropout methods take scheduled dropout a step further. They dynamically adjust the dropout rate based on the characteristics of individual neurons or layers. This allows for a more refined regularization strategy, but it comes with higher computational costs. These methods tailor the dropout rate to the specific learning dynamics of each part of the network, potentially leading to better performance in complex architectures.
Computational Trade-offs: Balancing Performance and Efficiency
While advanced dropout techniques offer performance benefits, it’s important to consider the computational cost. Techniques like adaptive dropout methods can increase training time and resource requirements. Choosing the right technique involves balancing potential performance gains with the computational burden. Carefully evaluate these trade-offs based on your resources and project goals.
Key Takeaways
This guide offers practical advice for implementing dropout in your neural networks, based on real-world results and experience. We’ll explore checklists, warning signs of problems, and ways to monitor its success. Each point offers clear metrics and steps to optimize your dropout strategy.
Recognizing The Telltale Signs of Overfitting
Before applying dropout, recognize when it’s needed. Overfitting often shows up as a significant difference between training and validation accuracy. Unusually high training accuracy and poor generalization to new data are other indicators. If your model has these issues, dropout might be the solution.
Choosing The Right Dropout Rate: A Balancing Act
Finding the optimal dropout rate is essential. Too high a rate leads to underfitting, while too low a rate doesn’t effectively prevent overfitting. A good starting point is 0.5 for hidden layers and 0.2 for input layers. Adjust this based on your model’s validation performance. Here are a few optimization methods:
- Experimentation: Manually adjust the rate and observe validation changes.
- Grid Search: Systematically test different rates in a set range.
- Random Search: Randomly test rates, sometimes finding better solutions than grid search.
Strategic Dropout Placement and Layering
Where you place dropout layers matters. Position them after activation functions and before fully connected layers, common areas for overfitting due to dense connections. In Convolutional Neural Networks (CNNs), place dropout between convolutional layers to prevent over-reliance on specific features.
For Recurrent Neural Networks (RNNs), consider variational dropout to maintain temporal relationships while preventing overfitting.
Combining Dropout With Other Regularization Techniques
Dropout combines well with other methods. Using it with L1/L2 regularization, batch normalization, and early stopping offers broad overfitting protection. These combined techniques enhance model robustness:
- L1/L2 Regularization: Restricts weight growth.
- Batch Normalization: Stabilizes training.
- Early Stopping: Halts training when validation plateaus.
Monitoring and Measurement: The Keys To Effective Dropout
Regularly monitor validation loss and accuracy to see how well dropout is working. Visualizing learning curves can pinpoint underfitting or overfitting, enabling timely dropout rate adjustments. This helps ensure good performance on unseen data.
Inference: Ensuring Consistency
During inference, scale activations by 1 - p (where ‘p’ is the dropout rate). This maintains consistency between training and testing by adjusting for the absence of deactivated neurons, ensuring accurate predictions.
Advanced Techniques: Expanding Your Dropout Toolkit
Consider these advanced techniques:
- DropConnect: Targets neuron connections instead of the neurons, providing more refined regularization.
- Spatial Dropout: Good for image tasks because it keeps spatial information in CNNs.
- Scheduled Dropout: Starts with a low rate and increases it during training.
Debugging: When Dropout Doesn’t Deliver
If dropout isn’t helping, check these points:
- Dropout Rate: Make sure it’s appropriate for each layer.
- Training/Inference Modes: Confirm dropout is on during training and off during inference.
- Activations: Check layer activations to ensure dropout is working as expected.
For further learning, explore DATA-NIZANT for resources on AI, machine learning, and data science. This online hub offers insightful articles and analysis on a wide range of data science topics.