
Elevating Your Machine Learning Pipeline: From Development to Production: Top MLOps Best Practices for Seamless AI Deployment
Building Robust ML Pipelines: Why MLOps Matters
This listicle provides eight MLOps best practices to build robust and reliable machine learning systems. Learn how to streamline your ML workflows, improve model performance, and reduce operational overhead. Implementing these MLOps best practices is crucial for successful production ML. This article covers version control, CI/CD, feature stores, model monitoring, automated retraining, Infrastructure as Code, model serving, and collaborative workflows. By adopting these practices, you can ensure your ML projects deliver consistent value.
1. Version Control for ML Artifacts
One of the most crucial MLOps best practices is implementing robust version control for all ML artifacts. Traditional software development relies heavily on version control for code, but MLOps extends this principle to encompass models, datasets, hyperparameters, experiment configurations, and even feature definitions. This comprehensive approach ensures reproducibility, auditability, and collaboration throughout the entire machine learning lifecycle. It provides a systematic way to track changes, revert to previous states, and understand the evolution of your ML projects. Without proper versioning, reproducing past results or understanding the lineage of a deployed model becomes incredibly challenging, hindering debugging, collaboration, and compliance efforts.

Version control for ML artifacts involves meticulously tracking changes to everything that influences model training and performance. This includes: the training data used, the model’s architecture and weights, the specific hyperparameters employed, the evaluation metrics obtained, and the environment configuration itself. By capturing this information, you create a comprehensive audit trail that allows you to understand how a model evolved, reproduce previous experiments, and pinpoint the source of errors or performance regressions. This historical lineage of artifacts is critical for debugging, auditing, and ensuring the reliability of your ML pipelines. Furthermore, support for branching and merging allows for parallel experimentation and facilitates team collaboration.
Examples of Successful Implementation:
- Netflix: Uses a custom versioning system tightly integrated with their feature store to track all model artifacts, ensuring consistency and reproducibility across their vast recommendation systems.
- Uber: Their Michelangelo platform leverages comprehensive versioning for ML experiments and production models, providing a centralized system for managing the entire ML lifecycle.
- Capital One: Implements DVC (Data Version Control) and MLflow to version control datasets and model artifacts, enabling robust experimentation and model management.
Pros:
- Reproducibility: Guarantees that experiments and deployments can be recreated precisely, eliminating the “it works on my machine” problem.
- Rollback: Simplifies reverting to previous versions if issues arise with newer models or datasets.
- Compliance: Enables meeting regulatory requirements for model auditability and lineage tracking.
- Collaboration: Streamlines collaboration among data scientists and engineers by providing a shared and consistent view of the ML workflow.
Cons:
- Complexity: Managing versions of large datasets can be complex and resource-intensive.
- Specialized Tools: May require adopting tools beyond traditional Git for managing large datasets and model files.
- Storage Costs: Storing multiple versions of datasets and models can increase storage costs significantly.
- Learning Curve: Teams new to comprehensive versioning might face a learning curve in adopting new tools and workflows.
Tips for Effective Version Control:
- Use Specialized Tools: Employ tools like DVC for versioning large datasets alongside Git for code management.
- Semantic Versioning: Implement semantic versioning (major.minor.patch) for models to clearly communicate changes and compatibility.
- Metadata Tracking: Store metadata alongside artifacts to provide context and facilitate searchability.
- CI/CD Integration: Automate versioning within your Continuous Integration/Continuous Deployment (CI/CD) pipelines for seamless tracking and deployment.
Popularized By:
Tools like DVC, MLflow, Weights & Biases, and Neptune.ai have significantly advanced the practice of ML artifact versioning, offering specialized features for managing the complexities of ML workflows. Thought leaders like Jeremy Howard (fast.ai) have also championed the importance of robust version control in MLOps.
Version control for ML artifacts is an essential cornerstone of any robust MLOps strategy. Its ability to guarantee reproducibility, simplify rollback, and facilitate collaboration makes it an indispensable best practice for any organization serious about deploying and managing machine learning models effectively. By incorporating this practice, you establish a solid foundation for building reliable, scalable, and compliant ML pipelines.
2. Continuous Integration and Continuous Delivery (CI/CD) for ML
Continuous Integration and Continuous Delivery (CI/CD) for ML is a crucial MLOps best practice that extends traditional software CI/CD principles to the unique challenges of managing and deploying machine learning models. It involves automating the entire lifecycle of a machine learning model, from development and testing to deployment and monitoring. This automation ensures that models are rigorously validated, deployed quickly and reliably, and continuously improved. It addresses ML-specific concerns such as data validation, model quality assessment, and model-specific testing, which are often absent in traditional software CI/CD pipelines. This approach is essential for organizations looking to leverage the full potential of their machine learning investments and deliver high-quality AI-powered applications.
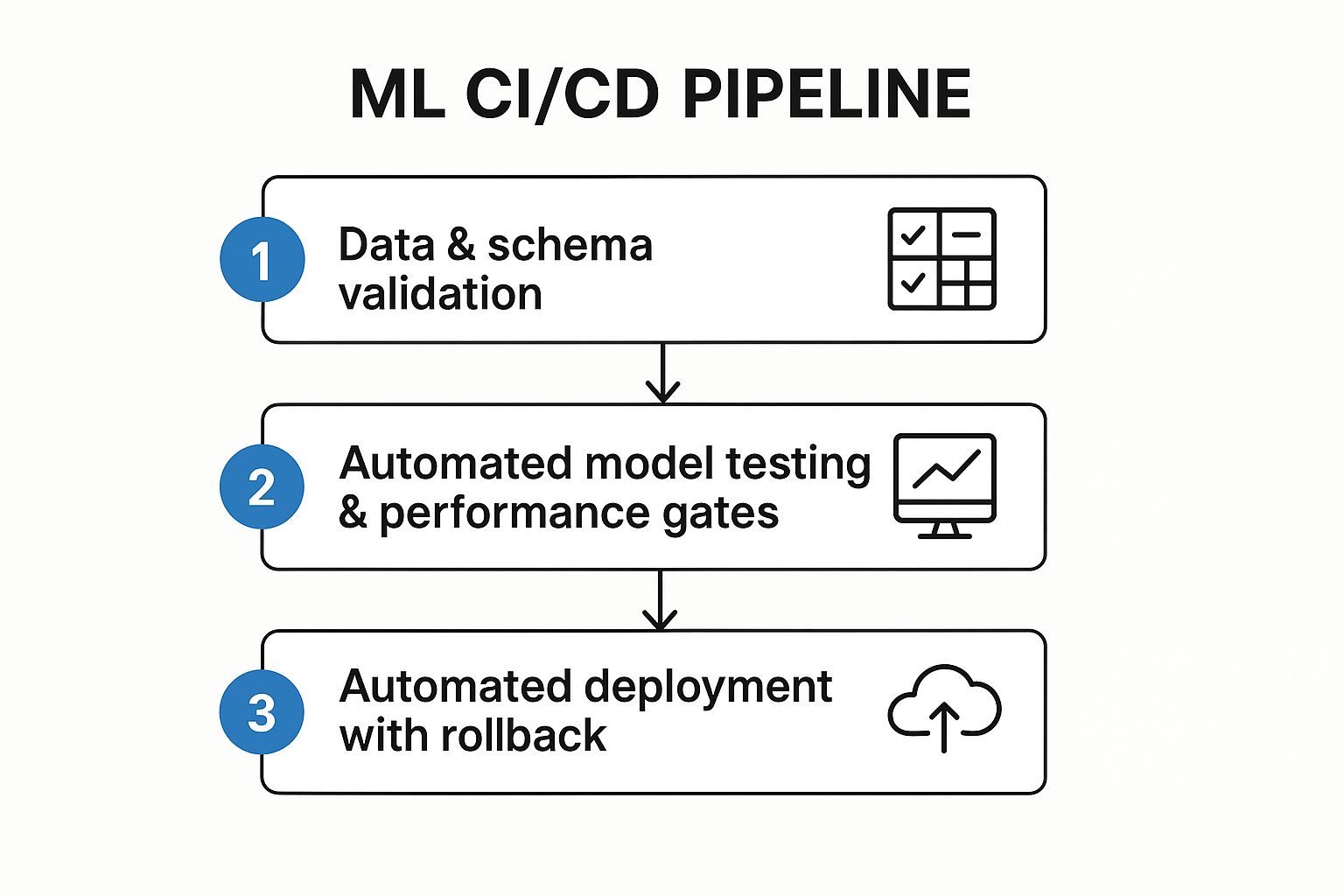
The infographic illustrates the CI/CD process for machine learning, starting with code changes and model training, progressing through various testing and validation stages, and culminating in deployment to production. Key steps highlighted include data validation, model training, model evaluation, model testing, deployment, and monitoring. The flow emphasizes the iterative nature of the process and the importance of continuous feedback loops for improvement. The sequence ensures rigorous quality checks at each step, ultimately leading to reliable and robust ML models in production.
A robust CI/CD pipeline for ML typically incorporates several key features: automated model testing and validation pipelines to evaluate performance and prevent regressions, data quality and schema validation to ensure data integrity, model performance evaluation gates to enforce minimum quality standards before deployment, automated deployment mechanisms with rollback capabilities for safe releases, and A/B testing infrastructure for controlled experimentation in production.
When and Why to Use CI/CD for ML:
CI/CD for ML is particularly valuable when:
- Deploying models frequently: If your models are updated regularly (e.g., daily or weekly), CI/CD automates the process, reducing manual effort and risk.
- Managing multiple models: CI/CD helps manage the complexity of deploying and tracking numerous models simultaneously.
- Ensuring model quality: Automated testing and validation safeguards against deploying flawed models that could negatively impact business outcomes.
- Enabling rapid experimentation: CI/CD facilitates faster iteration and testing of new model versions and algorithms.
Examples of Successful Implementation:
Companies like Google (with Vertex AI), Airbnb (using their Bighead platform), and Spotify have successfully implemented CI/CD for ML to automate model deployment and management, demonstrating its practical value in real-world scenarios. These companies deploy models multiple times per day, highlighting the efficiency gains achieved through robust CI/CD pipelines.
Pros:
- Accelerates model deployment to production
- Reduces manual errors and inconsistencies
- Ensures consistent quality checks before deployment
- Enables rapid experimentation and iteration
Cons:
- Requires upfront investment in automation infrastructure
- Higher complexity than traditional software CI/CD
- May require specialized expertise
- Potential integration challenges with legacy systems
Tips for Implementing CI/CD for ML:
- Start with simple model validation tests and gradually build more complex pipelines.
- Include both model performance metrics (e.g., accuracy, precision) and operational health checks (e.g., latency, resource utilization).
- Implement canary deployments or blue/green deployments for gradual model rollout and risk mitigation.
- Automate data drift detection as part of the pipeline to proactively identify and address changes in data distribution.
- Use containers (e.g., Docker, Kubernetes) to ensure consistency across different environments.
By adopting CI/CD for ML as a core MLOps best practice, organizations can streamline their model deployment processes, improve model quality, and accelerate the delivery of AI-powered applications. This practice is becoming increasingly important as businesses rely more heavily on machine learning to drive innovation and competitive advantage.
3. Feature Stores for ML
In the pursuit of streamlined and robust MLOps best practices, feature stores have emerged as a critical component. They address a significant challenge in the machine learning lifecycle: managing and serving features consistently across training and inference. A feature store acts as a centralized repository for storing, discovering, and serving machine learning features, enabling teams to avoid costly redundancies and ensure model accuracy. This practice contributes significantly to more efficient and reliable MLOps pipelines.

Feature stores operate by providing a single source of truth for feature definitions and their values. Data scientists and engineers can define features once, and the feature store handles the complexities of computing, storing, and serving them for both offline training and online inference. This centralization ensures consistency, preventing training-serving skew – a common issue where inconsistencies between training and serving data lead to degraded model performance in production. Furthermore, feature stores facilitate feature sharing across teams, reducing redundant feature engineering efforts and promoting collaboration. They offer tools for feature versioning, lineage tracking, and transformation pipelines, enabling efficient management and reproducibility. Features commonly include a centralized repository for feature definitions, point-in-time correctness for training data, low-latency serving for online inference, feature versioning and lineage tracking, feature computation and transformation pipelines, and access control and governance.
Several successful implementations highlight the value of feature stores. Uber’s Michelangelo feature store supports thousands of models in production, demonstrating the scalability and impact of this approach. Airbnb’s Zipline and DoorDash’s feature store showcase how feature stores maintain consistency between batch training and real-time inference, crucial for applications requiring real-time predictions. LinkedIn’s open-source feature store, Feathr, empowers the wider community to leverage the benefits of feature stores.
To effectively integrate a feature store into your MLOps workflow, consider the following tips:
- Start Small, Expand Strategically: Begin by incorporating features used by multiple models to demonstrate value and gain organizational buy-in.
- Design for Dual Access Patterns: Ensure the feature store is optimized for both offline batch access for training and low-latency online access for real-time inference.
- Prioritize Data Quality: Implement robust data quality validation for all features to ensure accuracy and reliability.
- Enable Feature Discovery: Build a discovery mechanism so data scientists can easily find and reuse existing features, reducing redundant work.
- Manage Feature Freshness: Consider the required freshness of features and design pipelines to ensure data is up-to-date.
While feature stores offer significant advantages, it’s essential to acknowledge potential drawbacks. Implementing a feature store adds complexity to the ML infrastructure stack and can become a bottleneck if not designed for scale. Achieving maximum benefit requires organizational buy-in and a commitment to adapting workflows. Operational overhead can be significant, requiring dedicated resources for maintenance and management.
Pros:
- Ensures consistency between training and serving features.
- Promotes reuse of features across different models and teams.
- Reduces feature engineering duplication.
- Simplifies online/offline feature parity.
- Enables advanced feature management (monitoring, access control).
Cons:
- Adds complexity to the ML infrastructure stack.
- Can become a bottleneck if not designed for scale.
- Requires organizational buy-in for maximum benefit.
- May have significant operational overhead.
Feature stores deserve their place in the list of MLOps best practices due to their ability to address critical challenges in feature management, ultimately leading to more robust, reliable, and efficient ML pipelines. By enabling feature consistency, promoting reusability, and streamlining workflows, feature stores empower organizations to deploy and manage machine learning models at scale effectively. Popularized by Uber (Michelangelo), Feast (open-source feature store), Tecton (commercial feature platform), LinkedIn (Feathr), and Hopsworks (Feature Store), this technology is rapidly becoming essential for organizations serious about MLOps.
4. Model Monitoring and Observability
Model monitoring and observability is a crucial MLOps best practice that encompasses tracking the performance, behavior, and overall health of machine learning models deployed in production environments. This continuous monitoring process is essential for detecting and addressing issues such as data drift, concept drift, and model degradation before they negatively impact business outcomes. It ensures your models remain reliable, accurate, and effective over time, maximizing their value and minimizing potential risks.

This practice involves continuously analyzing various aspects of the model and its surrounding environment. Real-time performance monitoring tracks key metrics like accuracy, precision, recall, and F1-score, providing insights into how well the model is performing against its intended goals. Data drift and concept drift detection mechanisms alert you to changes in the input data distribution or the relationship between input and output variables, respectively. These changes can significantly impact model performance and require intervention. Furthermore, prediction explainability and interpretability tools help understand why a model makes specific predictions, increasing transparency and trust. Input data quality monitoring ensures the data fed into the model is consistent and reliable, preventing erroneous predictions due to corrupted or unexpected input. Operational metrics such as latency, throughput, and error rates are also tracked to guarantee the model’s performance and availability in the production environment. Finally, automated alerting and notification systems promptly inform relevant stakeholders about any detected anomalies, enabling swift action and minimizing downtime.
Companies like Amazon, JPMorgan Chase, and Instacart successfully leverage model monitoring. Amazon utilizes automated monitoring to detect drift in its product recommendation models, ensuring continued relevance and accuracy. JPMorgan Chase implements monitoring for regulatory compliance in its financial models, mitigating risks and ensuring adherence to industry standards. Instacart uses performance monitoring to maintain the quality of its recommendations even during periods of high traffic and demand.
Tips for Effective Model Monitoring:
- Monitor both model outputs and input distributions: This provides a holistic view of model behavior and helps identify potential issues early on.
- Set up automated retraining triggers based on drift thresholds: Define acceptable levels of drift and automatically trigger model retraining when these thresholds are exceeded.
- Use statistical measures appropriate for your data types: Employ the right statistical tests and metrics to accurately detect drift and anomalies in your specific data.
- Start with critical models and expand monitoring coverage: Prioritize monitoring for models with the highest business impact and gradually expand coverage to other models.
- Implement both technical and business KPIs in dashboards: Track both technical performance metrics and business-related KPIs to assess the model’s overall effectiveness.
- Include explainability tools for complex models: Enhance transparency and trust by integrating explainability tools that provide insights into the model’s decision-making process.
Pros of Model Monitoring and Observability:
- Early detection of model degradation: Identify and address issues before they significantly impact business outcomes.
- Increased confidence in model reliability: Ensure consistent and accurate model performance over time.
- Improved transparency for stakeholders: Provide clear insights into model behavior and performance.
- Faster debugging and incident response: Quickly identify the root cause of issues and implement corrective actions.
- Enables compliance with regulatory requirements: Meet industry standards and regulatory obligations related to model governance and transparency.
Cons of Model Monitoring and Observability:
- Can generate significant overhead in data storage and processing: Storing and analyzing monitoring data can require substantial resources.
- Requires defining appropriate thresholds for alerts: Setting appropriate thresholds for alerts requires careful consideration and domain expertise.
- May need domain expertise to interpret certain signals: Interpreting certain monitoring signals may require specialized knowledge of the specific domain or model.
- Can be challenging to implement for complex model types: Implementing monitoring for complex models can be technically demanding.
Model monitoring and observability is an indispensable element of MLOps best practices. It ensures that your models remain performant, reliable, and compliant over time. By proactively identifying and addressing potential issues, you can maximize the value of your AI investments and minimize the risks associated with model deployment in dynamic real-world environments. Tools and platforms like WhyLabs, Arize AI, Evidently AI, Fiddler AI, Google Cloud (Model Monitoring), and Amazon SageMaker Model Monitor offer robust solutions to streamline and automate this crucial process.
5. Automated Model Retraining
Automated model retraining is a crucial MLOps best practice that ensures your machine learning models remain accurate and relevant over time. In the dynamic landscape of real-world data, patterns change, new information emerges, and model performance can degrade. This practice establishes systems for periodically or conditionally updating models, minimizing manual intervention and maximizing their predictive power. This makes it an essential component of any robust MLOps strategy.
How it Works:
Automated model retraining involves creating a pipeline that automatically triggers model training based on predefined criteria or schedules. This pipeline typically includes the following steps:
- Data Collection and Preparation: Automatically gather and preprocess the necessary data for retraining. This may involve fetching new data from databases, data lakes, or streaming sources.
- Trigger-Based or Scheduled Retraining: Retraining can be initiated based on several triggers:
- Performance Degradation: Define performance thresholds (e.g., drop in accuracy, F1-score, or AUC) that, when breached, trigger retraining.
- Data Drift: Implement data drift detection mechanisms that monitor the statistical properties of incoming data and trigger retraining when significant deviations from the training data are observed.
- Scheduled Intervals: Set up regular retraining schedules (e.g., daily, weekly, or monthly) to proactively update models.
- Hyperparameter Optimization (Optional): Automated retraining pipelines can incorporate hyperparameter optimization techniques to fine-tune model parameters during each retraining cycle, further enhancing performance.
- Champion-Challenger Model Evaluation: Evaluate the newly trained model (challenger) against the existing production model (champion) using a holdout dataset. Deploy the challenger only if it demonstrates superior performance.
- Containerized Training Environments: Utilize containerization technologies like Docker to ensure consistent and reproducible training environments across different platforms and over time.
Features and Benefits:
- Trigger-based retraining (performance thresholds, drift detection): Allows for proactive adaptation to changing data and model performance.
- Scheduled periodic retraining: Ensures regular updates even in the absence of explicit triggers.
- Automated data collection and preparation: Streamlines the retraining process by automating data ingestion and preprocessing.
- Hyperparameter optimization during retraining: Enables continuous model improvement by searching for optimal parameter settings.
- Champion-challenger model evaluation: Safeguards against deploying underperforming models.
- Containerized training environments: Promotes reproducibility and simplifies deployment.
Pros:
- Maintains model performance over time: Addresses the inherent challenge of model decay in dynamic environments.
- Reduces manual intervention for routine updates: Frees up data scientists and engineers to focus on more strategic tasks.
- Enables adaptation to changing conditions: Ensures models remain relevant and accurate as data patterns evolve.
- Creates consistent, reproducible training processes: Enhances reliability and reduces the risk of errors.
- Allows for continuous improvement cycles: Facilitates iterative model development and optimization.
Cons:
- Can be computationally expensive: Frequent retraining, especially with large datasets and complex models, can consume significant resources.
- Risk of model regression without proper validation: Improperly validated retrained models can lead to performance degradation.
- May require careful management of training data growth: Accumulating training data over time can pose storage and processing challenges.
- Challenging to implement for complex model dependencies: Integrating automated retraining with complex model pipelines can be intricate.
Examples of Successful Implementation:
- Stitch Fix: Automatically retrains recommendation models when performance drops below specified thresholds, ensuring personalized styling recommendations remain relevant.
- Twitter: Retrains content ranking models multiple times daily to adapt to rapidly changing trends and user behavior, optimizing the user experience.
- Progressive Insurance: Uses automated retraining for pricing models when market conditions shift, maintaining accurate and competitive pricing strategies.
Actionable Tips:
- Implement a shadow deployment phase: Deploy the retrained model alongside the existing model to compare their performance in a real-world setting before fully replacing the production model.
- Use incremental training when possible: Leverage existing model weights and train only on new data to reduce computational costs.
- Maintain a holdout evaluation dataset that doesn’t change: Use a consistent holdout dataset to reliably evaluate model performance across different retraining cycles.
- Create comprehensive training reports for each retrained model: Track key metrics, hyperparameters, and training data details for each retraining run to facilitate analysis and troubleshooting.
- Design for graceful failure if retraining encounters issues: Implement mechanisms to handle potential errors during the retraining process and ensure the production model remains operational.
Popularized By:
Automated model retraining is a core feature of leading MLOps platforms, including Google Cloud (Vertex AI), Amazon SageMaker, Databricks, and the Kubeflow community. Tools like MLflow also facilitate the implementation of automated retraining pipelines.
6. Infrastructure as Code (IaC) for ML
Infrastructure as Code (IaC) is a crucial MLOps best practice that addresses the challenges of managing and provisioning the complex infrastructure required for machine learning workflows. Instead of manually configuring servers, networks, and storage, IaC utilizes machine-readable definition files to automate the entire process. This approach brings significant benefits to ML teams, enabling them to create reproducible, version-controlled, and scalable environments for training, testing, and deploying ML models. This contributes directly to more robust and efficient MLOps pipelines, making it a cornerstone of any successful MLOps strategy.
How IaC for ML Works:
IaC defines infrastructure components (e.g., virtual machines, containers, networking) in code, typically using declarative configuration languages. These definitions specify the desired state of the infrastructure, and IaC tools then provision and manage the resources accordingly. This eliminates the need for manual intervention and ensures consistency across different environments. For example, an IaC script can define the type and size of a virtual machine needed for model training, the required storage capacity, and the network configuration. Once executed, the IaC tool will automatically provision the resources as specified.
Features and Benefits:
- Declarative Definition of ML Environments: Describe the desired state of the infrastructure, and the IaC tool handles the provisioning and configuration.
- Version-Controlled Infrastructure Configurations: Track changes to infrastructure definitions over time, enabling rollback to previous versions if necessary.
- Automated Provisioning of Compute Resources: Automatically allocate and deallocate resources based on demand, optimizing cost and efficiency.
- Environment Parity Across Development and Production: Minimize discrepancies between environments, reducing deployment issues and improving model reliability.
- Self-Documenting Infrastructure Requirements: The code itself serves as documentation, making it easier to understand and maintain the infrastructure.
- GPU/TPU Resource Management: Efficiently allocate and manage specialized hardware resources required for ML workloads.
Pros:
- Ensures Consistency Across Different Environments: Reduces inconsistencies that can lead to errors and delays in the ML lifecycle.
- Enables Rapid Scaling of ML Infrastructure: Quickly provision and scale resources to meet the demands of growing ML workloads.
- Simplifies Onboarding of New Team Members: New team members can easily understand and reproduce the infrastructure setup.
- Facilitates Disaster Recovery: Quickly restore infrastructure to a known good state in case of failures.
- Improves Security Through Standardized Configurations: Enforces consistent security policies across the entire infrastructure.
Cons:
- Requires Infrastructure Expertise Alongside ML Knowledge: Teams need skills in both ML and infrastructure management.
- Initial Setup Can Be Time-Consuming: Developing and testing IaC configurations can take time upfront.
- May Involve Learning Specialized IaC Tools: Familiarity with tools like Terraform or CloudFormation is required.
- Can Add Complexity for Simple Projects: IaC might be overkill for very small or simple ML projects.
Examples of Successful Implementation:
- Netflix: Uses Terraform to provision ML infrastructure across multiple cloud providers, ensuring consistency and scalability.
- Capital One: Implements CloudFormation templates for compliant ML environments, streamlining regulatory compliance.
- Lyft: Uses Kubernetes operators defined as code to manage ML workloads, automating deployment and scaling.
Actionable Tips:
- Start with Templates for Common ML Scenarios: Leverage pre-built templates to accelerate the initial setup.
- Parameterize Configurations to Enable Flexibility: Use variables to easily adapt configurations to different environments.
- Use Modules to Create Reusable Infrastructure Components: Promote code reuse and simplify complex infrastructure definitions.
- Consider Cloud-Agnostic Tools if Multi-Cloud is a Requirement: Tools like Terraform allow managing infrastructure across different cloud providers.
- Integrate IaC into CI/CD Pipelines for Infrastructure Testing: Automate the testing and validation of infrastructure changes.
Popularized By:
- HashiCorp (Terraform)
- AWS (CloudFormation)
- Pulumi
- Google (Deployment Manager)
- Microsoft (Azure Resource Manager)
By implementing IaC as an MLOps best practice, organizations can significantly improve the efficiency, reliability, and scalability of their ML workflows. It allows for a more streamlined and automated approach to infrastructure management, reducing manual effort and enabling faster iteration cycles. This is critical for organizations looking to leverage the full potential of machine learning and AI.
7. Model Serving and Deployment Strategies
Model serving and deployment strategies are a critical aspect of MLOps best practices, bridging the gap between model development and real-world impact. This practice encompasses the patterns and methodologies for effectively delivering trained machine learning models into production environments where they can generate predictions and drive business value. Choosing the right strategy significantly influences the performance, scalability, and maintainability of your AI solutions.
This process involves selecting the most suitable serving architecture, scaling approach, and deployment method based on specific model requirements and business constraints. Factors such as prediction latency, throughput needs, data volume, and available infrastructure play a crucial role in determining the optimal approach.
Several serving patterns are available, each catering to different needs:
- Batch Serving: Ideal for processing large datasets offline where low latency isn’t a priority. This pattern efficiently generates predictions on a schedule or triggered by data accumulation.
- Real-time Serving: Essential for applications demanding immediate predictions, like fraud detection or personalized recommendations. Models are deployed to respond to individual requests with minimal delay.
- Embedded Serving: Focuses on deploying models directly onto edge devices (e.g., smartphones, IoT sensors). This allows for predictions without network connectivity and minimizes latency.
Effective deployment hinges on carefully chosen strategies, ensuring smooth transitions and minimizing disruptions. Some prominent deployment strategies include:
- Canary Deployment: Introduces a new model version to a small subset of users, allowing performance evaluation and risk assessment before full rollout.
- Blue/Green Deployment: Runs two identical environments, one with the current model (blue) and one with the new model (green). Traffic is switched entirely from blue to green once testing is complete.
- Shadow Deployment: Deploys the new model alongside the existing one, mirroring production traffic but discarding the new model’s predictions. This allows for real-world performance comparison without affecting users.
Model serving and deployment often leverage various supporting technologies:
- Model Containerization and Packaging: Utilizes containerization technologies like Docker to package models and their dependencies for consistent execution across different environments.
- Serverless Inference Options: Leverages serverless platforms like AWS Lambda or Google Cloud Functions for on-demand scaling and cost efficiency, particularly suited for sporadic prediction requests.
- Hardware Acceleration: Optimizes model execution by utilizing specialized hardware like GPUs, TPUs, or FPGAs, significantly reducing latency and increasing throughput for computationally intensive models.
- Edge Deployment Capabilities: Enables model deployment to edge devices using frameworks like TensorFlow Lite or PyTorch Mobile, enabling offline functionality and real-time responsiveness.
Deploying your trained machine learning models effectively is a crucial step in the MLOps lifecycle. For a comprehensive guide on deployment strategies and best practices, refer to this resource: deploying AI models.
Pros of effectively managing Model Serving and Deployment:
- Tailored Architecture: Allows aligning the serving architecture to specific business requirements.
- Reduced Risk: Controlled deployment strategies minimize disruption and facilitate rollback in case of issues.
- Scalability: Enables dynamic scaling to handle fluctuations in prediction load.
- Performance Optimization: Supports diverse latency and throughput needs by choosing appropriate serving patterns and hardware acceleration.
- Cost Efficiency: Optimizes resource utilization and minimizes operational expenses.
Cons to consider:
- Infrastructure Complexity: Sophisticated deployment patterns may require intricate infrastructure management.
- Monitoring Challenges: Different serving patterns require tailored monitoring approaches.
- Specialized Expertise: Optimizing complex deployments may necessitate specialized skillsets.
- Operational Overhead: Introduces additional operational complexity compared to simpler model development stages.
Examples of Successful Implementation:
- PayPal: Employs both batch scoring for risk analysis and real-time serving for fraud detection.
- Waymo: Deploys models to edge devices within autonomous vehicles with robust fallback mechanisms.
- Pinterest: Leverages multi-armed bandit approaches for A/B testing and optimizing recommendation model deployments.
Actionable Tips for Implementing MLOps Best Practices in Model Serving and Deployment:
- Choose Wisely: Select the serving architecture based on latency requirements and potential for batch processing.
- Gradual Rollouts: Implement gradual rollout strategies (e.g., canary) for high-risk models.
- Edge Optimization: Consider model compilation and optimization techniques for edge or mobile deployment.
- Auto-Scaling: Utilize auto-scaling capabilities based on predicted traffic patterns.
- Versioning: Design for robust model versioning and traffic splitting capabilities.
Popular Tools and Platforms:
- TensorFlow Serving
- NVIDIA Triton Inference Server
- Seldon Core
- KServe (formerly KFServing)
- Amazon SageMaker
By adhering to these MLOps best practices for model serving and deployment, organizations can unlock the true potential of their machine learning investments, ensuring reliable, scalable, and performant AI solutions that drive tangible business outcomes.
8. Collaborative ML Development Workflows
Collaborative ML development workflows are crucial for implementing MLOps best practices and building successful machine learning projects within a team setting. These workflows establish structured processes that enable data scientists, ML engineers, domain experts, and business stakeholders to work together efficiently and effectively. This collaborative approach is essential for navigating the complexities of ML projects, which often involve iterative experimentation, model development, deployment, and monitoring. By prioritizing collaboration, teams can maximize productivity, knowledge sharing, and ultimately, the success of their ML initiatives.
This practice focuses on enabling seamless collaboration while maintaining reproducibility, facilitating knowledge transfer, and boosting overall productivity. Without a structured approach, ML projects can quickly become disorganized, leading to duplicated effort, inconsistent results, and difficulty in deploying models to production.
How Collaborative ML Development Workflows Work:
Collaborative ML workflows revolve around implementing standardized processes and leveraging tools that support collaborative development. Key components include:
- Standardized Project Templates and Structures: Using pre-defined project structures and templates ensures consistency across projects, making it easier for team members to understand and contribute to the work. This includes standardized directory structures for data, code, models, and documentation.
- Experiment Tracking and Sharing: Centralized platforms for tracking experiments, including parameters, metrics, and code versions, allow teams to share results, compare different approaches, and reproduce successful experiments. This promotes transparency and accelerates the model development process.
- Code Review Processes for ML Workflows: Implementing code review processes, similar to traditional software development, ensures code quality, improves maintainability, and facilitates knowledge sharing among team members.
- Collaborative Model Evaluation: Shared platforms and tools for evaluating models enable team members to collaboratively assess model performance, identify potential biases, and make informed decisions about model selection and deployment.
- Knowledge Management Systems: A central repository for documenting project decisions, insights, and best practices fosters knowledge sharing and reduces the risk of losing valuable information when team members leave.
- Role-Based Access Controls: Implementing appropriate access controls ensures that sensitive data and models are protected while still allowing for effective collaboration among authorized team members.
Examples of Successful Implementation:
- Spotify: Utilizes a centralized experiment tracking platform to enable cross-team collaboration and efficient sharing of experimental results.
- Booking.com: Implements notebooks with CI/CD pipelines for collaborative feature development and model deployment. This allows for seamless integration of new features and models into production systems.
- Shopify: Built structured workflows to enable product teams to effectively collaborate with central ML teams, ensuring alignment between business needs and technical implementation.
Actionable Tips for Readers:
- Implement standardized project templates with clear documentation to ensure consistency and ease of collaboration.
- Use notebook-based workflows with version control integration (e.g., Git) to track changes and facilitate collaboration on code and experiments.
- Create shared metrics and evaluation criteria to ensure consistent model assessment and comparison across the team.
- Establish regular model review sessions to discuss results, identify areas for improvement, and make collective decisions.
- Develop clear handoff processes between research and production teams to ensure smooth model deployment and ongoing monitoring.
- Document decisions and insights, not just code, to capture valuable knowledge and context for future reference.
Pros and Cons:
Pros:
- Improves productivity through standardized workflows.
- Facilitates knowledge transfer within teams.
- Reduces duplication of effort.
- Enables better decision-making through shared insights.
- Supports reproducibility of work.
Cons:
- May slow initial development with process overhead.
- Requires team buy-in to be effective.
- Can be challenging to balance flexibility with standardization.
- Different roles may have different workflow preferences.
Popularized By:
Tools like Jupyter Notebooks, Weights & Biases, Domino Data Lab, Neptune.ai, and Microsoft Azure ML have been instrumental in popularizing and enabling collaborative ML development workflows.
Why Collaborative Workflows are Essential for MLOps Best Practices:
Collaborative ML development workflows are integral to MLOps best practices because they address the inherent complexity and iterative nature of ML projects. By fostering communication, transparency, and reproducibility, these workflows enable teams to develop, deploy, and manage ML models effectively. This ultimately leads to faster iteration cycles, improved model quality, and greater business value from ML initiatives. Without these practices, organizations risk facing challenges in scaling their ML efforts and realizing the full potential of their data.
8 Key MLOps Best Practices Comparison
| Practice | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Version Control for ML Artifacts | Medium to High – specialized tools and learning | Moderate to High – storage intensive | Reproducibility, auditability, collaboration | Teams needing traceability and compliance | Ensures experiment reproducibility and rollback |
| Continuous Integration & Delivery (CI/CD) for ML | High – complex automation and integration | High – automation infrastructure needed | Faster, error-reduced deployments | Production ML with frequent updates | Accelerates deployment and enforces quality gates |
| Feature Stores for ML | Medium – requires infra and organizational alignment | Moderate – infrastructure provisioning | Feature consistency, reuse, and governance | Large teams sharing features | Ensures feature parity between training & serving |
| Model Monitoring & Observability | Medium to High – alert thresholds and expertise | Moderate – data storage and processing | Early detection of degradation, compliance | Production-critical models | Increases reliability and transparency |
| Automated Model Retraining | Medium to High – trigger mechanisms and validation | High – compute for retraining | Maintained accuracy and relevance over time | Dynamic environments with changing data | Reduces manual updates, enables continuous improvement |
| Infrastructure as Code (IaC) for ML | High – requires infra and ML domain knowledge | Moderate to High – provisioning resources | Consistent, scalable, and secure ML environments | Multi-environment ML deployments | Rapid scalable infra with version control |
| Model Serving & Deployment Strategies | Medium to High – diverse serving and deployment options | Moderate to High – serving infrastructure | Scalable, reliable, and cost-effective inference | Production at scale with varying latency | Matches serving to business needs and traffic |
| Collaborative ML Development Workflows | Medium – process setup and team adoption | Low to Moderate – collaboration tooling | Improved productivity, reproducibility, knowledge sharing | Cross-functional and multi-disciplinary teams | Standardizes workflows and facilitates knowledge transfer |
Taking Your MLOps Practices to the Next Level
This article has explored eight key MLOps best practices, from version control for machine learning artifacts and CI/CD for ML, to model monitoring and automated retraining. We’ve also examined the crucial roles of feature stores, Infrastructure as Code (IaC), strategic model serving and deployment, and collaborative ML development workflows. Mastering these core components of robust MLOps pipelines is no longer optional—it’s a necessity for organizations looking to derive real value from their machine learning investments. Effective implementation of these MLOps best practices translates directly into more reliable, scalable, and ultimately, more impactful AI solutions. By embracing these practices, you empower your teams to iterate faster, reduce deployment friction, and ensure the long-term maintainability and performance of your models. This ultimately leads to faster innovation, reduced time to market, and a greater return on investment.
The world of MLOps is constantly evolving. To stay ahead of the curve and unlock the true potential of your ML initiatives, continuous learning and adaptation are crucial. Ready to streamline your ML workflows and implement these MLOps best practices? Explore DATA-NIZANT (https://www.datanizant.com), a comprehensive platform designed to help you build, deploy, and manage your machine learning models with efficiency and confidence. DATA-NIZANT offers a wealth of resources and tools to support your MLOps journey, enabling you to achieve optimal results in 2025 and beyond.