Data Fabric and Data Mesh: Understanding Decentralized Data Architectures for Modern Applications
Introduction
Back in 2013, I began blogging about Big Data, diving into the ways massive data volumes and new technologies were transforming industries. Over the years, I’ve explored various aspects of data management, from data storage to processing frameworks, as these technologies have evolved. Today, the conversation has shifted towards decentralized data architectures, with Data Fabric and Data Mesh emerging as powerful approaches for enabling agility, scalability, and data-driven insights.
In this blog, I’ll discuss the core concepts of Data Fabric and Data Mesh, their key differences, and their roles in modern applications. I’ll also share a bit of my own journey, including my work on the Data Fabric concept at TIBCO and how I was introduced to Data Mesh through LinkedIn posts by Zhamak Dehghani from ThoughtWorks.
The Evolution of Data Management: Data Fabric and Data Mesh
After joining TIBCO, we embarked on developing the Data Fabric concept to enable unified data access across complex environments. This work led to the TIBCO Data Fabric, which leveraged TIBCO Unify capabilities by combining TIBCO Data Virtualization with TIBCO EBX, our master data management platform. This integration created a seamless data layer, allowing organizations to access and manage data across disparate systems without needing to worry about physical storage. It was a major step forward for TIBCO’s data management portfolio, aligning closely with the Data Fabric vision of automated integration, governance, and compliance.
Around the same time, Data Mesh was gaining popularity as a new way to decentralize data management. I first encountered it through LinkedIn posts by Zhamak Dehghani, a technologist at ThoughtWorks, who conceptualized Data Mesh. Zhamak’s insights emphasized data as a product and domain-oriented ownership—concepts that address many of the limitations we’ve seen in centralized data architectures. You can read her thoughts on the foundational principles of Data Mesh in her article “How to Build the Data Mesh Foundation: A Principled Approach”, which explores the key pillars of Data Mesh architecture.
Understanding Data Fabric
The concept of Data Fabric has gained significant traction as organizations manage increasingly complex data landscapes. By focusing on connectivity, automation, and governance, Data Fabric architectures offer a powerful framework for integrating data across hybrid environments, breaking down silos, and providing seamless data access. Here’s an in-depth look at Data Fabric, its features, and how it contrasts with centralized and decentralized data architectures.
What is Data Fabric?
Data Fabric is an architectural approach that creates a cohesive data layer across the organization, enabling unified access to distributed data, whether it resides on-premises, in the cloud, or across edge systems. By abstracting and integrating data, Data Fabric allows businesses to access, transform, and analyze data in real-time or near real-time.
Key Benefits of Data Fabric
- Unified Data Access: By connecting disparate data sources, Data Fabric enables a single point of access across all data locations, providing transparency and consistency for data users.
- Automated Data Integration: Leveraging AI and ML capabilities, Data Fabric simplifies and automates the process of data integration, reducing manual efforts and improving efficiency.
- Enhanced Governance and Compliance: Centralized data policies and governance frameworks ensure data privacy, compliance, and security across the enterprise.
- Real-Time Data Access: Ideal for applications requiring immediate insights, Data Fabric enables real-time and near real-time data processing for faster, data-driven decision-making.
Data Fabric vs. Data Virtualization
One common question is how Data Fabric differs from Data Virtualization. While Data Virtualization provides a layer for accessing data across silos without replication, Data Fabric takes this a step further by encompassing a broader scope of data management capabilities, including data cataloging, data quality, data modeling, and governance. Data Fabric delivers a holistic data management platform for use cases like Customer 360, operational intelligence, and IoT analytics.
Building Blocks of Data Fabric

To construct a comprehensive Data Fabric, certain core components are essential. These building blocks work together to create an interconnected, high-functioning data ecosystem:
- Data Virtualization: Provides a virtual data layer, allowing data to be accessed and combined in real time across various sources.


- Master Data Management (MDM): Ensures data consistency and quality by governing critical entities like customer, product, and supplier data.
- Data Cataloging and Metadata Management: Organizes and classifies data assets, enabling discovery, understanding, and reuse.

- Data Governance: Establishes consistent data policies, quality standards, and compliance frameworks.

- Data Quality and Lineage: Tracks data accuracy and history, ensuring reliable data flows and audit-ability.
Implementing Data Fabric with TIBCO
At TIBCO, we combined TIBCO Data Virtualization with TIBCO EBX for a comprehensive Data Fabric solution. This setup enabled our clients to have seamless access to data across multiple environments and robust master data management. With over 350 connectors, including options for streaming data sources, this Data Fabric supported real-time and batch data integration for diverse business needs—from compliance and governance to advanced analytics and reporting.

Data Fabric in Action: Real-World Use Cases
- Customer 360 View: Data Fabric supports unified views of customer data across touchpoints, improving personalization and decision-making.
- IoT Analytics: For IoT environments, Data Fabric enables real-time data processing from various sensors, offering valuable insights for predictive maintenance and operational intelligence.
- Compliance and Risk Management: Organizations can leverage Data Fabric to ensure compliance with data privacy regulations, track data lineage, and manage data access.
Future of Data Fabric
As data complexity grows, Data Fabric is expected to evolve, incorporating AI-driven data integration, enhanced data quality metrics, and more comprehensive governance capabilities. With an increased emphasis on real-time data and cross-functional data access, Data Fabric will remain central to enterprise data strategy, driving agility, compliance, and innovation.
Implementing Data Fabric in Your Organization
When considering Data Fabric for your organization, focus on the following:
- Data Inventory: Catalog your data assets and assess integration requirements.
- Technology Selection: Choose tools that align with your existing architecture and support hybrid, multi-cloud, or on-premises needs.
- Data Governance Strategy: Establish a governance framework to ensure data privacy, quality, and compliance across environments.
- Iterative Deployment: Start small, focusing on high-impact use cases like Customer 360, and scale up as your data requirements evolve.
Exploring Data Mesh
Data Mesh takes a decentralized approach to data management, where data is treated as a product and managed by domain-specific teams within the organization. Instead of having a centralized team handle all data, Data Mesh assigns data ownership to cross-functional domains, allowing each team to manage, maintain, and serve their own data products.
Key Principles of Data Mesh
- Domain Ownership: Each team owns and manages its data, which makes them responsible for its quality, accessibility, and lifecycle.
- Data as a Product: Each domain focuses on providing high-quality, user-friendly data as a product for its consumers.
- Self-Serve Data Infrastructure: Provides tools and frameworks for domains to manage data independently.
- Federated Governance: While data domains have autonomy, a federated governance model ensures consistency, security, and compliance across the organization.
This decentralized approach appealed to me as I saw Zhamak’s posts on LinkedIn and her explanation of Data Mesh. Her approach addressed some of the biggest challenges we face in large organizations—bottlenecks in centralized data systems, lack of agility, and data silos that impede collaboration and data-driven decision-making. Thanks to Mark Palmer here is how we think our Data Fabric can meet Data Mesh.
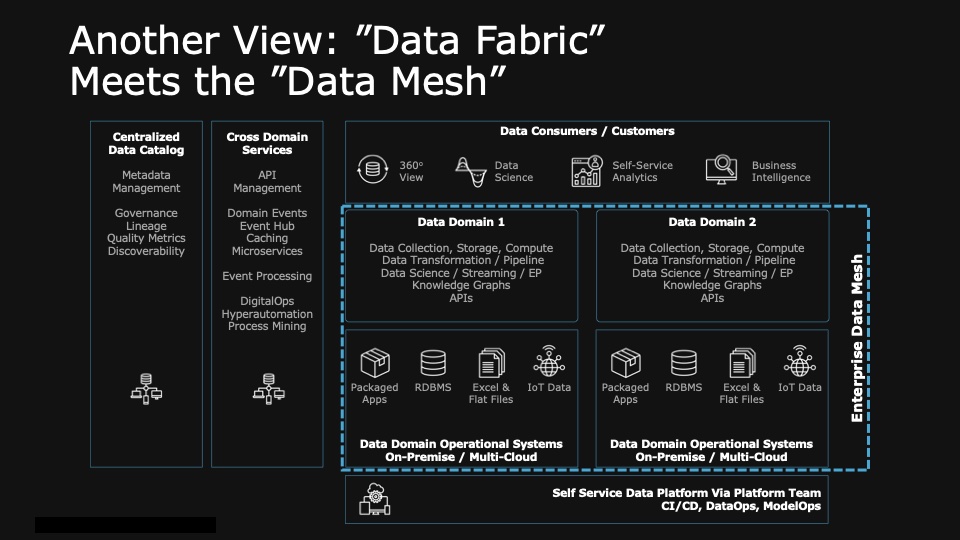
Data Fabric vs. Data Mesh: Key Differences
| Aspect | Data Fabric | Data Mesh |
|---|---|---|
| Core Concept | Unified data access across systems | Decentralized, domain-oriented data ownership |
| Management | Centralized management | Decentralized, domain-level management |
| Data Handling | Data integration and real-time access | Data as a product within domains |
| Infrastructure | Virtual layer connecting hybrid environments | Independent, self-serve data infrastructure |
| Governance | Centralized governance | Federated governance |
| Ideal Use Cases | Hybrid or multi-cloud environments | Large organizations with varied data needs |
Why Decentralized Architectures Matter
Centralized data systems can hinder agility and innovation, especially in today’s fast-paced, data-driven world. Decentralized architectures like Data Fabric and Data Mesh address these issues by allowing teams to work independently, reducing bottlenecks, and improving scalability.
Data Fabric and Data Mesh in Today’s Applications
In the age of AI, real-time analytics, and IoT, both Data Fabric and Data Mesh architectures support modern application demands in unique ways:
- Real-Time Analytics: Data Fabric provides real-time access across environments, crucial for applications like fraud detection and personalization.
- AI and Machine Learning: Data Mesh empowers data scientists within each domain to access the data they need without waiting for centralized teams, fostering innovation and faster experimentation.
- Data-Driven Decision-Making: Data Fabric’s unified view supports cross-functional decisions, while Data Mesh allows domains to make independent, data-driven choices.
- Collaboration Across Teams: Both architectures break down data silos, encouraging cross-functional collaboration and faster insights.
When to Use Data Fabric and Data Mesh
Choosing between Data Fabric and Data Mesh depends on the organization’s specific needs and structure:
- Choose Data Fabric If:
- Your organization operates in a hybrid or multi-cloud environment and requires unified access to data across various locations.
- You need automated integration, real-time data access, and centralized governance.
- Choose Data Mesh If:
- Your organization is large and complex, with independent business units or functions that need to manage their own data.
- You want to treat data as a product, allowing each domain to take ownership and responsibility for their data.
Challenges and Considerations
Implementing these architectures requires strategic planning and organizational change:
- Data Fabric: Ensuring governance and consistent policies across distributed environments can be complex.
- Data Mesh: Shifting data ownership to domain teams involves a cultural shift and may require training and new processes.
Conclusion
Data Fabric and Data Mesh represent the future of decentralized data architecture, each offering unique solutions to the challenges of modern data management. At TIBCO, our work on TIBCO Data Fabric aimed to provide clients with seamless data access and governance across environments, while Zhamak Dehghani’s Data Mesh concept has opened up new ways of democratizing data management by promoting domain-oriented ownership.
As we move forward, both architectures will play central roles in helping organizations meet the demands of a data-centric world. Whether your organization needs a cohesive Data Fabric or a decentralized Data Mesh, both approaches offer a powerful foundation for scalable, flexible, and efficient data management in the years ahead.