
Advanced Apache Pinot: Sample Project and Industry Use Cases
- Apache Pinot Series Summary: Real-Time Analytics for Modern Business Needs
- Advanced Apache Pinot: Custom Aggregations, Transformations, and Real-Time Enrichment
- Apache Pinot for Production: Deployment and Integration with Apache Iceberg
- Advanced Apache Pinot: Optimizing Performance and Querying with Enhanced Project Setup
- Advanced Apache Pinot: Sample Project and Industry Use Cases
- Pinot™ Basics
As we dive deeper into Apache Pinot, this post will guide you through setting up a sample project. This hands-on project aims to demonstrate Pinot’s real-time data ingestion and query capabilities and provide insights into its application in industry scenarios. Whether you’re looking to power recommendation engines, enhance user analytics, or build custom BI dashboards, this blog will help you establish a foundation with Apache Pinot.
Introduction to the Sample Project
The sample project will simulate a real-time analytics dashboard for a social media application. We’ll analyze user interactions in near-real-time, covering a setup from data ingestion through to visualization.
Project Structure:
data: Contains sample data files for bulk ingestion.ingestion: Configuration for real-time data ingestion via a Kafka stream.config: JSON/YAML configuration files for schema and table definitions in Pinot.scripts: Shell scripts for setting up the Pinot cluster and loading data.visualization: Dashboard setup files for BI tool integration, e.g., Superset.
Architecture Overview of the Sample Project
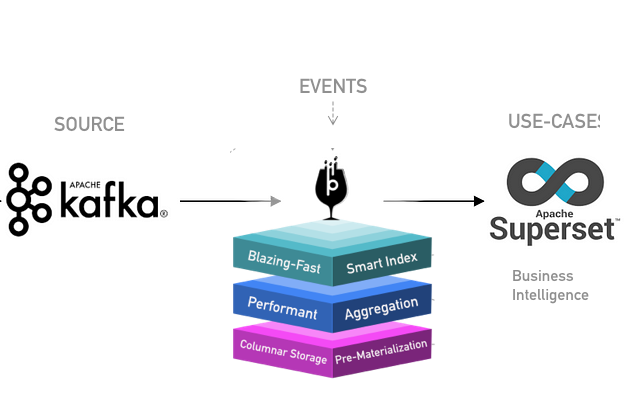
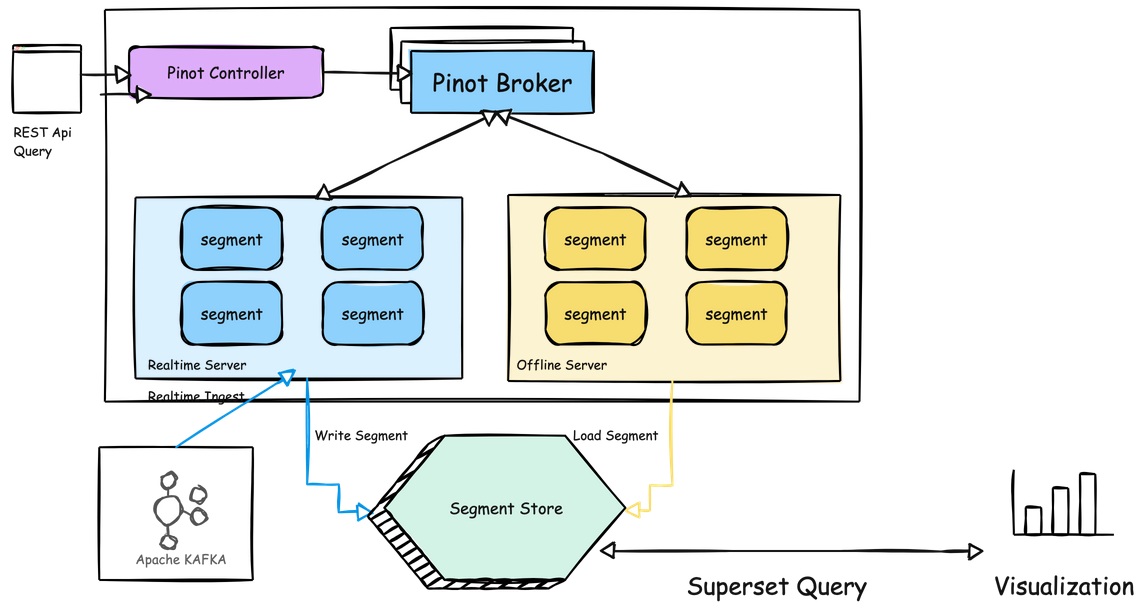
To give you a visual understanding of how components interact in this setup, here’s an architecture diagram showcasing data ingestion, storage, and querying in Apache Pinot.
Diagram: Architecture of Real-Time Analytics with Apache Pinot
- Kafka: Receives real-time events from simulated user interactions.
- Pinot Ingestion: Configured with real-time ingestion settings to pull data directly from the Kafka stream.
- Pinot Storage: Organizes incoming data in segments, stored in a columnar format to enable high-speed analytics.
- Superset: Connects to Pinot as the analytics and visualization layer.
Data Flow in Apache Pinot: From Ingestion to Querying
Let’s break down the data flow, highlighting how a user interaction (e.g., a post like) becomes actionable insight in near-real-time.
1. Data Generation
- User interactions (like clicks, views, likes, etc.) are sent as events to Kafka. These events are structured as JSON payloads containing fields such as
user_id,post_id,likes, andtimestamp.
2. Ingestion into Pinot
- Kafka to Pinot: Pinot’s stream ingestion process is configured to read events directly from the
social_media_eventstopic in Kafka. Each event is parsed, indexed, and stored in columnar segments. - Segment Management: Pinot automatically manages segment creation and optimizes data for query performance.
3. Real-Time Querying
- Query Layer (Broker): Superset sends SQL queries to Pinot’s broker, which directs them to the appropriate servers.
- Aggregation and Filtering: The servers perform filtering and aggregation operations on the segments, leveraging Pinot’s indexing capabilities to ensure low latency.
- Result Delivery: Query results are returned to Superset, where they are visualized in real-time.
Setting Up Your Environment
If you followed the setup in Pinot Basics, you should already have a local Pinot instance running. Now, we’ll extend this setup to ingest real-time data using Kafka and visualize it with Superset.
1. Define the Data Schema
We’ll be working with a simplified schema for tracking social media metrics. This schema will include fields like user_id, post_id, likes, shares, timestamp, and geo_location.
Create a social_media_schema.json file in the config folder:
2. Configure the Table in Pinot
Next, create a social_media_table.json file in the config directory to define the table and ingestion type (in this case, REALTIME).
3. Ingest Data with Kafka
For real-time ingestion, we’ll simulate data streaming through a Kafka topic. You can set up a Kafka producer to publish events to the social_media_events topic. Use a simple Python script to simulate the event stream.
4. Deploy and Verify the Pinot Table
With Pinot running, deploy the social_media table by uploading the schema and table configurations:
Confirm data ingestion by querying the Pinot console:
Visualizing the Data in Superset
Pinot integrates seamlessly with Superset, allowing us to create interactive dashboards.
- Configure the Pinot Connection in Superset, as shown in the previous blog.
- Create a Dashboard with metrics like total likes, shares, and active users over time.
This visual dashboard allows you to track real-time user engagement on the platform.
Industry Scenarios and Use Cases
Apache Pinot is a great fit for applications that need high-throughput, low-latency analytics. A few scenarios include:
- User Engagement Analytics: Real-time insights on user interactions for social media, gaming, and streaming platforms.
- Anomaly Detection: Monitoring financial transactions or system logs for unusual patterns.
- Log Analysis and Monitoring: Centralized log aggregation and query for IT operations.
Conclusion
In this blog, we covered a comprehensive setup for a sample project with Pinot, from schema configuration to real-time data ingestion with Kafka. With these skills, you can explore broader applications of Pinot in industry scenarios where real-time analytics are critical.
Stay tuned for the next post, where we’ll go deeper into optimizing queries and managing Pinot clusters.