
What’s so BIG about Big Data

What’s So BIG About Big Data?
BIG DATA: The Big Daddy of All Data
Big Data is a transformative field that enables the analysis, extraction, and systematic handling of massive datasets that are beyond the capabilities of traditional data-processing tools. It has reshaped industries, research, and business decision-making by offering insights from vast amounts of information, revealing patterns, trends, and correlations on an unprecedented scale.
Characteristics of Big Data
Big Data is generally defined by four main characteristics, known as the 4 Vs: Volume, Variety, Velocity, and Veracity. Here’s a breakdown of each:
- Volume: This refers to the massive quantity of data generated every second, requiring advanced tools to store, manage, and process it.
- Velocity: The speed at which data flows from various sources, including social media, IoT devices, financial markets, and more, demands real-time processing capabilities.
- Variety: Big Data encompasses structured, semi-structured, and unstructured data types, sourced from databases, spreadsheets, images, videos, and more.
- Veracity: Ensuring the reliability and quality of data is essential to gaining meaningful insights, as poor data quality can distort findings and lead to poor decision-making.
Local vs. Distributed Systems

We can use a local system for storing data that can fit on a local computer on a scale of 0-32 GB depending on RAM.


However if we have larger data set. That means instead of holding the data in-memory on ram we can move it onto a storage on sql database onto a hard drive instead of a a ram. Or we can use a cloud database using SQL Or we will need to use a distributed system, that distributes the data to multiple machines or computer.

As data grows, storing and processing it on a single local machine becomes impractical. Here’s a comparison:
- Local Systems: These systems store data on individual machines, limited by the device’s CPU, RAM, and storage. They are ideal for smaller datasets that can fit within these physical limits.
- Distributed Systems: For large datasets, distributed systems distribute data across multiple machines, enabling horizontal scaling. This setup is managed by a central controller and allows for more processing power by utilizing multiple nodes, supporting fault tolerance and faster data access.
The Big Picture: How Big Data Impacts Large Enterprises
Imagine an enterprise with millions of customers, multiple business domains, and vast amounts of data generated daily. This data could be a goldmine for optimizing operations, boosting sales, and enhancing customer satisfaction. But without a structured approach, it’s overwhelming.
The solution lies in data governance and management frameworks that can process these data silos, transforming raw information into actionable insights. The goal is to know which data is reliable, valuable, and capable of delivering the most impact.
Challenges in Handling Big Data
Big Data presents unique challenges beyond traditional data handling:
- Data Capture and Cleaning: Raw data must be collected and cleansed to ensure accuracy and remove inconsistencies.
- Storage: Reliable and scalable storage solutions are essential to accommodate Big Data.
- Analysis: Advanced analytics tools are needed to extract insights from vast datasets.
- Visualization: Presenting data in meaningful ways helps stakeholders understand complex information.
To address these challenges, advanced tools and algorithms are necessary—one of the most popular solutions being Apache Hadoop.
Apache Hadoop: The Backbone of Big Data

Apache Hadoop is an open-source framework designed for processing large datasets in a distributed computing environment. It consists of several key components that enable scalable, fault-tolerant storage and parallel processing across commodity hardware. Here’s a look at some of its core features:
- Hadoop Distributed File System (HDFS): HDFS stores massive data files across multiple nodes, replicating data blocks to ensure fault tolerance.
- MapReduce: This programming model splits computation tasks across nodes in a cluster, performing parallel processing to handle vast amounts of data.
Exploring Hadoop’s Ecosystem

The Hadoop ecosystem comprises various tools that enable more specialized tasks within the Big Data space:
- HDFS (Distributed Storage): Divides data into 128 MB blocks and replicates them across nodes for fault tolerance and faster access.

- MapReduce (Data Processing): Allows data to be processed in parallel across a distributed cluster, ideal for handling large-scale computations.

- Hive: A data warehouse layer on top of Hadoop, allowing SQL-like querying for non-programmers.
- HBase: A NoSQL database running on Hadoop, designed for real-time, random read/write access to large datasets.
- Pig: A high-level platform for creating MapReduce programs, with an easy-to-read scripting language.
- Spark: Known for its speed and ease of use, Spark provides a powerful alternative to MapReduce by allowing in-memory processing.


Real-Life Applications of Big Data
Across industries, Big Data applications are vast and varied, offering solutions for real-time and predictive insights:
- Retail: Analyzing customer buying patterns to optimize product recommendations and inventory management.
- Healthcare: Predictive analytics to identify health risks and optimize patient care.
- Finance: Fraud detection by analyzing transaction patterns in real-time.
- Manufacturing: Predictive maintenance using data from IoT sensors.
Sample Project 1
Project Overview: Real-Time Sentiment Analysis for Social Media
Goal: Monitor social media channels for brand mentions and analyze sentiment in real-time.
Tools: HDFS, MapReduce, Hive, and HBase.
Step-by-Step Project Implementation
- Data Ingestion
- Use HDFS to store social media feeds from various platforms.
- Data Processing with MapReduce
- Perform data cleansing and tokenization to prepare text for sentiment analysis.
- Use MapReduce to parallelize the processing across nodes.
- Data Analysis with Hive
- Load the processed data into Hive to analyze sentiment by time, location, and user demographics.
- Data Storage and Access with HBase
- Store frequently accessed data in HBase for fast retrieval.
- Visualization
- Connect Hive data to visualization tools to create dashboards that display trends in real-time.
Sample Project 2: Game of Thrones Character Count with MapReduce
Project Overview: Analyzing Duplicate Characters in GOT
Goal: To count occurrences of Game of Thrones characters in a sample dataset and identify duplicates.
Tools: HDFS and MapReduce.
Dataset
Here is the dataset of Game of Thrones character names:
Step-by-Step Project Implementation
- Data Ingestion with HDFS
- Store the dataset in HDFS to enable distributed processing.
- MapReduce Process
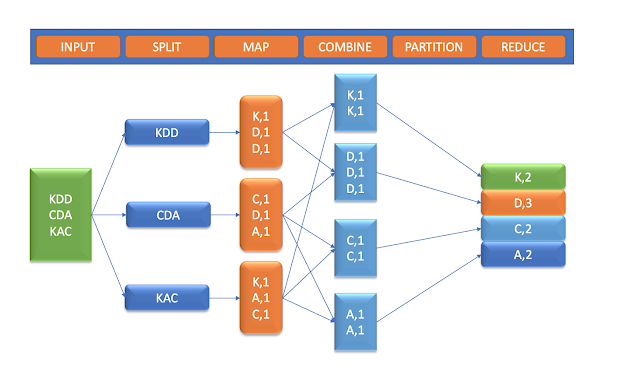
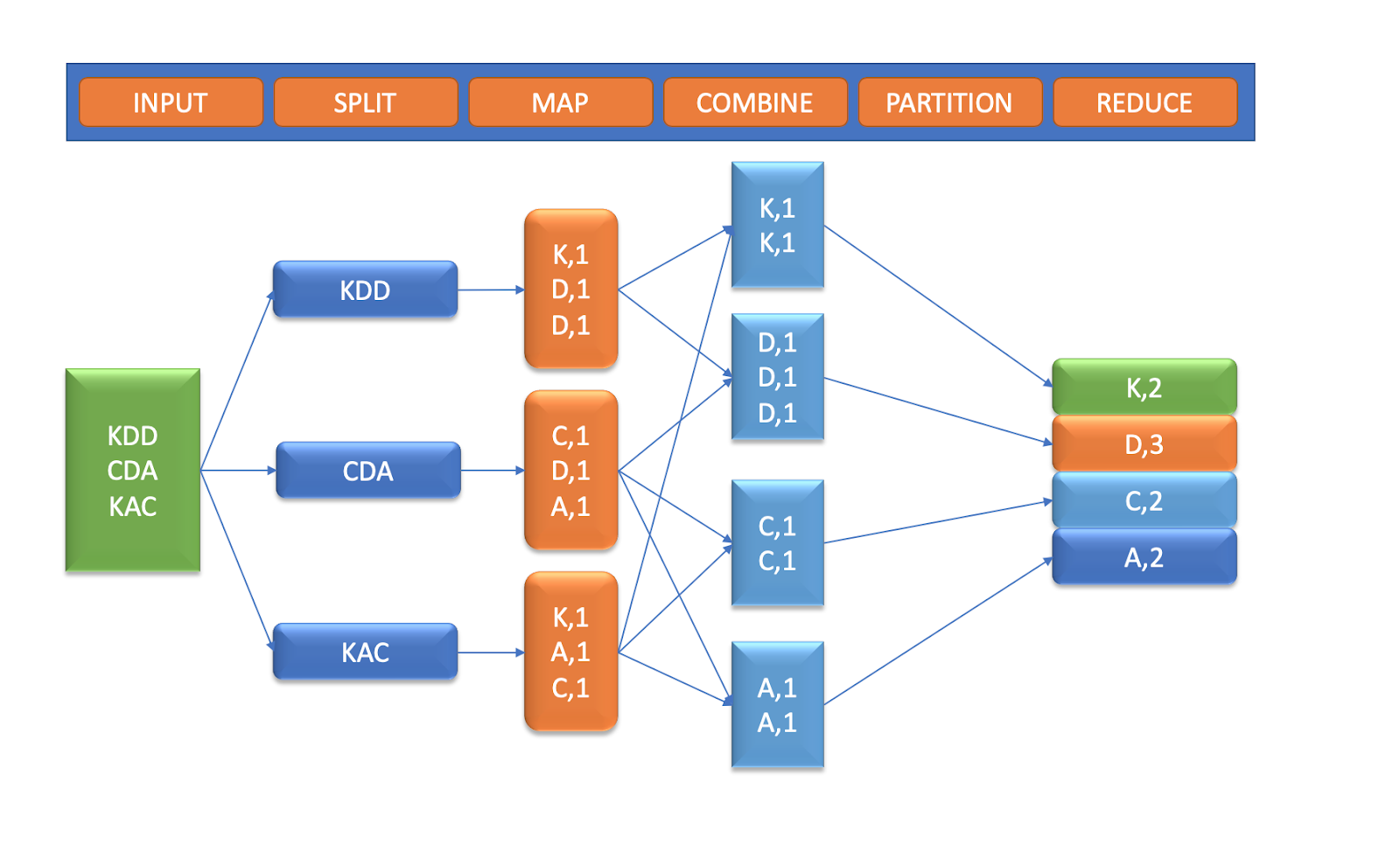
- Map Phase: In this phase, each character name is assigned a key-value pair, where the name is the key, and the count is the value
1.
Example of key-value pairs generated:
- Reduce Phase: This phase combines key-value pairs with the same key (character name), summing up the values to get the count of each character.
Result of the Reduce phase:
- Output in HDFS
- The output of the MapReduce job, with unique character counts, is saved in HDFS:
- AnalysisThe final output shows the count of each character, helping to identify duplicates in the dataset.
Project Folder Structure
Here’s a recommended folder structure for a project using Hadoop, Hive, and HBase:
Next Steps in Learning Big Data
To further explore Big Data, consider the following:
- Advanced Hadoop
- Learn about YARN for resource management and optimizations within HDFS and MapReduce.
- Hands-On with Hive
- Practice creating tables, using partitions, and running complex queries in Hive.
- NoSQL with HBase
- Study HBase architecture, including schema design and efficient query patterns.
- Data Pipeline Creation
- Combine Hadoop, Hive, and HBase to create end-to-end data pipelines.
- Visualization
- Use tools like Tableau or Power BI to display Big Data insights.
Conclusion
Big Data has become the powerhouse behind modern analytics, reshaping industries and enabling deeper, faster insights. By harnessing tools like Hadoop, Hive, and HBase, organizations can manage and analyze vast datasets in innovative ways. As you explore Big Data further, mastering these technologies will open doors to creating more robust and scalable data solutions. In future posts, we’ll cover these components in more detail, diving deeper into each tool and exploring advanced implementations.
Thanks for this post!
You are welcome!