
Introduction: A Decade of Big Data Blogging When I began writing about Big Data in 2013, it was an exciting new frontier in data management

Welcome to an exciting new chapter in exploring the world of AI, Machine Learning (ML), and Data Science! Over the years, I have posted on
Introduction Back in 2013, I began blogging about Big Data, diving into the ways massive data volumes and new technologies were transforming industries. Over the
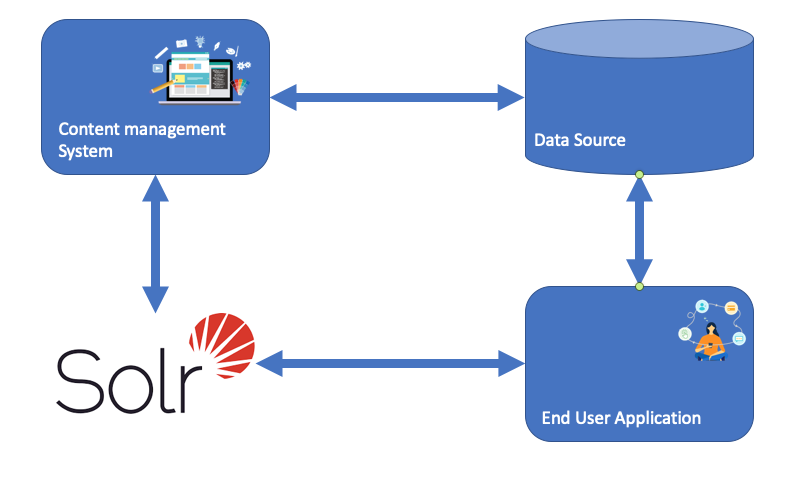
Solr is the popular, blazing-fast, open-source enterprise search platform built on Apache Lucene™. Here is a example of how Solr might be integrated into an
Elasticsearch is a search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. Elasticsearch is developed in Java. Following an open-core business model, parts of


In my recent post I tried explaining how different data collection mechanisms are available and how due to modern day requirement, modern data lakes were

Introduction: My Journey into Presto My interest in Presto was sparked in early 2021 after an enriching conversation with Brian Luisi, PreSales Manager at Starburst.

Data Lake The modern enterprise runs on data. However storing the same has always been challenging, expensive and it results in data silos. A data

In order to understand the criticality of Big Data Search, we need to understand the enormity of data. A terabyte is just over 1,000 gigabytes and
View More