
SCALA & SPARK for Managing & Analyzing BIG DATA
- SCALA & SPARK for Managing & Analyzing BIG DATA
- The Power of Scala in Data-Intensive Applications
- Error Handling and Fault Tolerance in Scala
- Concurrency and Parallelism in Scala
- Advanced Type Classes and Implicits in Scala
- Concurrency in Scala
- Advanced Functional Programming in Scala
- Functional Programming in Scala
- Scala Basics
SCALA & SPARK for Managing & Analyzing BIG DATA
In this blog, we’ll explore how to use Scala and Spark to manage and analyze Big Data effectively. When I first entered the Big Data world, Hadoop was the primary tool. As I discussed in my previous blogs:
- [What’s so BIG about Big Data (Published in 2013)]
- [Apache Hadoop 2.7.2 on macOS Sierra (Published in 2016)]
Since then, Spark has emerged as a powerful tool, especially for applications where speed (or “Velocity”) is essential in processing data. We’ll focus on how Spark, combined with Scala, addresses the “Velocity” aspect of Big Data while introducing a proposed architecture and sample project to illustrate this framework.
Table of Contents
- Introduction to Big Data and the 10 V’s
- Why Apache Spark over Hadoop MapReduce?
- Getting Started with Scala
- Apache Spark: An Introduction
- Proposed Architecture Framework
- Sample Project: Real-Time E-Commerce Recommendation System
- Data Flow Architecture Diagram
- Project Folder Structure
- Next Steps in Learning Scala and Spark
1. Introduction to Big Data and the 10 V’s
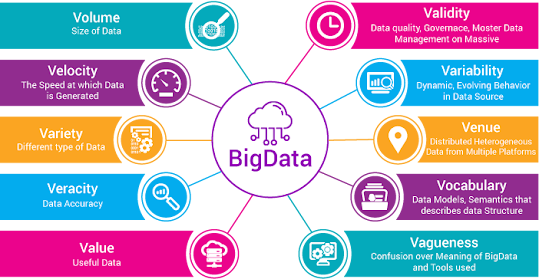
Big Data has grown in scope to include not only Volume but also nine additional “V’s” that describe its challenges and characteristics:
- Volume: Scale of data.
- Velocity: Speed of data generation and processing.
- Variety: Diversity of data types.
- Veracity: Trustworthiness of data.
- Value: Potential insights from data.
- Variability: Inconsistencies in data.
- Visualization: Representing data meaningfully.
- Vulnerability: Data security.
- Volatility: Duration data remains relevant.
- Validity: Accuracy of data.
By focusing on “Velocity,” we can harness Spark’s speed to process and analyze data in real time, enabling fast decision-making.
2. Why Apache Spark over Hadoop MapReduce?
Comparing Hadoop MapReduce and Apache Spark for Big Data processing:
- Speed: Spark’s in-memory operations allow it to process data up to 100x faster than Hadoop.
- Use Case Fit: Spark excels with streaming data and quick turnarounds, while Hadoop handles vast data volumes with minimal memory use.
- Language Compatibility: Spark, written in Scala, works efficiently with Scala code, offering performance and simplicity in distributed processing tasks.
3. Getting Started with Scala
What is Scala?
Scala is a versatile language that merges object-oriented and functional programming paradigms. Running on the JVM, it is interoperable with Java, which enables seamless integration with Java libraries.
Benefits of Scala for Big Data
- Conciseness: Reduces code complexity in data transformations.
- Interoperability: Scala can leverage Java libraries for Big Data, expanding its utility.
- Immutability: Supports safe parallel processing, which is crucial in distributed systems.
4. Apache Spark: An Introduction
Apache Spark is a distributed data processing system optimized for large-scale data across clusters.
Core Components
- Spark Core: Manages data operations, scheduling, and fault tolerance.
- Spark SQL: Enables SQL-based data querying.
- Spark Streaming: Processes real-time data streams.
- MLlib: Machine learning library for predictive analytics.
- GraphX: Spark’s API for graph processing.
Spark’s Role in Big Data
Spark’s speed and efficiency make it a preferred tool for applications needing quick data insights, such as real-time analytics, iterative machine learning, and streaming data.
5. Proposed Architecture Framework
Below is a high-level architecture for implementing a Big Data management system with Scala and Spark.
-
Data Ingestion Layer
- Tools: Kafka, Flume, Spark Streaming
- Purpose: Capture real-time or batch data from sources like databases, IoT sensors, and log files.
-
Data Processing Layer
- Tools: Apache Spark with Scala
- Purpose: Perform transformations, aggregations, and enrichments. This includes:
- Batch Processing: For historical data.
- Real-Time Processing: For streaming analytics.
- Functions: Implemented in Scala using Spark SQL and DataFrames.
-
Data Storage Layer
- Tools: HDFS, Amazon S3, Cassandra
- Purpose: Store raw and processed data for analytics and future use.
-
Data Analytics and Machine Learning Layer
- Tools: MLlib, Spark SQL
- Purpose: Conduct predictive modeling, clustering, and pattern recognition.
-
Data Access and Visualization Layer
- Tools: Apache Zeppelin, Grafana
- Purpose: Provide dashboards and interfaces for querying and visualizing data.
6. Sample Project: Real-Time E-Commerce Recommendation System
Project Overview
This project demonstrates a real-time recommendation system that processes clickstream data from an e-commerce platform, using Scala and Spark to recommend products.
- Ingest Data: Collect customer actions on the e-commerce site (e.g., clicks, views) into a Kafka topic.
- Process Data: Transform data to create user profiles and detect purchase intent.
- Build Recommendation Model: Use collaborative filtering with MLlib to recommend products based on user behavior.
- Store Data: Save processed profiles and recommendations to Cassandra for quick access.
- Visualize Data: Present popular products and recommendations in a real-time dashboard.
Step-by-Step Implementation
-
Set Up Ingestion with Kafka
-
Process Data with Spark SQL
-
Build Recommendation Model with MLlib
-
Store Data in Cassandra
-
Visualize with Grafana
- Connect Grafana to the data source for real-time visualizations.
7. Data Flow Architecture Diagram
Below is a whiteboard-style architecture diagram illustrating the data flow for this project.

8. Project Folder Structure
Organize the project as follows to keep code modular and organized.
- src/main/scala: Source code for ingestion, processing, and machine learning modules.
- src/test/scala: Unit tests for each module.
- resources/config: Configuration files for Kafka, Cassandra, and Spark.
- docs: Documentation and architecture diagram.
- README.md: Project overview and instructions.
9. Next Steps in Learning Scala and Spark
- Deepen Scala Knowledge: Learn functional programming, concurrency, and type-safe design patterns.
- Master Spark’s Ecosystem: Advance with Spark SQL, MLlib, and GraphX.
- Optimize Spark Performance: Study tuning techniques like caching and partitioning.
- Deploy on Cloud Platforms: Set up Spark on AWS EMR or Databricks for handling large datasets.
- Real-Time Projects: Practice with real-time streaming applications and big data integration tools like Kafka.
In this blog, we covered why Scala and Spark are an ideal combination for managing and analyzing Big Data, particularly in real-time applications like e-commerce recommendations. We explored the proposed architecture, walked through a practical project example, and examined how each component—Kafka, Spark, Cassandra, MLlib, and Grafana—plays a role in the data flow from ingestion to visualization.
In future blogs, we’ll dive deeper into specific elements like Scala programming basics, Spark’s core features, and tools such as Kafka, Cassandra, and MLlib. This series will help you gain a comprehensive understanding of each tool and how they collectively power Big Data applications. By following this series, you’ll develop a solid foundation for managing, processing, and analyzing data using Scala, Spark, and complementary technologies.