
Exploring the Battle Between Cost, Compute, and Market Dominance: The AI Token Pricing War: Who Will Reign Supreme?
The TSMC Crucible: A Universal Forge
Deep in Taiwan’s tech nebula, TSMC’s glowing forges churn out chips that power the AI cosmos. Nvidia’s H100s—$30K juggernauts—fuel OpenAI’s GPT-4, Google DeepMind’s AlphaFold, and DeepSeek’s R1. Grok’s humming along on xAI’s custom stacks (likely TSMC-sourced too), while Microsoft, Amazon, and Apple sip from the same silicon well. This shared origin levels the battlefield—raw compute’s abundant, but victory hinges on what these players do with it. Is pricing per million tokens the supernova that decides their fates? Let’s zoom in.
The AI Token Economy: A Meteor Shower of Disruption
Pricing per million tokens is shaking the galaxy like a rogue asteroid storm. Here’s the lineup:
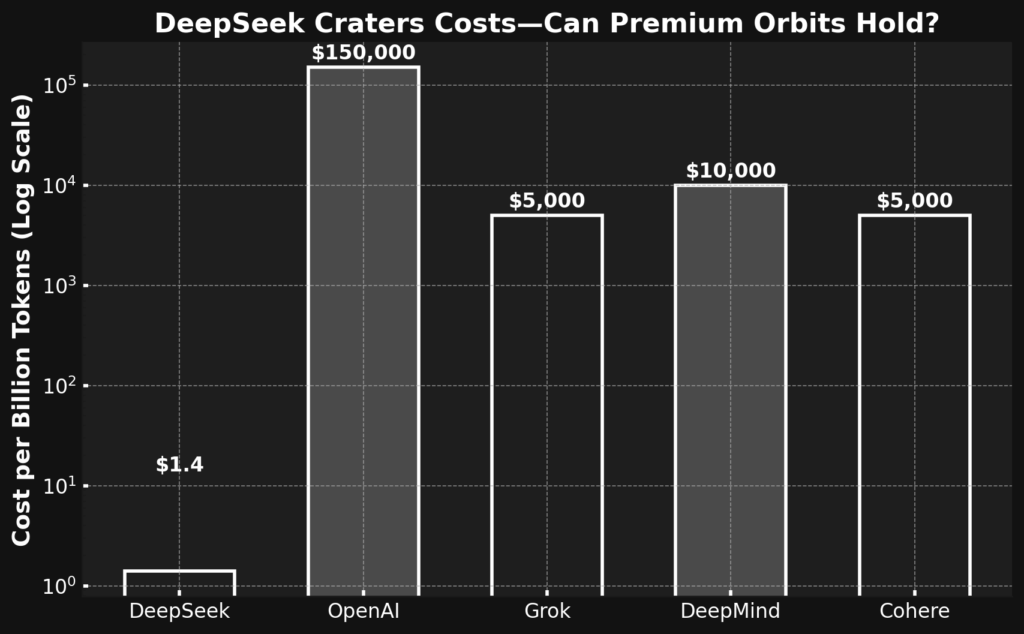
- DeepSeek: $0.14/million—practically free, a thrift-driven meteor strike. Free app for users, $1.4 per billion for devs.
- OpenAI: $15–$20/million for o1—a premium starship, but costly fuel at $150K per billion.
- Grok: No public token pricing yet (xAI keeps it cryptic), but expect $1–$5/million, given their efficiency obsession.
- Google DeepMind: Doesn’t sell tokens directly—AlphaFold’s a research comet, not a service. But inference costs on Google Cloud? Easily $10+/million.
- Hugging Face: Open-source transformers are “free” to run, but hosted APIs hit $1–$10/million depending on scale.
- Cohere: Business-friendly at $1–$5/million—pragmatic, not galactic.
- Anthropic: Claude’s $3–$15/million—safety-first pricing with a premium sheen.
Nvidia’s the blacksmith, not the knight—its GPUs enable these rates, not dictate them. Amazon’s AWS AI, Microsoft’s Azure, and IBM’s Watson orbit higher ($20+/million). Apple’s Siri and Baidu’s Ernie don’t tokenize publicly, but their internal costs align with compute heft—$5–$15/million. Tencent and FAIR? Research-focused, less tokenized, but humming on pricey silicon too.
Semiconductors: The Fuel of the AI Cosmos
Semiconductors are the stardust of AI—tiny miracles of silicon that turn electricity into intelligence. They’re etched with billions of transistors, shrinking to 2nm (a hair’s width is 80,000nm!), packing more power into less space. For AI, they’re the engines of training (crunching trillions of parameters) and inference (running models for chatbots, image gen, or protein folding). But what’s the hardware recipe for AI to soar?
-
- Compute Power: AI demands petaflops—quadrillions of calculations per second. Nvidia’s H100 delivers 4 petaflops (20 for Blackwell B200), while Apple’s M4 Max hits ~0.038 petaflops (38 TOPS, 8-bit). Training GPT-4? You need hundreds of GPUs; inference? A handful or a beefy NPU.
-
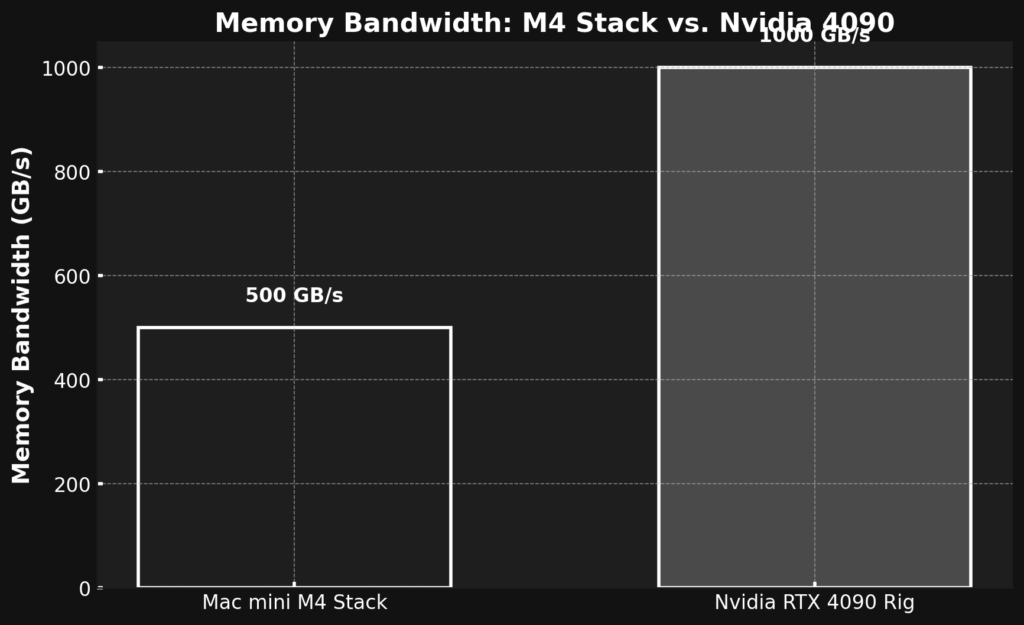
- Memory Bandwidth: AI slurps data fast. HBM3e (Nvidia’s choice) offers 8 TB/s; Apple’s unified memory pools 128GB at 500 GB/s—slower but seamless.
-
- Efficiency: Training burns megawatts; inference needs thrift. Nvidia’s cuLitho slashes fab power 9x; Apple’s M4 sips 20W versus an H100’s 700W
Nvidia’s Splash: Nvidia made waves with its Ampere and Hopper GPUs, then Blackwell’s 20-petaflop leap—TSMC’s 4nm magic behind it. Its cuLitho software turned lithography into a GPU sprint, cutting photomask times from weeks to overnight, cementing its 80% AI chip dominance. Why? CUDA’s ecosystem, raw power, and TSMC’s precision.
TSMC’s Throne: TSMC crafts 90% of bleeding-edge chips—2nm, 4nm, 7nm. Without it, Nvidia’s designs stay paper, OpenAI’s models stall, and Apple’s M4 fades. Its Arizona fabs ($65B bet) aim to onshore this wizardry, dodging geopolitical quakes. TSMC’s not just a supplier—it’s the galaxy’s heartbeat.
Apple’s Unified Memory Secret: Apple’s M-series fuses CPU, GPU, and NPU into one chip with shared memory—no data shuffling between silos like Nvidia’s discrete GPUs. This cuts latency, boosts efficiency, and shines for local inference (think 70B models on a Mac mini). Unknowingly, it’s carving a niche—quiet power for home AI labs, not data-center beasts.
Technical Breakdown: The AI Token Cosmos
AI Token pricing reflects efficiency and architecture:
- DeepSeek’s Sparse MoE: 141B params, 20% active. $5.6M training, $0.14/million inference—lean brilliance.
- OpenAI’s Dense Beasts: GPT-4’s 1T+ params, $100M+ training, $15/million—brute force royalty.
- Grok’s Lean Rocket: 50B params (est.), $1–$5/million—xAI’s efficiency ethos.
- DeepMind’s Precision: AlphaFold’s 100M params, $10/million equiv.—research, not retail.
The Galactic Differentiators
Pricing’s a flare, but orbits shift on:
- Ecosystem Moons: Nvidia’s CUDA, OpenAI’s APIs, Google’s Cloud—sticky traps. DeepSeek and Grok are still budding.
- Scale & Trust: IBM’s banks, Amazon’s homes, Anthropic’s safety—vs. DeepSeek’s China quirks.
- Innovation Thrust: Nvidia’s Blackwell, DeepMind’s RL, OpenAI’s GPT-5—pace matters.
- Market Pulsars: Nvidia’s $3T wobble, OpenAI’s $157B—sentiment sways.
Home AI Lab: Stackable M4 Minis vs. Nvidia Rig
Let’s warp to Earth—a home AI setup for $5,000, running a 70B model (e.g., LLaMA-70B). Two contenders: stacked Apple Mac mini M4s vs. an Nvidia RTX 4090 rig. Who wins on performance, energy, and heat?
Setup 1: 3x Mac mini M4 Stack
- Hardware: 3x M4 (12-core CPU, 16-core GPU, 38 TOPS), 64GB unified memory each. $1,599 x 3 = $4,797
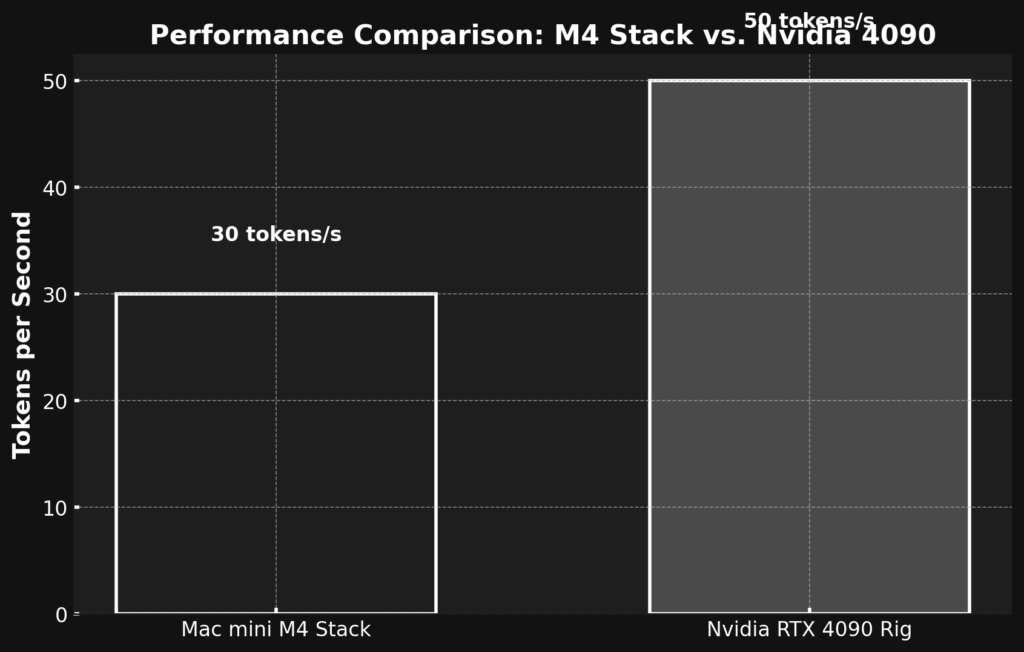
- Performance: ~114 TOPS total (8-bit). Runs 70B at ~10 ai tokens/s (unified memory shines for inference). Parallelize across units via MLX framework—~30 ai tokens/s combined.
- Energy: 20W idle, 50W peak per unit. Total: 150W peak
- Heat: ~50°C per unit, stackable with passive cooling. Quiet, home-friendly.
- Pros: Seamless memory, low power, macOS polish.
- Cons: No CUDA, tops out at mid-tier models.
Setup 2: Nvidia RTX 4090 Ri
- Hardware: RTX 4090 (24GB VRAM, 1 petaflop FP8), Ryzen 9 5900X, 64GB DDR4. ~$4,800 (GPU $1,600, rest $3,200).
- Performance: 1 petaflop crushes 70B at ~50 ai tokens/s (FP8, CUDA optimized). Scalable to 100B+ with tweaks.
- Energy: 4090 hits 450W peak, CPU/system ~200W. Total: 650W peak.
- Heat: 70–80°C under load; beefy fans roar. Needs space, cooling hacks.
- Pros: Raw power, CUDA ecosystem, future-proof
- Cons: Power hog, heat beast, noisy.
")
Verdict
- Performance: Nvidia wins—50 tokens/s vs. 30. For big models or training, it’s king.
- Energy: M4 stack sips 150W vs. 650W—4x thriftier, wallet-friendly bills.
- Heat: M4s stay cool (50°C) vs. 4090’s furnace (80°C)—home comfort edge.
- Price Parity: Both ~$5K, but M4s scale quieter, greener.
Scenario: You’re coding an AI poet in your living room. The M4 stack hums silently, sipping power, spitting 30 poems/min—just enough. Nvidia’s rig roars like a jet, pumping 50 poems/min but frying your socks off. For home inference, Apple’s unified memory sneaks a win—efficiency trumps brute force.
Lab Session: AI Token Pricing Showdown
Simulate costs:
python
def calc_token_cost(model, tokens, price_per_million):
cost = (tokens / 1_000_000) * price_per_million
return f"{model}: ${cost:.2f}"
models = {“DeepSeek”: 0.14, “OpenAI”: 15, “Grok”: 2.5, “Cohere”: 5}
for model, price in models.items():
print(calc_token_cost(model, 1_000_000_000, price))User Stories: Voices from the VoidIndie Ian: “DeepSeek’s $140/billion built my game AI. OpenAI? Broke!”
Corp Carla: “Azure’s $20/million runs our chain—reliable.”
Researcher Ravi: “AlphaFold’s free outputs saved months!”
Home Hacker Hana: “M4 stack’s quiet—Nvidia’s a sauna!”Code Dive: Sparse MoE
python
def sparse_moe(input, experts, top_k=2):
scores = [expert.score(input) for expert in experts]
top_experts = sorted(range(len(scores)), key=lambda i: scores[i], reverse=True)[:top_k]
output = sum(experts[i](input) * scores[i] for i in top_experts)
return output / sum(scores[i] for i in top_experts)
The Verdict
Tokens flare bright—DeepSeek’s thrift, OpenAI’s luxury, Grok’s edge. Semiconductors (TSMC’s gift) and unified memory (Apple’s twist) reshape the game. Nvidia’s splash and TSMC’s might hold the core, but home labs tilt to efficiency.
Pricing sparks; execution reigns.
AI isn’t just a software game—it’s a hardware-fueled arms race. The power of inference and training boils down to silicon efficiency, ecosystem lock-in, and token economics. Whether you’re a dev bootstrapping an AI side hustle or a cloud titan crunching billions, cost per million tokens is your new currency. Pick your AI engine wisely, and may the best model win!