
Introduction to RabbitMQ and Messaging Fundamentals
- Introduction to RabbitMQ and Messaging Fundamentals
- Installing RabbitMQ on macOS and Setting Up Your First Environment
- Understanding Exchanges, Queues, and Bindings in RabbitMQ with a Replay Mechanism Project
- Advanced Routing and Message Patterns in RabbitMQ: Dynamic Routing, Multi-Level Bindings, and Message Transformations
- Implementing Dead Letter Queues and Retry Mechanisms in RabbitMQ for Resilient Messaging
- Optimizing RabbitMQ Performance: Scaling, Monitoring, and Best Practices
- RabbitMQ Security Best Practices: Authentication, Authorization, and Encryption
Introduction
As modern applications shift towards microservices architectures, the need for efficient communication between services becomes critical. Each service functions independently, but the connections between them often create bottlenecks and complexities. Relying solely on synchronous request-response systems can cause delays, particularly for long-running tasks. Message brokers like RabbitMQ provide a solution, enabling asynchronous communication and efficient task distribution among services.
This blog series will explore the fundamentals of RabbitMQ and its role in supporting near real-time integration for EBX. Through illustrations and diagrams, I’ll clarify how RabbitMQ works, how it decouples applications, and how it optimizes load management.
What is RabbitMQ?
RabbitMQ is a message broker that implements the Advanced Message Queuing Protocol (AMQP). It’s often likened to a “post office” for applications, where it sits between producers (message senders) and consumers (message receivers), ensuring reliable message delivery. RabbitMQ’s smart broker/dumb consumer model places the responsibility for message handling on the broker, allowing consumers to focus solely on processing messages without worrying about routing complexities.
This diagram positions RabbitMQ at the center, receiving messages from various producers and delivering them to respective consumers. The “post office” metaphor helps visualize RabbitMQ’s role in managing message flow.
Key Components of RabbitMQ
RabbitMQ has several essential components that form the basis of its message routing and delivery system:
- Producer: The application that sends messages to RabbitMQ.
- Consumer: The application that retrieves and processes messages.
- Queue: A buffer that temporarily stores messages until they’re picked up by consumers.
- Exchange: Routes messages to queues based on rules and binding keys.
- Bindings and Routing Keys: Define how messages are directed from an exchange to the correct queue.
- Channels and Connections: Channels allow multiple threads to share a single TCP connection, optimizing resource use.
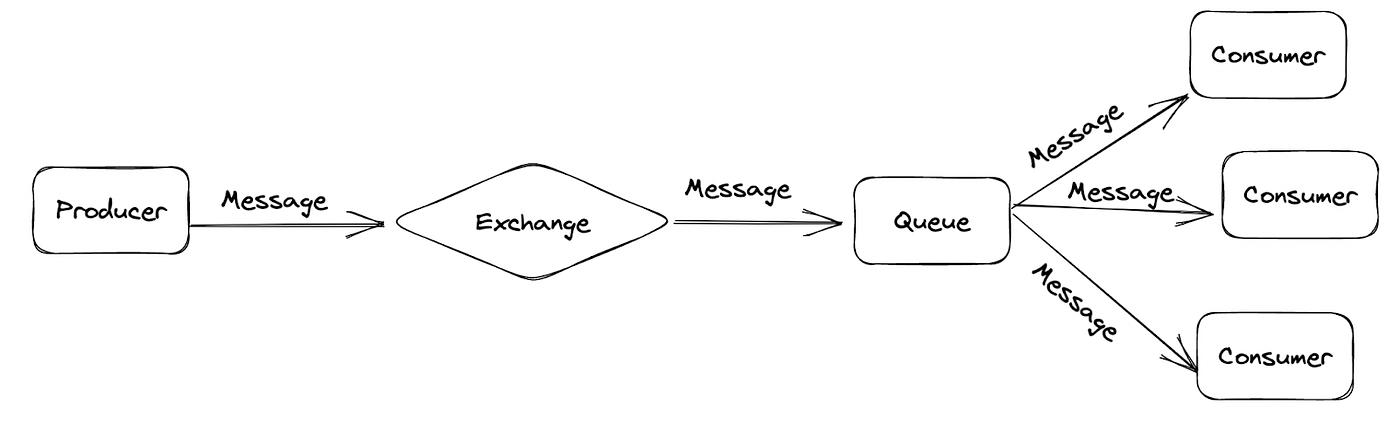
How RabbitMQ Works
RabbitMQ operates on a push model, notifying consumers immediately when a new message arrives. This low-latency approach is ideal for applications requiring fast response times. Let’s look at the typical message flow:
- The producer publishes a message to an exchange.
- The exchange routes the message to specific queues based on the routing key and bindings.
- The message waits in the queue until it’s retrieved by a consumer.
- The consumer processes the message via a channel connection to RabbitMQ.
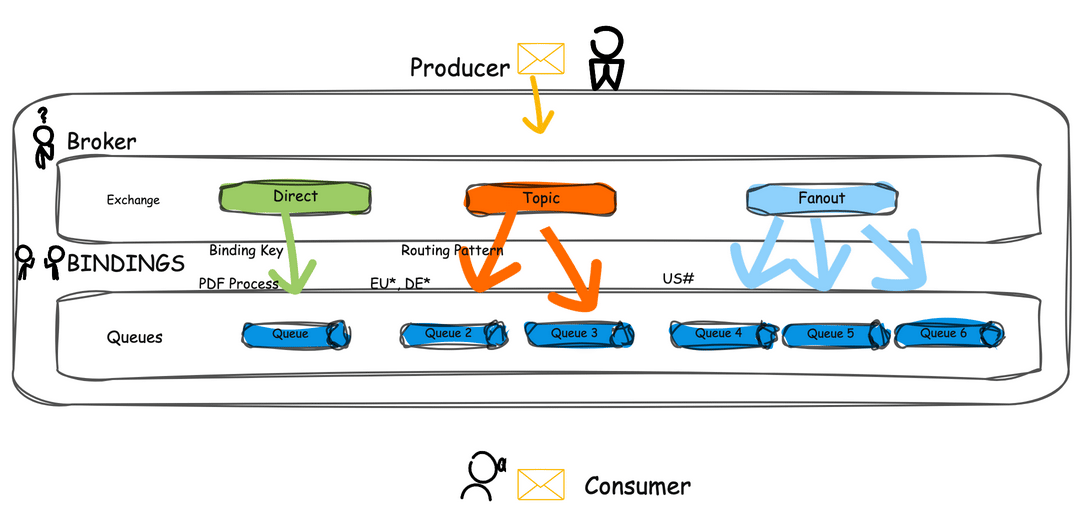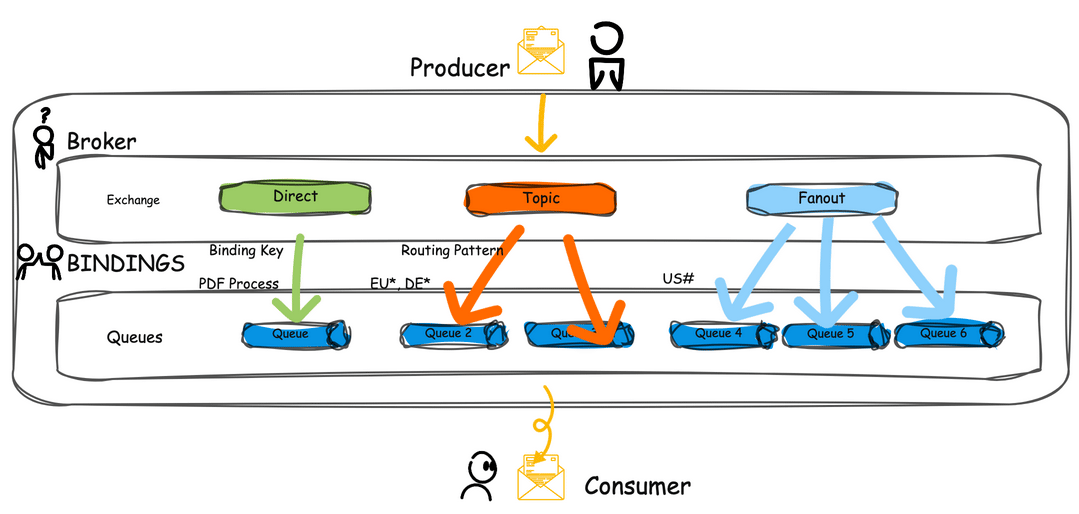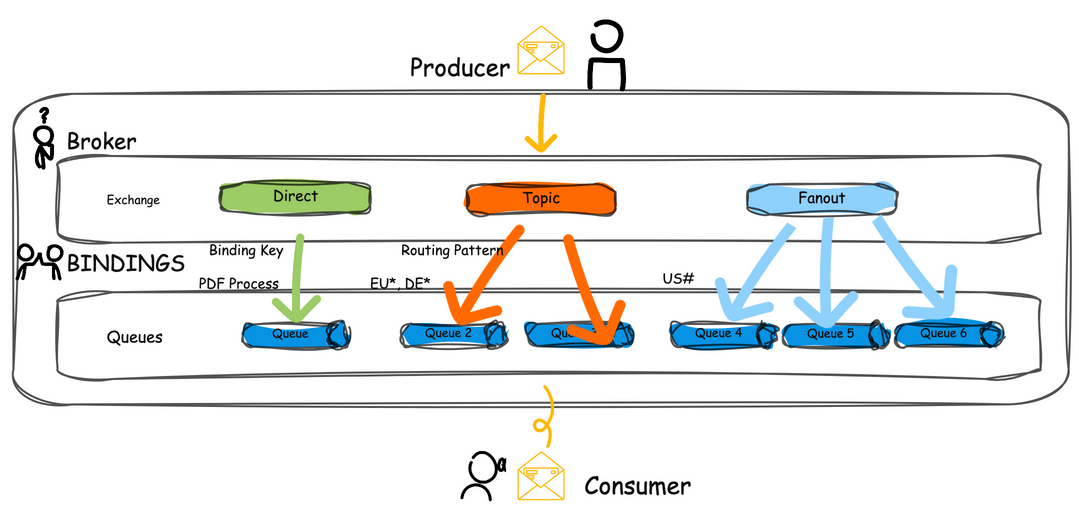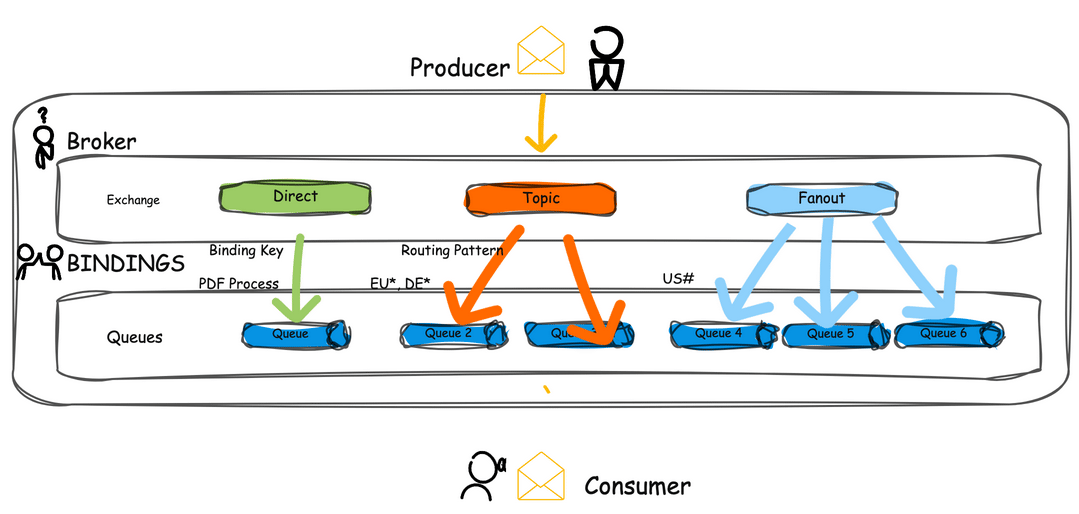
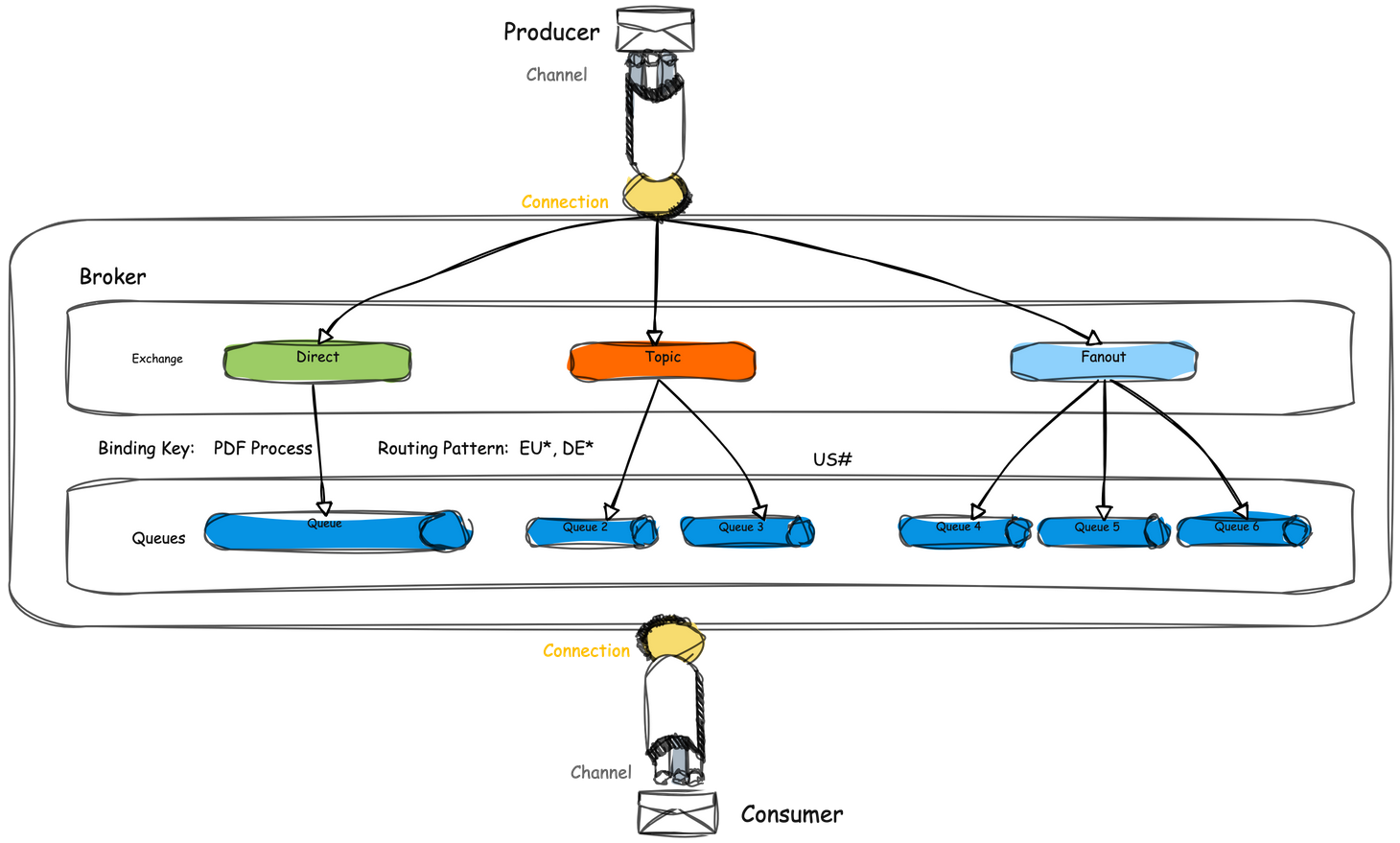
Types of Exchanges and Routing Mechanisms
RabbitMQ supports various exchange types, each offering unique ways to route messages:
- Direct Exchange: Routes messages to queues with a routing key that matches a specific binding key.
- Fanout Exchange: Broadcasts messages to all queues bound to it, ignoring the routing key.
- Topic Exchange: Routes messages based on wildcard matches between the routing key and binding pattern.
- Headers Exchange: Uses message headers for routing rather than the routing key.
When to Use RabbitMQ
RabbitMQ is ideal for scenarios that require asynchronous communication and task distribution. Two common use cases include:
- Background Processing: For long-running tasks (e.g., image processing), RabbitMQ allows these to be handled in the background, freeing up the web server for other tasks.

This flowchart illustrates how a web application (producer) queues a task in RabbitMQ for a background worker (consumer) to process, such as generating a PDF in response to user actions.
- Microservices Communication: In a microservices architecture, RabbitMQ acts as a middleman, passing messages between services to avoid bottlenecks and delays.
RabbitMQ also supports priority queues, which manage urgent tasks differently. For example, while batch jobs might wait in line, priority tasks can bypass the queue for faster processing.
Push Model vs. Pull Model
Unlike some message brokers, RabbitMQ uses a push model, where messages are actively pushed to consumers. This differs from a pull model, where consumers must poll for new messages.
RabbitMQ Cluster Setup for High Availability
RabbitMQ can run on a cluster of nodes, providing fault tolerance and high availability. By distributing queues across multiple nodes, RabbitMQ ensures that messages are available even if one node goes down.
RabbitMQ vs. Kafka: Key Differences
RabbitMQ and Kafka are often compared, but they serve different purposes:
- RabbitMQ: Designed for lightweight messaging, request-response interactions, and pub-sub patterns with short-lived messages.
- Kafka: A distributed log for high-throughput event streaming, Kafka stores messages long-term and supports message replay.
:
| Aspect | RabbitMQ | Kafka |
|---|---|---|
| Primary Use Case | Lightweight messaging, request-response, and pub-sub | High-throughput event streaming and data pipeline |
| Architecture | Message broker with smart broker/dumb consumer model | Distributed log with a partitioned, distributed, commit log model |
| Message Delivery Model | Push model (broker pushes messages to consumers) | Pull model (consumers pull messages from the log) |
| Message Storage | Short-lived, messages are removed once consumed | Persistent, messages are stored for a configurable retention time |
| Scalability | Scales vertically; limited horizontal scaling with clustering | Scales horizontally with distributed partitions |
| Latency | Low latency, ideal for real-time, low-throughput applications | Higher latency, optimized for throughput and large-scale data |
| Retention and Replay | No inherent support for message replay; transient by design | Built-in support for message retention and replay |
| Message Ordering | Not guaranteed across clusters; ordering within queues is possible | Partition-level ordering within a topic |
| Consumer Model | Competing consumers; each message goes to one consumer in a queue | Consumer groups with partition-based parallelism |
| Fault Tolerance | High availability through clustering | High fault tolerance with distributed data replication |
| Ideal Use Cases | Microservices communication, task distribution, real-time updates | Event streaming, data integration, real-time analytics |
| Protocol | AMQP (Advanced Message Queuing Protocol) | Proprietary protocol; also supports Kafka Streams and Connect API |
| Message Acknowledgment | Acknowledgments handled by broker (supports both ack/nack) | Consumers commit offsets to track message consumption |
| Developer Experience | Easier setup with many configuration options | Requires more setup but supports complex data processing workflows |
| Popular Integrations | Suitable for web servers, background tasks, and mobile apps | Ideal for data lakes, analytics, and ETL pipelines |
Conclusion
RabbitMQ is a powerful tool for building resilient, asynchronous communication in distributed systems. Its modular design, exchange types, and clustering options make it versatile for both simple and complex applications. Through this series, I’ll cover installation, advanced configurations, monitoring, and more, with practical examples for near real-time integration with EBX.
Stay tuned for the next post on Installing RabbitMQ on macOS, where we’ll set up a local RabbitMQ environment!