
Understanding Exchanges, Queues, and Bindings in RabbitMQ with a Replay Mechanism Project
- Introduction to RabbitMQ and Messaging Fundamentals
- Installing RabbitMQ on macOS and Setting Up Your First Environment
- Understanding Exchanges, Queues, and Bindings in RabbitMQ with a Replay Mechanism Project
- Advanced Routing and Message Patterns in RabbitMQ: Dynamic Routing, Multi-Level Bindings, and Message Transformations
- Implementing Dead Letter Queues and Retry Mechanisms in RabbitMQ for Resilient Messaging
- Optimizing RabbitMQ Performance: Scaling, Monitoring, and Best Practices
- RabbitMQ Security Best Practices: Authentication, Authorization, and Encryption
Introduction
RabbitMQ is a powerful open-source message broker that enables communication between distributed services in an asynchronous manner. To master RabbitMQ, it’s essential to understand its core components: Exchanges, Queues, and Bindings. This blog post will explain each component and how they work together to route messages. We’ll also explore different types of exchanges—direct, fanout, topic, and headers—along with their use cases and best practices.
To put this knowledge into practice, we’ll implement a Replay Mechanism Project. This project will allow users to replay specific messages from a queue by creating a Recorder Service that saves messages to a database. Subscribers can then request replays based on custom filters like date ranges.
Core Components of RabbitMQ
1. Exchanges
An exchange in RabbitMQ is an intermediary component that routes messages from producers to queues based on specified rules. Exchanges do not store messages; they simply forward them based on the routing logic. Here’s a breakdown of exchange types and when to use them:
- Direct Exchange: Routes messages to queues based on an exact match between the routing key and binding key.
- Use Case: Point-to-point communication where messages are sent to a specific queue based on a routing key.
- Fanout Exchange: Broadcasts messages to all queues bound to it, ignoring the routing key.
- Use Case: Publish-subscribe messaging where every subscriber should receive all messages, such as logging or notifications.
- Topic Exchange: Routes messages based on pattern matching of routing keys using wildcards.
- Use Case: Multi-level routing, where different parts of a message can be filtered by subscribers. Commonly used in event-based architectures.
- Headers Exchange: Routes messages based on message header attributes rather than the routing key.
- Use Case: Advanced routing based on message metadata, often used in complex routing scenarios.
2. Queues
A queue is a buffer that holds messages until they are consumed. Queues are durable, meaning they can persist messages even if RabbitMQ restarts, provided they are declared as durable.
Key properties of queues:
- Durable: Makes the queue survive RabbitMQ restarts.
- Exclusive: Limits the queue to the connection that declared it, deleting it when the connection closes.
- Auto-Delete: Automatically deletes the queue when all consumers disconnect.
3. Bindings
A binding is a link between an exchange and a queue, defining how messages should be routed. Each binding has a binding key, which is used by exchanges to decide which queue(s) should receive a message based on its routing key.
Message Flow and Patterns
The message flow in RabbitMQ depends on the type of exchange:
- Direct Exchange: Messages with a specific routing key are directed to queues bound with a matching binding key.
- Fanout Exchange: Messages are broadcast to all bound queues, regardless of routing key.
- Topic Exchange: Supports complex routing patterns with wildcards, allowing for flexible message routing based on multiple parts of a key.
- Headers Exchange: Routes messages based on matching headers rather than routing keys.
Use Cases and Best Practices
- Direct Exchange: Use for targeted messaging, where messages are meant for specific consumers.
- Fanout Exchange: Ideal for broadcasting, where all consumers need to receive the same message.
- Topic Exchange: Great for event-driven systems that require complex routing based on message types.
- Headers Exchange: Best for advanced routing requirements that depend on message attributes.
Project: Replay Mechanism in RabbitMQ
In this project, we’ll design a system that allows users to replay messages from a RabbitMQ queue. The replay mechanism involves a Recorder Service that records all messages to a database, enabling subscribers to request replays based on filters like date range.
Design of the Replay Mechanism
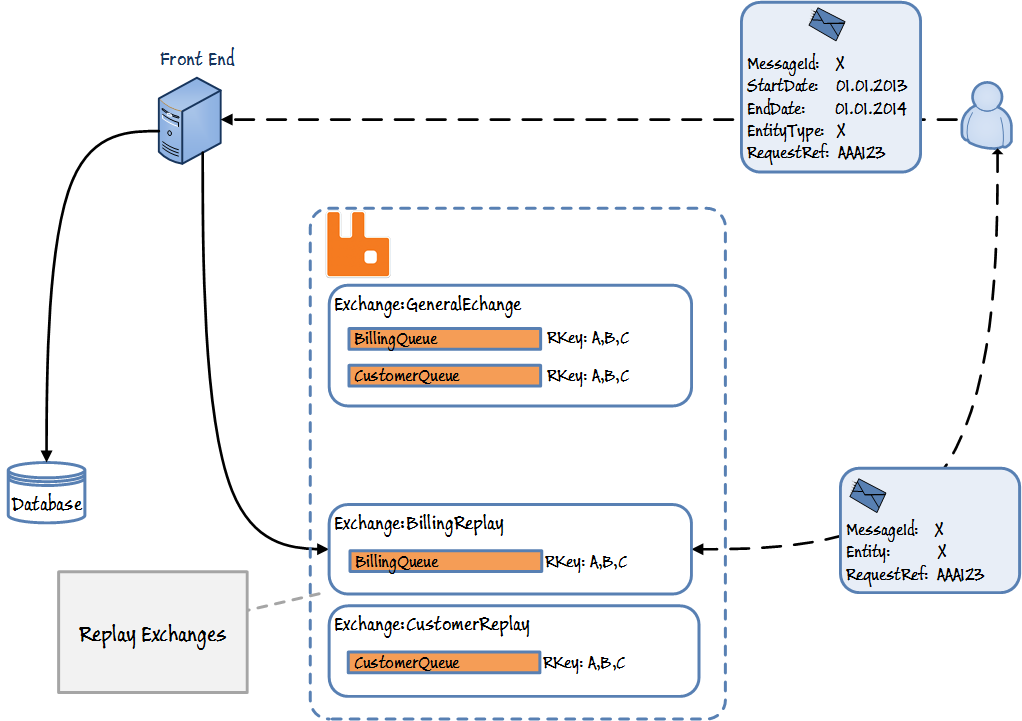
Steps:
- Create a Recorder Service:
- Set up a queue that binds to all routing keys of the main exchange.
- Consume all messages from this queue and save them to a database.
- Subscriber Replay Request:
- Each subscriber creates a custom exchange and queue for receiving replayed messages.
- The subscriber sends a REST request to the Replay API, specifying filters (e.g., start date) and the exchange name.
- Replay API:
- The API queries the database for messages matching the subscriber’s filter.
- It publishes these messages to the specified exchange, enabling the subscriber to receive past messages as if they were being sent in real-time.
- Enhancements:
- Attach a
RequestIdto each replayed message for tracking purposes. - Provide feedback to the subscriber about replay progress.
- Attach a
Step-by-Step Implementation Guide
Project Structure
Step 1: Initialize the Project
- Create the Project Folder:
- Set Up a Virtual Environment:
- Install Dependencies:
- Add dependencies to
requirements.txt: - Install with:
- Add dependencies to
Step 2: Implement the Recorder Service
- Recorder Queue: Capture all messages sent to the
GeneralExchangeby binding with a wildcard routing key. - Database Storage: Save each message’s metadata to the database.
recorder_service/recorder.py
Step 3: Create the Replay API
The API receives replay requests and fetches messages from the database based on specified filters, publishing them to the subscriber’s replay exchange.
replay_api/app.py
Step 4: Create the Subscriber Service
Each subscriber sets up a replay exchange and queue, then sends a replay request to the API.
subscriber_service/subscriber.py
Testing the Replay Mechanism
- Start the Recorder Service:
- Run the Replay API:
- Trigger Replay via Subscriber Service:
The subscriber service will send a replay request to the API, which retrieves relevant messages from the database and publishes them to the subscriber’s replay exchange.
To enhance the replay mechanism, we can add the following features:
- Request ID for Tracking: Attach a unique
Request IDto each replay request, which will help us track individual replay requests and maintain consistency. - Replay Status Feedback: Implement an endpoint for subscribers to check the status of their replay requests.
- Replay Throttling: Add rate-limiting to control the replay speed, ensuring we don’t overwhelm RabbitMQ or the database when replaying large amounts of data.
Let’s go over each enhancement and modify our existing code to include these improvements.
Enhancement 1: Request ID for Tracking
We’ll modify the Replay API to generate a unique Request ID for each replay request. This ID will be sent along with each message during the replay process, allowing subscribers to track messages associated with specific requests.
Modifications in replay_api/app.py
- Generate a
Request IDusing Python’suuidlibrary. - Include this ID in each message’s metadata during replay.
Enhancement 2: Replay Status Feedback
Create a new endpoint /replay_status that accepts a Request ID and returns the status and message count of the replay.
Add Status Check Endpoint in replay_api/app.py
Enhancement 3: Replay Throttling
Implement rate-limiting to avoid overwhelming RabbitMQ when publishing a large number of messages. We’ll use time.sleep() to add a delay between message publications, allowing controlled, batch-wise replaying.
Modify the Replay Process to Include Throttling
Add a REPLAY_THROTTLE_RATE setting in config.py for easy configuration of the throttle rate.
Then, modify the replay publishing loop to include a delay:
This ensures that messages are sent at a controlled rate, preventing potential overload of RabbitMQ or network resources.
Database Modifications
For tracking purposes, it’s also helpful to store the Request ID and replay status in a persistent database so that the status can be checked even if the API server restarts.
replay_api/database.py
Testing the Enhancements
- Request Replay:
- Make a POST request to
/replayto initiate a replay. - Check the response for the
Request ID.
Example:
- Make a POST request to
- Check Replay Status:
- Make a GET request to
/replay_status/<request_id>to get the replay status.
Example:
- Make a GET request to
- Verify Throttling:
- Observe the rate of messages published to RabbitMQ to confirm that the
REPLAY_THROTTLE_RATEsetting is respected.
- Observe the rate of messages published to RabbitMQ to confirm that the
Final Project Structure
The final structure of the project is as follows:
Summary of Enhancements
- Request ID for Tracking: Each replay request now has a unique
Request ID, allowing easy tracking of replayed messages. - Replay Status Feedback: Subscribers can check the status and progress of their replay requests via the
/replay_statusendpoint. - Replay Throttling: To prevent overload, we added rate-limiting using the
REPLAY_THROTTLE_RATEsetting.
These enhancements improve the robustness and scalability of the replay mechanism, making it suitable for handling high-volume message replays while maintaining system performance. Let me know if you’d like additional features or further clarification on any part!
Conclusion
In this blog post, we explored the core concepts of Exchanges, Queues, and Bindings in RabbitMQ, covering the mechanics of direct, fanout, topic, and headers exchanges along with their best-use cases. With a solid understanding of these components, we implemented a Replay Mechanism Project that allows subscribers to replay messages from RabbitMQ queues.
The project included creating a Recorder Service to capture and store messages, a Replay API to handle subscriber requests with date-based filters, and a Subscriber Service to initiate replays. We also added advanced enhancements, such as a unique Request ID for tracking replays, a Replay Status Feedback endpoint for subscribers to check replay progress, and Replay Throttling to avoid overwhelming RabbitMQ with large datasets.
With these features, we now have a robust, scalable replay mechanism that can handle various messaging scenarios, making it suitable for production environments that require historical message replay.
What’s Next
In the next blog, we’ll dive deeper into Advanced Routing and Message Patterns in RabbitMQ. We’ll explore complex routing setups using multiple exchanges and queues to build highly flexible and powerful message workflows. You’ll learn how to set up dynamic routing keys, multi-level bindings, and message transformations to handle real-world use cases with RabbitMQ. This will provide you with advanced tools and patterns to design resilient and scalable messaging architectures.
Stay tuned for more insights and practical guides to mastering RabbitMQ!