
The Foundation of Successful ML: Infrastructure Essentials

Machine learning (ML) infrastructure is the essential foundation for successful AI projects. It encompasses the complete environment supporting the ML lifecycle, from initial development to final deployment and ongoing maintenance. It's a complex interplay of hardware, software, and processes, and strategic investment in this foundation is key for organizations looking to maximize their AI return on investment.
Key Components of ML Infrastructure
A successful machine learning infrastructure comprises several interconnected layers. Each layer is critical to the smooth and effective operation of the entire ML system.
-
Hardware: The physical backbone of the system. This includes powerful processors like GPUs and TPUs, specifically designed for the heavy computational demands of ML. Hardware choices have a major impact on performance, cost, and the ability to scale the system.
-
Software: The layer that drives the ML processes. This includes operating systems, libraries, and frameworks that power model development, training, and deployment. TensorFlow and PyTorch are two popular examples of ML frameworks.
-
Data Storage and Management: ML models thrive on data. Effective systems for storing and managing data are crucial. These might include data lakes and specialized databases that can handle the massive datasets used in training and inference.
-
Networking: Fast and reliable networking is essential for linking the different parts of the ML infrastructure. This is especially important for distributed training, ensuring smooth data flow and effective communication between systems.
Distinguishing ML Infrastructure From Traditional IT
While ML infrastructure shares some common ground with traditional IT, there are important differences that require a more specialized strategy. Traditional IT often prioritizes stability and cost-effectiveness. ML infrastructure, however, needs to balance these with the demanding requirements of model training and deployment.
For instance, ML workloads often demand significantly more processing power and specialized hardware than typical applications. Data management for ML involves managing and versioning enormous datasets and complex data pipelines, exceeding the capacity of standard IT data management tools. These differences directly affect development speed, model accuracy, and how reliably the system performs in a production environment.
The right infrastructure enables faster development iterations, leading to quicker model deployments and improved accuracy. A robust ML infrastructure also guarantees stable operation in production, minimizing downtime and maximizing the value of deployed models. The increasing importance of machine learning is clear in the market itself. The ML segment within the AI infrastructure market is predicted to hold a 59.1% share in the near future. This growth is driven by ML's power to analyze data and generate predictions without explicit programming.
Factors like scalable cloud computing and regulations such as HIPAA and GDPR are also contributing to this expansion. The market is expected to grow from $68.88 billion in 2024 to $94.35 billion in 2025. Learn more about this trend here. Understanding these market developments and the unique demands of ML infrastructure is vital for organizations wanting to effectively utilize the power of AI. Investing wisely in the appropriate infrastructure allows businesses to unlock the full potential of machine learning and drive significant innovation.
Hardware That Powers Innovation: Beyond Basic Computing
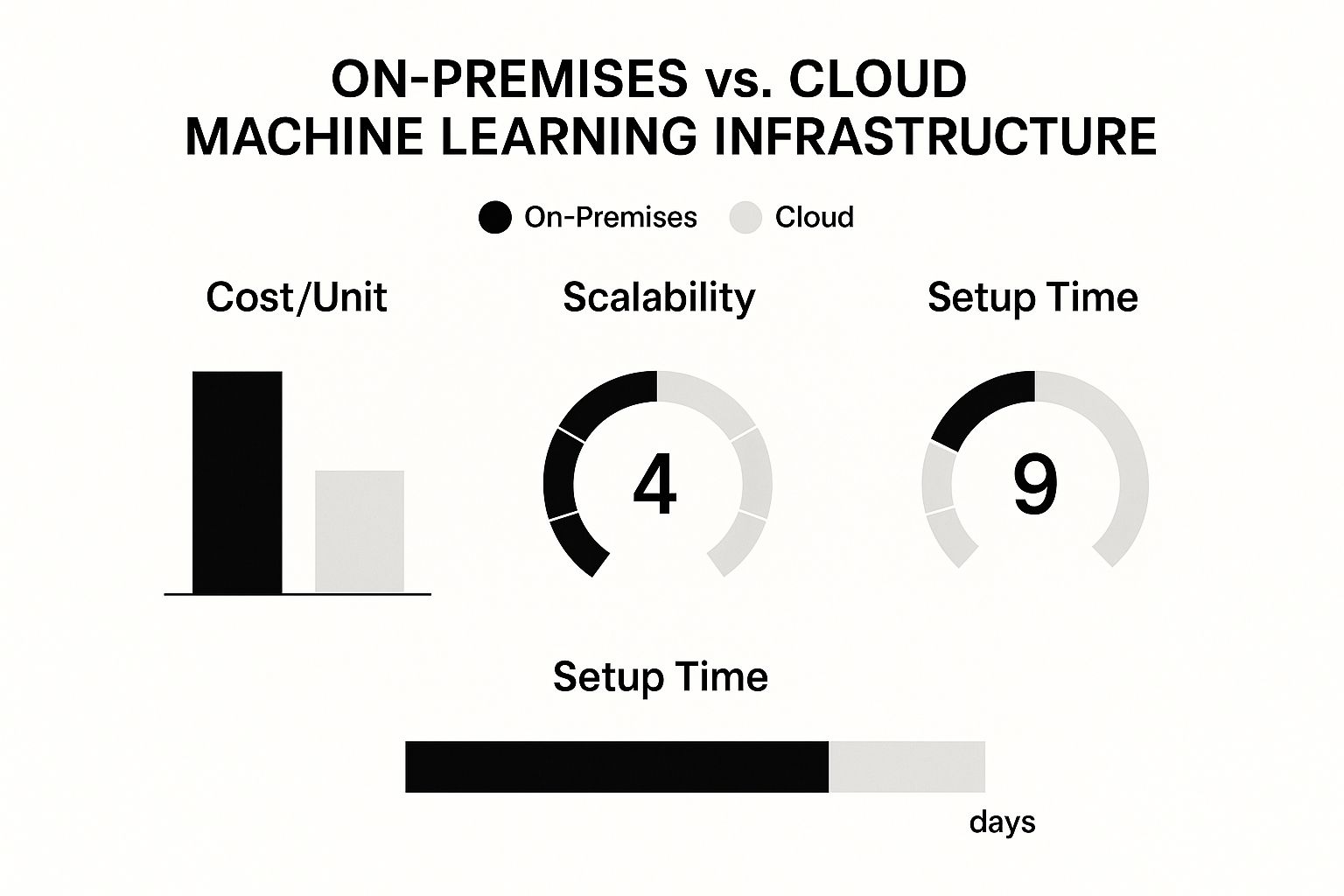
The infographic above illustrates a comparison of on-premises and cloud-based machine learning infrastructure. It focuses on key factors like cost per unit, scalability, and setup time. Cloud solutions generally offer superior scalability and faster setup. On-premises infrastructure, while often involving higher initial costs, can potentially lead to lower long-term expenses depending on usage.
Choosing the right hardware requires a careful balance between immediate project needs, long-term growth projections, and budgetary constraints. The correct hardware is fundamental to effective machine learning infrastructure. This selection process involves careful consideration of the specific requirements of your ML workloads.
Processing Power: CPUs vs. GPUs vs. TPUs
Training a large language model, for instance, demands significantly different resources compared to running inference on a smaller, pre-trained model. Understanding the strengths of different processing units is crucial for efficient infrastructure. Informed hardware choices can be the difference between a successful project and costly setbacks.
-
CPUs (Central Processing Units): CPUs excel at general-purpose computing. However, they can be less efficient for the matrix multiplications central to many machine learning algorithms. CPUs remain vital for tasks like data preprocessing and overall system management.
-
GPUs (Graphics Processing Units): Originally designed for graphics rendering, GPUs are highly effective at parallel processing. This makes them substantially faster than CPUs for many ML tasks, especially training deep learning models. This performance advantage comes at a higher cost.
-
TPUs (Tensor Processing Units): Google developed TPUs specifically for machine learning. They further optimize the operations common in neural networks, offering even greater performance than GPUs for certain workloads. However, TPUs tend to be more specialized and have limited availability.
Infrastructure Deployment Models: Cloud vs. On-Premises vs. Hybrid
Deploying your machine learning infrastructure involves another important decision: choosing the right deployment model. Each model offers distinct advantages and disadvantages.
-
Cloud-Based Infrastructure: Cloud infrastructure provides excellent scalability and flexibility. It allows for rapid deployment and resource adjustments as needed. However, ongoing cloud costs can be substantial for large projects.
-
On-Premises Infrastructure: On-premises infrastructure gives you more control over your data and its security. It can be more cost-effective over time for consistently large workloads. The initial investment and setup time, however, can be significant.
-
Hybrid Infrastructure: A hybrid approach combines the strengths of both cloud and on-premises solutions. Organizations can leverage the cloud's scalability for specific tasks while keeping sensitive data and workloads on their own servers. Managing this complexity requires careful planning and execution.
To help illustrate the hardware options available, the following table provides a comparison:
Comparison of ML Hardware Options
This table compares different hardware options for machine learning infrastructure, highlighting their strengths, limitations, and ideal use cases.
| Hardware Type | Processing Power | Cost Range | Best For | Limitations |
|---|---|---|---|---|
| CPUs | Good for general tasks, less efficient for matrix multiplication | Low to Medium | Data preprocessing, system management | Slower for deep learning training |
| GPUs | Excellent for parallel processing, faster than CPUs for ML | Medium to High | Deep learning training, large-scale ML tasks | More expensive than CPUs |
| TPUs | Highest performance for specialized neural network operations | High | Specific deep learning workloads, maximum performance | Limited availability, more specialized |
This table summarizes the key differences between CPUs, GPUs, and TPUs, along with their relative costs and ideal use cases. This information is crucial for selecting the optimal hardware for your specific ML needs.
The hardware segment is expected to see the fastest growth in the AI infrastructure market. This is due to its increased efficiency in handling processes like training AI models. Technologies like NVIDIA AI GPU-accelerated platforms, such as the Quadro and Tesla series, are crucial for AI tasks. The AI infrastructure market is projected to reach $74.06 billion in 2025 and a substantial $223.85 billion by 2029, growing at a CAGR of 31.9%. Learn more about this evolving field here.
Choosing the right machine learning infrastructure involves balancing performance requirements, budget constraints, and future scalability needs. Informed decision-making is essential for maximizing your ML initiatives and ensuring a solid return on investment.
Building Data Architecture That Powers ML Success

Effective machine learning models depend significantly on the underlying data architecture. This section explores how organizations construct data systems that thrive in real-world production settings. We'll delve into practical strategies for data storage, processing, and management, all of which contribute to machine learning success.
Data Storage Solutions For ML
Selecting the appropriate data storage solution is paramount. Various options exist, each with advantages and disadvantages that influence ML workloads. The optimal choice hinges on factors such as data volume, access patterns, and performance requirements.
-
Data Lakes: Data lakes offer a centralized repository for storing raw data in diverse formats. This flexibility makes them suitable for exploratory data analysis and supporting various ML tasks. However, without proper management and governance, data lakes can become difficult to manage.
-
Specialized Databases: Purpose-built databases optimized for machine learning workloads are gaining traction. These databases provide features like enhanced query performance and inherent support for vector embeddings. This boosts efficiency for tasks like similarity search and recommendation systems.
-
Hybrid Solutions: Many organizations embrace a hybrid strategy. This frequently involves combining a data lake for storing raw data with specialized databases for serving specific ML applications. This approach balances flexibility and performance.
Data Pipelines and Versioning
Constructing robust data pipelines is essential for delivering consistent, high-quality data to machine learning models. These pipelines automate data ingestion, transformation, and validation.
Data versioning, similar to code version control, allows you to monitor changes to your datasets. This ensures reproducibility and helps prevent errors by enabling you to revert to previous versions if needed. Well-designed pipelines are crucial for managing both batch processing and real-time data streams using tools like Apache Kafka.
Metadata Management and Data Discovery
Metadata, essentially data about data, plays a vital role in machine learning infrastructure. Effective metadata management enables data scientists and engineers to discover and comprehend relevant data. This understanding is critical for building and deploying effective models. Well-maintained metadata catalogs serve as valuable repositories of institutional knowledge.
This architectural component facilitates smooth transitions from development to production. It allows data scientists and engineers to collaborate more effectively, minimizing friction and maximizing shared understanding. This seamless workflow promotes quicker iteration cycles and enhanced model performance. Efficient data architecture is the cornerstone of successful machine learning. It empowers the entire ML lifecycle, enabling organizations to derive meaningful insights from their data and develop high-performing models.
Creating Development Environments That Amplify ML Teams
Building a productive machine learning infrastructure means creating an environment where your ML teams can flourish. A well-designed development environment is essential for quickly transitioning from initial experiments to robust, reproducible results. This involves providing the right tools and workflows to accelerate the entire ML lifecycle.
Containerization: Solving the "Works on My Machine" Problem
A frequent hurdle in ML development is maintaining consistency across different environments. Code that functions perfectly on one developer's machine might encounter issues on another due to differences in software versions, libraries, or dependencies. Containerization tackles this "works on my machine" problem by bundling the code, runtime, system tools, libraries, and settings into isolated units called containers.
- Reproducibility: Containers guarantee consistent execution across various development, testing, and production environments.
- Isolation: Containers isolate dependencies, preventing conflicts and ensuring reliable operation.
- Portability: Containers can be easily transferred between different platforms and cloud providers.
Tools like Docker are commonly used for creating and managing containers, simplifying the process of building portable and reproducible ML environments. This consistency is especially vital as models progress to production.
Orchestration: Efficient Resource Management
As ML projects scale, managing multiple containers and their resources becomes increasingly complicated. Container orchestration platforms like Kubernetes automate the deployment, scaling, and management of containers. This significantly lightens the operational load on ML teams.
For instance, Kubernetes can automatically allocate resources to containers based on demand, optimizing hardware utilization. This automation eliminates the need for manual intervention, allowing ML engineers to concentrate on model development and refinement. This efficiency is particularly crucial for demanding tasks like training large language models.
Collaboration and Experiment Tracking
Effective collaboration is key for successful ML teams. Shared code repositories, version control systems (like Git), and collaboration platforms enhance teamwork. These tools enable team members to share code, track changes, and efficiently resolve conflicts.
In addition, experiment tracking tools help manage the many iterations and experiments involved in ML model development. These tools record parameters, metrics, and results, enabling teams to compare different approaches. This structured approach ensures experiments are reproducible and simplifies collaboration.
To further elaborate on the essential building blocks of a robust ML training environment, let's delve into the following table. It provides a breakdown of the key components, their roles, implementation choices, and important considerations.
ML Training Environment Components
This table outlines the essential components required for building effective machine learning training environments, their functions, and implementation considerations.
| Component | Function | Implementation Options | Key Considerations |
|---|---|---|---|
| Compute Resources | Provide processing power for training and inference | Cloud VMs, on-premises servers, containerized environments | Scalability, cost, performance requirements |
| Storage | Store training data, model checkpoints, and other artifacts | Cloud storage, on-premises storage, specialized databases | Data volume, access patterns, data versioning |
| Development Environment | Facilitate model development and experimentation | Jupyter notebooks, IDEs, containerized environments | Reproducibility, collaboration features, integration with other tools |
| Experiment Tracking | Log and manage experiments, track metrics and parameters | MLflow, Weights & Biases, custom solutions | Ease of use, integration with existing workflows, visualization capabilities |
| Model Versioning | Track different versions of models and their associated metadata | DVC, Git LFS | Reproducibility, model lineage, deployment management |
This table highlights the diverse components and considerations necessary for a successful ML training environment. From compute resources and storage to experiment tracking and model versioning, each element plays a crucial role.
By implementing containerization, orchestration, collaboration tools, and experiment tracking, organizations create ML infrastructure that allows teams to prioritize what truly matters: building innovative and impactful machine learning models. This approach ensures efficient resource use, simplifies workflows, and cultivates a collaborative environment, accelerating the journey from research to production.
Taking Models From Laptops to Production: Deployment Done Right

Deploying machine learning models is the critical link between research and practical application. A model's true value lies in its ability to serve predictions in a live environment, not just perform well in a development setting. This section explores the key considerations for moving models from development to production systems. This transition often presents significant hurdles, particularly with increasingly complex and large-scale models.
Architectural Patterns for Reliable Model Serving
Selecting the right architecture is paramount for robust model deployment. Different architectures cater to varying needs and scaling requirements.
-
Cloud-Native Deployments: Cloud platforms like AWS or Azure offer managed services that streamline model deployment and scaling. These services often handle the complexities of infrastructure management, freeing up machine learning engineers to concentrate on model performance.
-
Edge Deployments: Deploying models on edge devices, closer to the data source, minimizes latency and empowers real-time applications. This is particularly important for applications sensitive to network delays, such as self-driving cars or industrial Internet of Things (IoT) deployments.
-
On-Premises Deployments: Some organizations choose on-premises deployments for greater security and data control. While offering more control, this approach typically requires more substantial investment in infrastructure and upkeep.
When transitioning models to production, it's important to evaluate the advantages and disadvantages of specific solutions, such as Company-Specific GPTs.
Managing the Deployment Lifecycle
Model deployment is not a one-off task; it's a continuous cycle. Effective lifecycle management is essential for sustained success.
-
Model Versioning: Tracking different model versions is crucial for reproducibility and rollback options. This allows for quick reversion to a prior version if a new model encounters unexpected problems in production.
-
Traffic Management: During updates, managing traffic flow between model versions ensures a seamless transition. Techniques like A/B testing enable performance comparison of different models in a live environment.
-
Monitoring and Alerting: Continuous monitoring of model performance and resource utilization is essential for early issue detection. Robust alerting systems notify engineers of critical problems before they affect end-users, minimizing downtime and ensuring system reliability.
Optimizing Inference Performance
Optimizing the speed and efficiency of model predictions, or inference, is vital for numerous applications.
-
Hardware Acceleration: Leveraging specialized hardware, such as GPUs or TPUs, substantially accelerates inference, particularly for computationally demanding models.
-
Model Quantization: This technique reduces the precision of model parameters, often resulting in smaller model sizes and faster inference without significantly compromising accuracy.
The market itself highlights the increasing importance of machine learning infrastructure. The U.S. AI infrastructure market, valued at $14.52 billion in 2024, is projected to reach $156.45 billion by 2034, demonstrating a CAGR of 26.84%. Globally, the market is expected to reach about $499.33 billion by 2034, with a CAGR of 26.60% from 2025 to 2034. This growth reflects the rising awareness of AI's potential to enhance productivity and competitiveness across various sectors. For more detailed statistics, visit: https://www.precedenceresearch.com/artificial-intelligence-infrastructure-market.
By carefully addressing these aspects of machine learning infrastructure, organizations can ensure their models perform effectively not only in development but also deliver consistent value in real-world scenarios.
Seeing the Invisible: ML Monitoring That Actually Works
Traditional system monitoring just doesn't cut it for the complexities of machine learning infrastructure. Machine learning systems bring their own set of unique challenges that demand specialized monitoring techniques. This section explores how effective monitoring empowers high-performing ML teams to maintain control and visibility over their entire ML pipeline. Through comprehensive observability, teams can proactively address issues, ensuring reliable performance and minimizing disruptions.
Combining Technical and Business Metrics
Leading organizations know that effective ML monitoring means more than just watching technical metrics. It requires measuring the real-world business impact of the ML system. For example, a small dip in model accuracy might not raise technical red flags, but it could mean a significant revenue loss for a business relying on that model for personalized recommendations.
By connecting technical metrics like latency and error rates with business-focused key performance indicators (KPIs), organizations get a complete picture of their ML system's health. This integrated approach guarantees monitoring efforts directly support business objectives.
Monitoring Key Aspects of ML Systems
Several critical parts of machine learning systems need constant monitoring. Keeping an eye on these areas allows for proactive identification and remediation of potential problems.
-
Data Drift: Shifts in incoming data distribution can severely impact model performance. Regularly checking for data drift is crucial for keeping model accuracy high over time. Imagine a model trained to predict customer churn using historical data. It could become less accurate if customer behavior suddenly changes due to outside factors.
-
Model Performance Degradation: Model performance can decrease over time, even with stable data. Tracking key metrics like precision, recall, and F1-score allows teams to catch and fix performance declines before they impact users.
-
Resource Utilization: Machine learning workloads can be resource-intensive. Monitoring CPU and memory usage, along with storage capacity, is key for efficient infrastructure management and cost control. This ensures the system stays within its resource limits.
Building Actionable Alerting and Dashboards
Effective monitoring depends on clear, actionable alerts and informative dashboards. Alert systems should minimize false alarms while reliably catching real problems. When moving models from development to production, it’s essential to consider different deployment options. Dashboards should present concise, actionable insights, avoiding overwhelming users with raw data. This empowers teams to quickly diagnose and resolve problems.
Automating Monitoring and Response
Automation makes ML monitoring even more powerful. Automated processes can gather metrics, analyze data, and even trigger corrective actions, such as retraining a model when performance dips below a set threshold. This automation lightens the operational load on ML teams and increases system reliability. By proactively addressing potential problems, automated systems minimize downtime and maintain consistent model performance. These automated responses might include scaling resources to handle increased demand or triggering alerts for human intervention when needed. Through these combined approaches, organizations can build a robust and efficient monitoring strategy for their machine learning infrastructure. This not only ensures the system's technical performance, but also maximizes its contribution to business goals.
Securing Your ML Infrastructure: Governance That Enables
As machine learning systems become more central to handling sensitive data and critical business operations, security is paramount. This section explores how organizations are establishing robust governance frameworks to protect their machine learning infrastructure while still encouraging innovation. These frameworks need to address the specific security challenges that arise from the complexity of ML systems.
Access Control and Data Security
Effective security begins with controlling access. Implementing granular access control mechanisms is crucial for protecting sensitive data and preventing unauthorized modifications to models or infrastructure. This involves defining roles and permissions based on the principle of least privilege, meaning users are granted only the access they require for their specific tasks.
Data security is also essential within any ML infrastructure. Data encryption, both in transit and at rest, safeguards data confidentiality. Techniques like data anonymization and pseudonymization can further reduce privacy risks while maintaining data utility for model training and validation.
Model Security: Protecting Against Attacks
Model security centers on protecting ML models from attacks aimed at manipulating their behavior or extracting sensitive training data. For instance, adversarial attacks involve subtly changing input data to cause incorrect classifications or other undesirable results. Model poisoning attacks, on the other hand, seek to compromise the training data itself, introducing vulnerabilities into the model.
Protecting against these attacks necessitates robust security measures, such as input validation and anomaly detection. Regular model audits and vulnerability scanning are also vital for identifying and addressing potential weaknesses.
Regulatory Compliance and Audit Logging
Compliance with regulations like GDPR, HIPAA, or other industry-specific standards is crucial when dealing with sensitive data. Machine learning infrastructure must support these requirements through appropriate security controls and robust audit logging capabilities.
Comprehensive audit logging creates a record of system activities, tracking data access, model changes, and other key events. This promotes accountability, facilitates compliance audits, and assists in investigations if security incidents occur. Clear audit trails are fundamental for understanding system behavior and effectively addressing potential issues.
Implementing Security Throughout the ML Pipeline
Security must be embedded throughout the entire ML pipeline, from data ingestion to model deployment and ongoing monitoring. This includes:
- Securing Data Ingestion: Safeguarding data sources and ensuring the integrity of incoming data is paramount.
- Secure Model Training: Implementing access controls and monitoring for any unusual activity during the training process.
- Securing Model Deployment: Restricting access to deployed models and protecting them from unauthorized changes.
- Secure Monitoring and Logging: Protecting monitoring data and ensuring the integrity of audit logs.
Balancing Security and Innovation
While strong security is critical, it’s also essential to avoid stifling innovation. Governance frameworks should strike a balance between security and the flexibility required for rapid experimentation and iteration within the ML development lifecycle. This might involve incorporating automated security checks and controls into the development workflow.
For example, integrating security testing within a continuous integration and continuous delivery (CI/CD) pipeline helps identify and address vulnerabilities early on. This proactive approach can prevent minor security issues from escalating into significant problems. By adopting these best practices, organizations can ensure the long-term success and reliability of their machine learning initiatives, fostering a culture of security across the ML development lifecycle.
Want to delve deeper into building and scaling robust machine learning infrastructure? Visit DATA-NIZANT for detailed articles, expert insights, and practical guidance.




